 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Architectures for Language Models: Systematic Analysis and Design Insights
Oct 06, 2025Recent progress in large language models demonstrates that hybrid architectures--combining self-attention mechanisms with structured state space models like Mamba--can achieve a compelling balance between modeling quality and computational efficiency, particularly for long-context tasks. While these hybrid models show promising performance, systematic comparisons of hybridization strategies and analyses on the key factors behind their effectiveness have not been clearly shared to the community. In this work, we present a holistic evaluation of hybrid architectures based on inter-layer (sequential) or intra-layer (parallel) fusion. We evaluate these designs from a variety of perspectives: language modeling performance, long-context capabilities, scaling analysis, and training and inference efficiency. By investigating the core characteristics of their computational primitive, we identify the most critical elements for each hybridization strategy and further propose optimal design recipes for both hybrid models. Our comprehensive analysis provides practical guidance and valuable insights for developing hybrid language models, facilitating the optimization of architectural configurations.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
Automated Filtering of Human Feedback Data for Aligning Text-to-Image Diffusion Models
Oct 14, 2024



Fine-tuning text-to-image diffusion models with human feedback is an effective method for aligning model behavior with human intentions. However, this alignment process often suffers from slow convergence due to the large size and noise present in human feedback datasets. In this work, we propose FiFA, a novel automated data filtering algorithm designed to enhance the fine-tuning of diffusion models using human feedback datasets with direct preference optimization (DPO). Specifically, our approach selects data by solving an optimization problem to maximize three components: preference margin, text quality, and text diversity. The concept of preference margin is used to identify samples that contain high informational value to address the noisy nature of feedback dataset, which is calculated using a proxy reward model. Additionally, we incorporate text quality, assessed by large language models to prevent harmful contents, and consider text diversity through a k-nearest neighbor entropy estimator to improve generalization. Finally, we integrate all these components into an optimization process, with approximating the solution by assigning importance score to each data pair and selecting the most important ones. As a result, our method efficiently filters data automatically, without the need for manual intervention, and can be applied to any large-scale dataset. Experimental results show that FiFA significantly enhances training stability and achieves better performance, being preferred by humans 17% more, while using less than 0.5% of the full data and thus 1% of the GPU hours compared to utilizing full human feedback datasets.
Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL
Jul 20, 2024With the advent of foundation models, prompt tuning has positioned itself as an important technique for directing model behaviors and eliciting desired responses. Prompt tuning regards selecting appropriate keywords included into the input, thereby adapting to the downstream task without adjusting or fine-tuning the model parameters. There is a wide range of work in prompt tuning, from approaches that directly harness the backpropagated gradient signals from the model, to those employing black-box optimization such as reinforcement learning (RL) methods. Our primary focus is on RLPrompt, which aims to find optimal prompt tokens leveraging soft Q-learning. While the results show promise, we have observed that the prompts frequently appear unnatural, which impedes their interpretability. We address this limitation by using sparse Tsallis entropy regularization, a principled approach to filtering out unlikely tokens from consideration. We extensively evaluate our approach across various tasks, including few-shot text classification, unsupervised text style transfer, and textual inversion from images. The results indicate a notable improvement over baselines, highlighting the efficacy of our approach in addressing the challenges of prompt tuning. Moreover, we show that the prompts discovered using our method are more natural and interpretable compared to those from other baselines.
Learning Video Temporal Dynamics with Cross-Modal Attention for Robust Audio-Visual Speech Recognition
Jul 04, 2024



Audio-visual speech recognition (AVSR) aims to transcribe human speech using both audio and video modalities. In practical environments with noise-corrupted audio, the role of video information becomes crucial. However, prior works have primarily focused on enhancing audio features in AVSR, overlooking the importance of video features. In this study, we strengthen the video features by learning three temporal dynamics in video data: context order, playback direction, and the speed of video frames. Cross-modal attention modules are introduced to enrich video features with audio information so that speech variability can be taken into account when training on the video temporal dynamics. Based on our approach, we achieve the state-of-the-art performance on the LRS2 and LRS3 AVSR benchmarks for the noise-dominant settings. Our approach excels in scenarios especially for babble and speech noise, indicating the ability to distinguish the speech signal that should be recognized from lip movements in the video modality. We support the validity of our methodology by offering the ablation experiments for the temporal dynamics losses and the cross-modal attention architecture design.
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Jun 04, 2024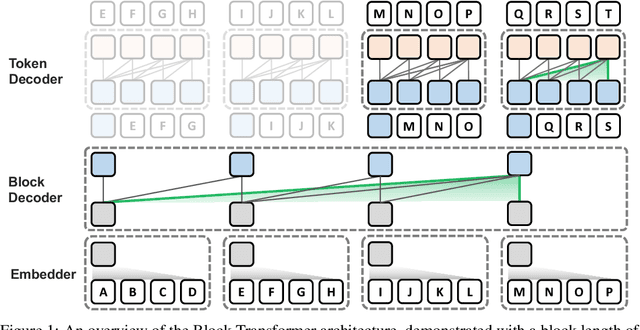
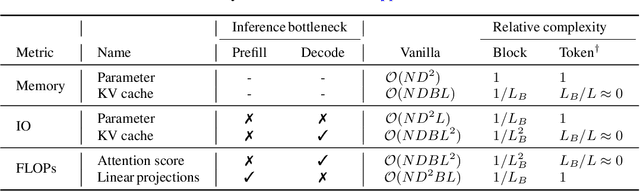
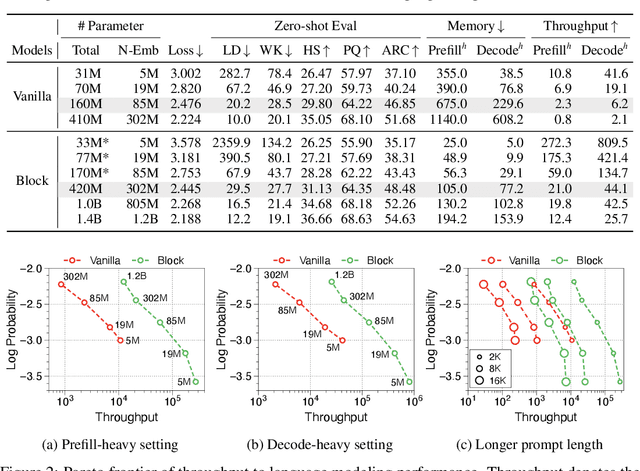
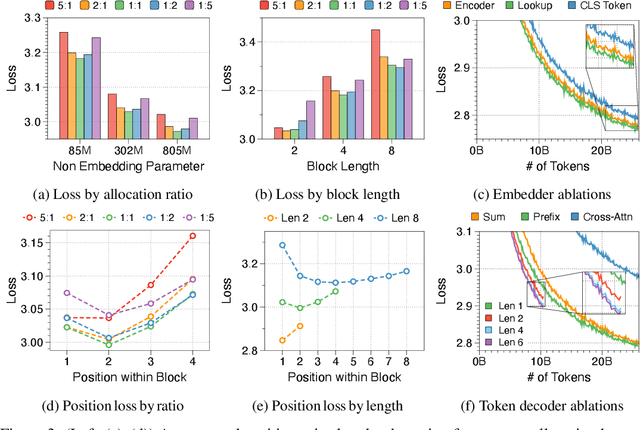
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.
Why In-Context Learning Transformers are Tabular Data Classifiers
May 22, 2024The recently introduced TabPFN pretrains an In-Context Learning (ICL) transformer on synthetic data to perform tabular data classification. As synthetic data does not share features or labels with real-world data, the underlying mechanism that contributes to the success of this method remains unclear. This study provides an explanation by demonstrating that ICL-transformers acquire the ability to create complex decision boundaries during pretraining. To validate our claim, we develop a novel forest dataset generator which creates datasets that are unrealistic, but have complex decision boundaries. Our experiments confirm the effectiveness of ICL-transformers pretrained on this data. Furthermore, we create TabForestPFN, the ICL-transformer pretrained on both the original TabPFN synthetic dataset generator and our forest dataset generator. By fine-tuning this model, we reach the current state-of-the-art on tabular data classification. Code is available at https://github.com/FelixdenBreejen/TabForestPFN.
RepAugment: Input-Agnostic Representation-Level Augmentation for Respiratory Sound Classification
May 05, 2024



Recent advancements in AI have democratized its deployment as a healthcare assistant. While pretrained models from large-scale visual and audio datasets have demonstrably generalized to this task, surprisingly, no studies have explored pretrained speech models, which, as human-originated sounds, intuitively would share closer resemblance to lung sounds. This paper explores the efficacy of pretrained speech models for respiratory sound classification. We find that there is a characterization gap between speech and lung sound samples, and to bridge this gap, data augmentation is essential. However, the most widely used augmentation technique for audio and speech, SpecAugment, requires 2-dimensional spectrogram format and cannot be applied to models pretrained on speech waveforms. To address this, we propose RepAugment, an input-agnostic representation-level augmentation technique that outperforms SpecAugment, but is also suitable for respiratory sound classification with waveform pretrained models. Experimental results show that our approach outperforms the SpecAugment, demonstrating a substantial improvement in the accuracy of minority disease classes, reaching up to 7.14%.
Stethoscope-guided Supervised Contrastive Learning for Cross-domain Adaptation on Respiratory Sound Classification
Dec 15, 2023
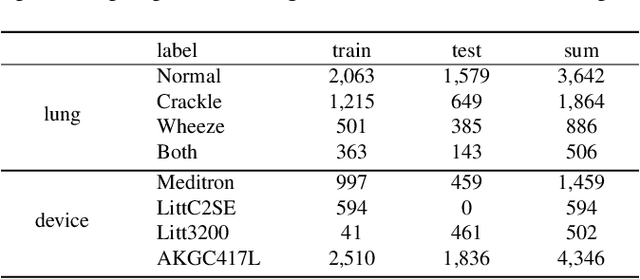
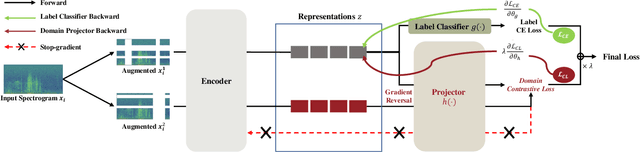
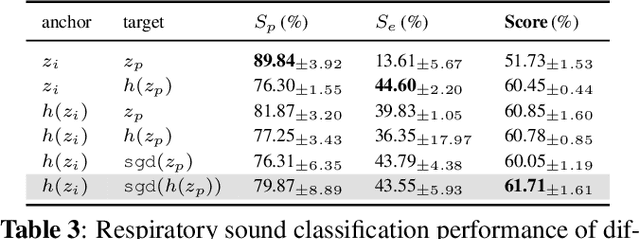
Despite the remarkable advances in deep learning technology, achieving satisfactory performance in lung sound classification remains a challenge due to the scarcity of available data. Moreover, the respiratory sound samples are collected from a variety of electronic stethoscopes, which could potentially introduce biases into the trained models. When a significant distribution shift occurs within the test dataset or in a practical scenario, it can substantially decrease the performance. To tackle this issue, we introduce cross-domain adaptation techniques, which transfer the knowledge from a source domain to a distinct target domain. In particular, by considering different stethoscope types as individual domains, we propose a novel stethoscope-guided supervised contrastive learning approach. This method can mitigate any domain-related disparities and thus enables the model to distinguish respiratory sounds of the recording variation of the stethoscope. The experimental results on the ICBHI dataset demonstrate that the proposed methods are effective in reducing the domain dependency and achieving the ICBHI Score of 61.71%, which is a significant improvement of 2.16% over the baseline.
Fine-Tuning the Retrieval Mechanism for Tabular Deep Learning
Nov 13, 2023


While interests in tabular deep learning has significantly grown, conventional tree-based models still outperform deep learning methods. To narrow this performance gap, we explore the innovative retrieval mechanism, a methodology that allows neural networks to refer to other data points while making predictions. Our experiments reveal that retrieval-based training, especially when fine-tuning the pretrained TabPFN model, notably surpasses existing methods. Moreover, the extensive pretraining plays a crucial role to enhance the performance of the model. These insights imply that blending the retrieval mechanism with pretraining and transfer learning schemes offers considerable potential for advancing the field of tabular deep learning.