 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActions and Objects Pathways for Domain Adaptation in Video Question Answering
Nov 29, 2024In this paper, we introduce the Actions and Objects Pathways (AOPath) for out-of-domain generalization in video question answering tasks. AOPath leverages features from a large pretrained model to enhance generalizability without the need for explicit training on the unseen domains. Inspired by human brain, AOPath dissociates the pretrained features into action and object features, and subsequently processes them through separate reasoning pathways. It utilizes a novel module which converts out-of-domain features into domain-agnostic features without introducing any trainable weights. We validate the proposed approach on the TVQA dataset, which is partitioned into multiple subsets based on genre to facilitate the assessment of generalizability. The proposed approach demonstrates 5% and 4% superior performance over conventional classifiers on out-of-domain and in-domain datasets, respectively. It also outperforms prior methods that involve training millions of parameters, whereas the proposed approach trains very few parameters.
BTS: Bridging Text and Sound Modalities for Metadata-Aided Respiratory Sound Classification
Jun 10, 2024



Respiratory sound classification (RSC) is challenging due to varied acoustic signatures, primarily influenced by patient demographics and recording environments. To address this issue, we introduce a text-audio multimodal model that utilizes metadata of respiratory sounds, which provides useful complementary information for RSC. Specifically, we fine-tune a pretrained text-audio multimodal model using free-text descriptions derived from the sound samples' metadata which includes the gender and age of patients, type of recording devices, and recording location on the patient's body. Our method achieves state-of-the-art performance on the ICBHI dataset, surpassing the previous best result by a notable margin of 1.17%. This result validates the effectiveness of leveraging metadata and respiratory sound samples in enhancing RSC performance. Additionally, we investigate the model performance in the case where metadata is partially unavailable, which may occur in real-world clinical setting.
Contrastive and Consistency Learning for Neural Noisy-Channel Model in Spoken Language Understanding
May 23, 2024



Recently, deep end-to-end learning has been studied for intent classification in Spoken Language Understanding (SLU). However, end-to-end models require a large amount of speech data with intent labels, and highly optimized models are generally sensitive to the inconsistency between the training and evaluation conditions. Therefore, a natural language understanding approach based on Automatic Speech Recognition (ASR) remains attractive because it can utilize a pre-trained general language model and adapt to the mismatch of the speech input environment. Using this module-based approach, we improve a noisy-channel model to handle transcription inconsistencies caused by ASR errors. We propose a two-stage method, Contrastive and Consistency Learning (CCL), that correlates error patterns between clean and noisy ASR transcripts and emphasizes the consistency of the latent features of the two transcripts. Experiments on four benchmark datasets show that CCL outperforms existing methods and improves the ASR robustness in various noisy environments. Code is available at https://github.com/syoung7388/CCL.
RepAugment: Input-Agnostic Representation-Level Augmentation for Respiratory Sound Classification
May 05, 2024



Recent advancements in AI have democratized its deployment as a healthcare assistant. While pretrained models from large-scale visual and audio datasets have demonstrably generalized to this task, surprisingly, no studies have explored pretrained speech models, which, as human-originated sounds, intuitively would share closer resemblance to lung sounds. This paper explores the efficacy of pretrained speech models for respiratory sound classification. We find that there is a characterization gap between speech and lung sound samples, and to bridge this gap, data augmentation is essential. However, the most widely used augmentation technique for audio and speech, SpecAugment, requires 2-dimensional spectrogram format and cannot be applied to models pretrained on speech waveforms. To address this, we propose RepAugment, an input-agnostic representation-level augmentation technique that outperforms SpecAugment, but is also suitable for respiratory sound classification with waveform pretrained models. Experimental results show that our approach outperforms the SpecAugment, demonstrating a substantial improvement in the accuracy of minority disease classes, reaching up to 7.14%.
Stethoscope-guided Supervised Contrastive Learning for Cross-domain Adaptation on Respiratory Sound Classification
Dec 15, 2023
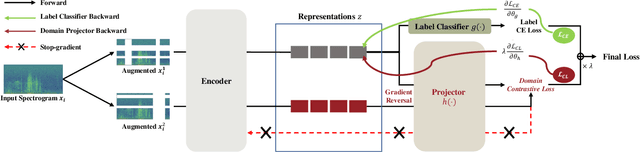
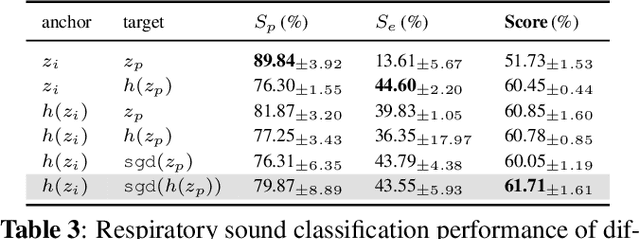
Despite the remarkable advances in deep learning technology, achieving satisfactory performance in lung sound classification remains a challenge due to the scarcity of available data. Moreover, the respiratory sound samples are collected from a variety of electronic stethoscopes, which could potentially introduce biases into the trained models. When a significant distribution shift occurs within the test dataset or in a practical scenario, it can substantially decrease the performance. To tackle this issue, we introduce cross-domain adaptation techniques, which transfer the knowledge from a source domain to a distinct target domain. In particular, by considering different stethoscope types as individual domains, we propose a novel stethoscope-guided supervised contrastive learning approach. This method can mitigate any domain-related disparities and thus enables the model to distinguish respiratory sounds of the recording variation of the stethoscope. The experimental results on the ICBHI dataset demonstrate that the proposed methods are effective in reducing the domain dependency and achieving the ICBHI Score of 61.71%, which is a significant improvement of 2.16% over the baseline.
Adversarial Fine-tuning using Generated Respiratory Sound to Address Class Imbalance
Nov 11, 2023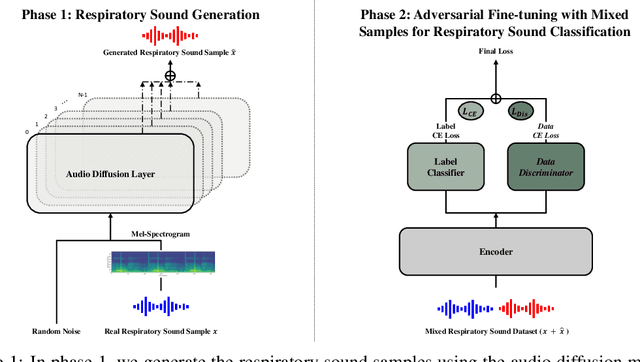

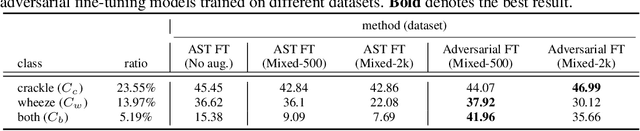
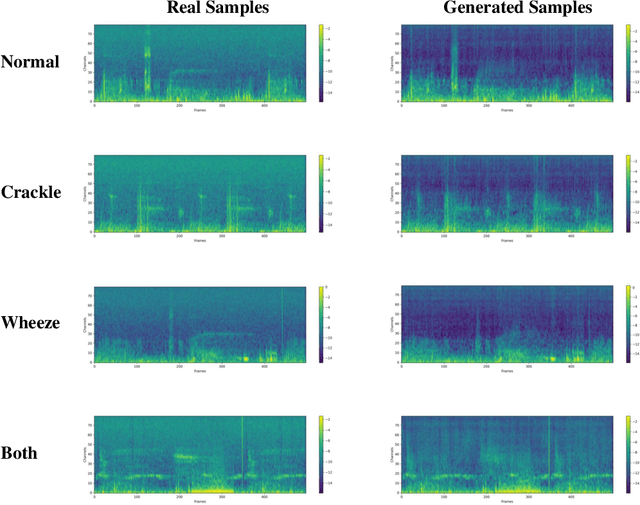
Deep generative models have emerged as a promising approach in the medical image domain to address data scarcity. However, their use for sequential data like respiratory sounds is less explored. In this work, we propose a straightforward approach to augment imbalanced respiratory sound data using an audio diffusion model as a conditional neural vocoder. We also demonstrate a simple yet effective adversarial fine-tuning method to align features between the synthetic and real respiratory sound samples to improve respiratory sound classification performance. Our experimental results on the ICBHI dataset demonstrate that the proposed adversarial fine-tuning is effective, while only using the conventional augmentation method shows performance degradation. Moreover, our method outperforms the baseline by 2.24% on the ICBHI Score and improves the accuracy of the minority classes up to 26.58%. For the supplementary material, we provide the code at https://github.com/kaen2891/adversarial_fine-tuning_using_generated_respiratory_sound.
Vocoder-free End-to-End Voice Conversion with Transformer Network
Feb 05, 2020



Mel-frequency filter bank (MFB) based approaches have the advantage of learning speech compared to raw spectrum since MFB has less feature size. However, speech generator with MFB approaches require additional vocoder that needs a huge amount of computation expense for training process. The additional pre/post processing such as MFB and vocoder is not essential to convert real human speech to others. It is possible to only use the raw spectrum along with the phase to generate different style of voices with clear pronunciation. In this regard, we propose a fast and effective approach to convert realistic voices using raw spectrum in a parallel manner. Our transformer-based model architecture which does not have any CNN or RNN layers has shown the advantage of learning fast and solved the limitation of sequential computation of conventional RNN. In this paper, we introduce a vocoder-free end-to-end voice conversion method using transformer network. The presented conversion model can also be used in speaker adaptation for speech recognition. Our approach can convert the source voice to a target voice without using MFB and vocoder. We can get an adapted MFB for speech recognition by multiplying the converted magnitude with phase. We perform our voice conversion experiments on TIDIGITS dataset using the metrics such as naturalness, similarity, and clarity with mean opinion score, respectively.