 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStethoscope-guided Supervised Contrastive Learning for Cross-domain Adaptation on Respiratory Sound Classification
Dec 15, 2023
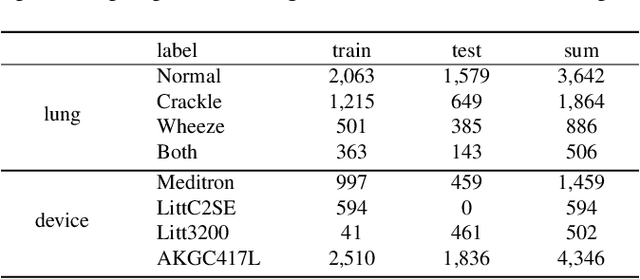
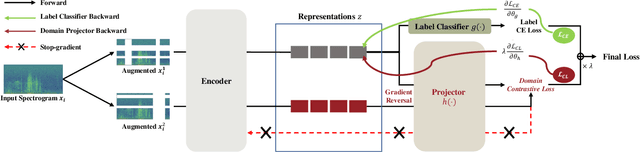
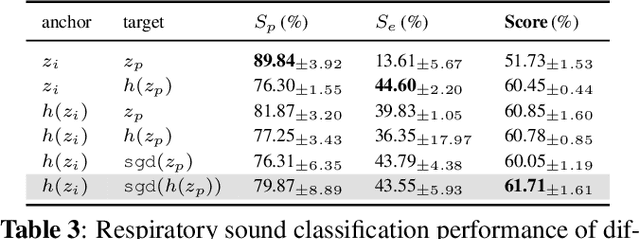
Despite the remarkable advances in deep learning technology, achieving satisfactory performance in lung sound classification remains a challenge due to the scarcity of available data. Moreover, the respiratory sound samples are collected from a variety of electronic stethoscopes, which could potentially introduce biases into the trained models. When a significant distribution shift occurs within the test dataset or in a practical scenario, it can substantially decrease the performance. To tackle this issue, we introduce cross-domain adaptation techniques, which transfer the knowledge from a source domain to a distinct target domain. In particular, by considering different stethoscope types as individual domains, we propose a novel stethoscope-guided supervised contrastive learning approach. This method can mitigate any domain-related disparities and thus enables the model to distinguish respiratory sounds of the recording variation of the stethoscope. The experimental results on the ICBHI dataset demonstrate that the proposed methods are effective in reducing the domain dependency and achieving the ICBHI Score of 61.71%, which is a significant improvement of 2.16% over the baseline.
Patch-Mix Contrastive Learning with Audio Spectrogram Transformer on Respiratory Sound Classification
May 23, 2023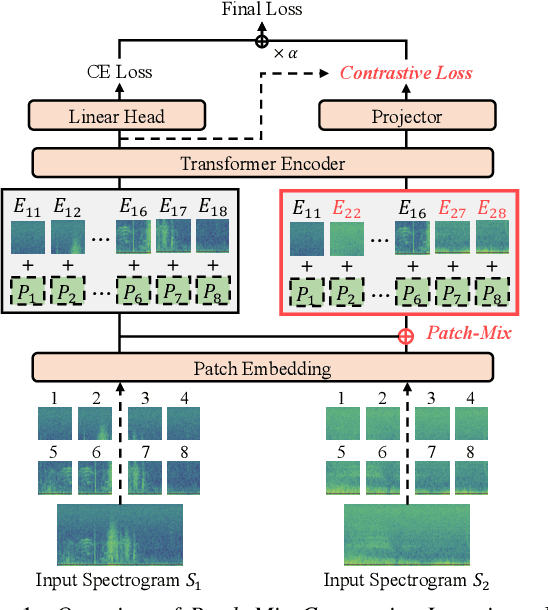
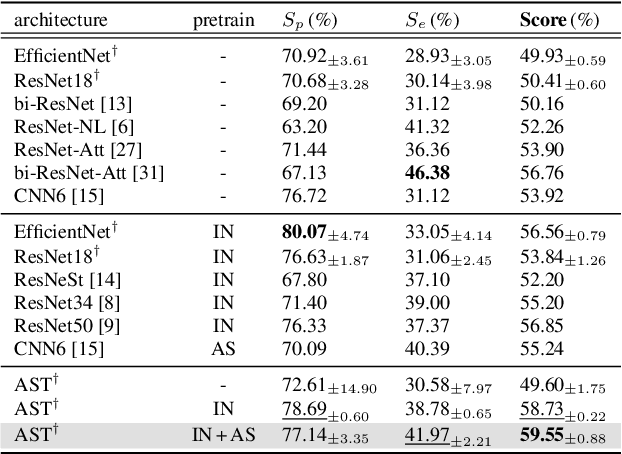
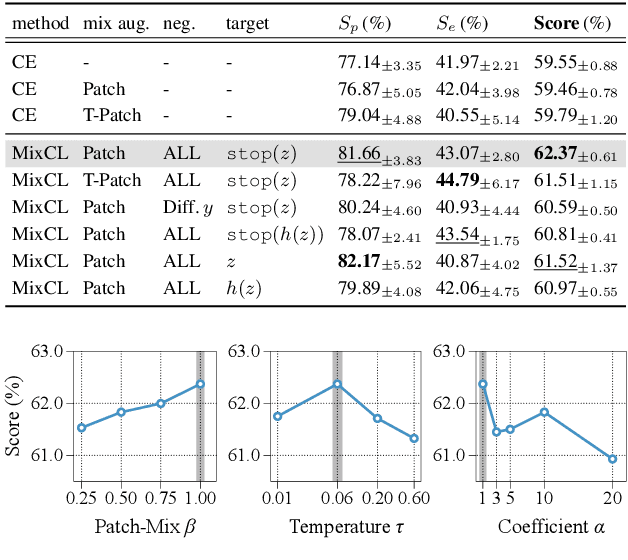
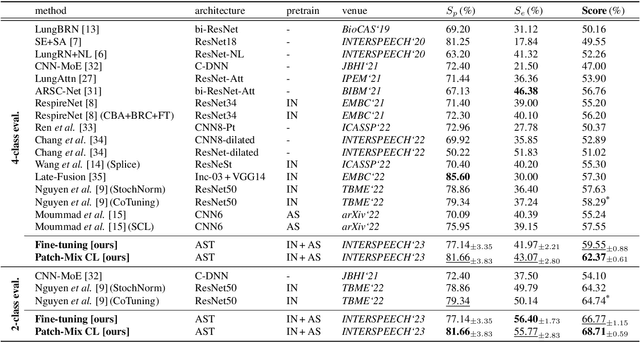
Respiratory sound contains crucial information for the early diagnosis of fatal lung diseases. Since the COVID-19 pandemic, there has been a growing interest in contact-free medical care based on electronic stethoscopes. To this end, cutting-edge deep learning models have been developed to diagnose lung diseases; however, it is still challenging due to the scarcity of medical data. In this study, we demonstrate that the pretrained model on large-scale visual and audio datasets can be generalized to the respiratory sound classification task. In addition, we introduce a straightforward Patch-Mix augmentation, which randomly mixes patches between different samples, with Audio Spectrogram Transformer (AST). We further propose a novel and effective Patch-Mix Contrastive Learning to distinguish the mixed representations in the latent space. Our method achieves state-of-the-art performance on the ICBHI dataset, outperforming the prior leading score by an improvement of 4.08%.