 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung-SRAD: Spectral-Aware Regularized Audio DASS with Dual-Axis Patch-Mix Contrastive Learning for Respiratory Sound Classification
Jun 10, 2026Recent respiratory sound classification (RSC) studies largely rely on CLS-token driven self-attention architectures such as the Audio Spectrogram Transformer (AST). While effective at modeling global context, recent analyses suggest a low-pass filtering behavior that may reduce sensitivity to localized abnormal patterns. In this work, we investigate State Space Models (SSMs) as an alternative backbone for RSC. Using the Distilled Audio State Space model, we analyze intermediate representations through spectral response curves and observe stronger preservation of mid-to-high spatial-frequency components. Based on these observations, we introduce spectral-aware layer regularization using Gaussian convolution applied to selected layers. We further propose Dual-Axis Patch-Mix contrastive learning tailored to SSM-based audio models for robust representation learning. Experiments on the ICBHI benchmark show that our approach achieves 64.48% score, outperforming the AST baseline by 5%. Code is available at https://github.com/RSC-Toolkit/Lung-SRAD.
Quality Adaptive Angular Margin Learning for Respiratory Sound Classification
Jun 10, 2026We present a quality-adaptive angular-margin learning framework that improves feature generalization by enforcing intra-class compactness and inter-class separability. Our framework, titled QLung, introduces a no-reference audio quality margin derived from spectral entropy and root-mean-square energy, which adaptively scales angular margins based on recording quality. To this end, we propose a log-scaled angular margin that stabilizes training under severe class imbalance. We also use an angular classifier that normalizes features and class weights, ensuring margin penalties are applied consistently on the unit hypersphere. Our approach improves in-distribution performance on the ICBHI dataset by 2.46\% over the cross-entropy baseline, and most significantly, achieves the strongest out-of-distribution performance on the SPRSound dataset compared to prior state-of-the-art methods. Code is available at https://github.com/RSC-Toolkit/QLung.
A Hierarchical Feature Engineering Framework for Automated Classification of Phonotraumatic and Non-Phonotraumatic Vocal Hyperfunction
Jun 04, 2026Ambulatory neck-surface acceleration enables non-invasive monitoring of vocal hyperfunction, yet robust biomarkers for its subtypes remain limited. This study investigates the NeckVibe Challenge dataset to distinguish phonotraumatic (PVH) and non-phonotraumatic (NPVH) from healthy controls. We propose a hierarchical feature engineering framework comprising: (i) static, (ii) dynamic, (iii) ratio-based, (iv) coupling features capturing source filter interactions. While univariate statistical analysis shows strong separability for PVH but limited significance for NPVH, our machine learning pipeline, tailored for high-dimensional feature integration, identifies that coupling features are crucial for both tasks. We achieve an AUC of 0.891 for PVH and 0.728 for NPVH, suggesting that while PVH is near-linearly separable, NPVH discrimination benefits from modeling non-linear feature interactions.
Mitigating Stethoscope-Induced Shortcuts in Respiratory Sound Classification under Federated Domain Generalization with Causality-Inspired Interventions
May 28, 2026AI-driven respiratory sound classification (RSC) is promising for automated pulmonary disease detection, yet multi-site deployment is hindered by inter-stethoscope variability. We introduce a federated domain generalization (FedDG) formulation for RSC under stethoscope-induced device shifts, where clients use heterogeneous devices and the model is evaluated on unseen devices. Our empirical analysis shows that stethoscope-induced style and disease-specific content are tightly entangled, making deterministic style removal unreliable. In response, we propose a causality-inspired multimodal FedDG framework that combines: (i) a causality-inspired device style intervention network that performs content-preserving style perturbations, (ii) counterfactual text augmentation that neutralizes metadata shortcuts, and (iii) gradient alignment that facilitates device-invariant representations across clients. Built on a multimodal language-audio pretraining model, it outperforms conventional data augmentation and federated learning baselines in leave-one-device-out validation on ICBHI and SPRSound datasets. Code will be released upon publication.
Meta-Ensemble Learning with Diverse Data Splits for Improved Respiratory Sound Classification
Apr 27, 2026Training reliable respiratory sound classification models remains challenging due to the limited size and subject diversity of datasets. Ensemble methods can improve robustness, but when base models are trained on identical data, models tend to overfit and produce highly correlated predictions, thereby reducing the effectiveness of ensembling. In this work, we investigate a meta-ensemble learning methodology that enhances prediction diversity by training base models on diverse data splits and combining their outputs through a trained meta-model. Specifically, we train base models on the ICBHI dataset using two data split settings: fixed 80-20% split and five-fold cross-validation split, under two data granularity settings: patient- and sample-level. The resulting diversity in base model predictions enables the meta-model to better generalize. Our approach achieves new state-of-the-art performance on the ICBHI benchmark, reaching a Score of 66.49% and showing improved generalization on two out-of-distribution datasets, indicating its potential applicability to real-world clinical data.
Understanding Frechet Speech Distance for Synthetic Speech Quality Evaluation
Jan 29, 2026Objective evaluation of synthetic speech quality remains a critical challenge. Human listening tests are the gold standard, but costly and impractical at scale. Fréchet Distance has emerged as a promising alternative, yet its reliability depends heavily on the choice of embeddings and experimental settings. In this work, we comprehensively evaluate Fréchet Speech Distance (FSD) and its variant Speech Maximum Mean Discrepancy (SMMD) under varied embeddings and conditions. We further incorporate human listening evaluations alongside TTS intelligibility and synthetic-trained ASR WER to validate the perceptual relevance of these metrics. Our findings show that WavLM Base+ features yield the most stable alignment with human ratings. While FSD and SMMD cannot fully replace subjective evaluation, we show that they can serve as complementary, cost-efficient, and reproducible measures, particularly useful when large-scale or direct listening assessments are infeasible. Code is available at https://github.com/kaen2891/FrechetSpeechDistance.
Improving Respiratory Sound Classification with Architecture-Agnostic Knowledge Distillation from Ensembles
May 28, 2025



Respiratory sound datasets are limited in size and quality, making high performance difficult to achieve. Ensemble models help but inevitably increase compute cost at inference time. Soft label training distills knowledge efficiently with extra cost only at training. In this study, we explore soft labels for respiratory sound classification as an architecture-agnostic approach to distill an ensemble of teacher models into a student model. We examine different variations of our approach and find that even a single teacher, identical to the student, considerably improves performance beyond its own capability, with optimal gains achieved using only a few teachers. We achieve the new state-of-the-art Score of 64.39 on ICHBI, surpassing the previous best by 0.85 and improving average Scores across architectures by more than 1.16. Our results highlight the effectiveness of knowledge distillation with soft labels for respiratory sound classification, regardless of size or architecture.
Language-Agnostic Suicidal Risk Detection Using Large Language Models
May 26, 2025Suicidal risk detection in adolescents is a critical challenge, yet existing methods rely on language-specific models, limiting scalability and generalization. This study introduces a novel language-agnostic framework for suicidal risk assessment with large language models (LLMs). We generate Chinese transcripts from speech using an ASR model and then employ LLMs with prompt-based queries to extract suicidal risk-related features from these transcripts. The extracted features are retained in both Chinese and English to enable cross-linguistic analysis and then used to fine-tune corresponding pretrained language models independently. Experimental results show that our method achieves performance comparable to direct fine-tuning with ASR results or to models trained solely on Chinese suicidal risk-related features, demonstrating its potential to overcome language constraints and improve the robustness of suicidal risk assessment.
Tri-MTL: A Triple Multitask Learning Approach for Respiratory Disease Diagnosis
May 06, 2025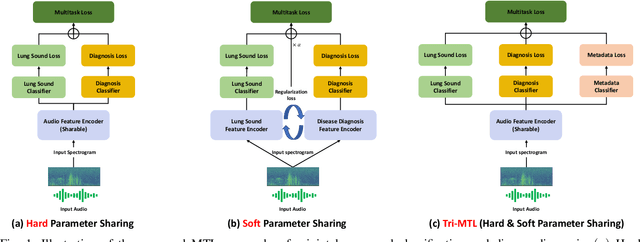
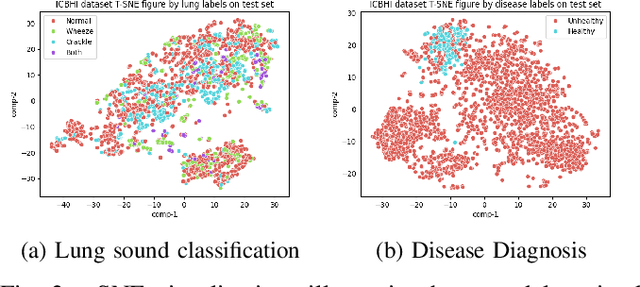
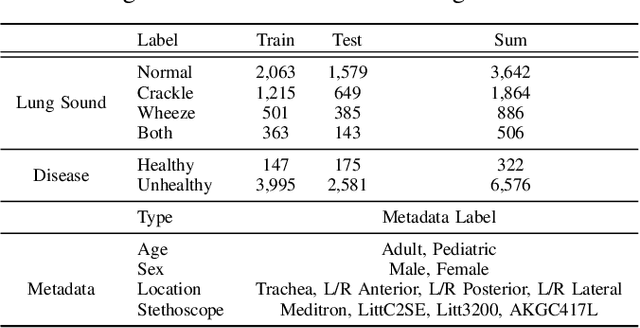
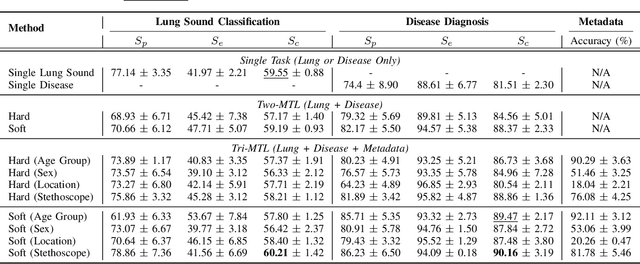
Auscultation remains a cornerstone of clinical practice, essential for both initial evaluation and continuous monitoring. Clinicians listen to the lung sounds and make a diagnosis by combining the patient's medical history and test results. Given this strong association, multitask learning (MTL) can offer a compelling framework to simultaneously model these relationships, integrating respiratory sound patterns with disease manifestations. While MTL has shown considerable promise in medical applications, a significant research gap remains in understanding the complex interplay between respiratory sounds, disease manifestations, and patient metadata attributes. This study investigates how integrating MTL with cutting-edge deep learning architectures can enhance both respiratory sound classification and disease diagnosis. Specifically, we extend recent findings regarding the beneficial impact of metadata on respiratory sound classification by evaluating its effectiveness within an MTL framework. Our comprehensive experiments reveal significant improvements in both lung sound classification and diagnostic performance when the stethoscope information is incorporated into the MTL architecture.
Domain Adversarial Training for Mitigating Gender Bias in Speech-based Mental Health Detection
May 06, 2025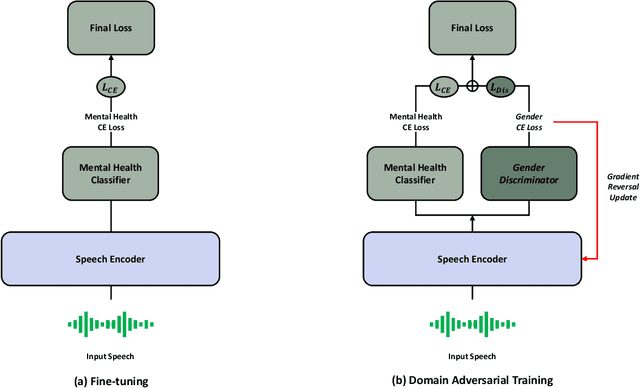



Speech-based AI models are emerging as powerful tools for detecting depression and the presence of Post-traumatic stress disorder (PTSD), offering a non-invasive and cost-effective way to assess mental health. However, these models often struggle with gender bias, which can lead to unfair and inaccurate predictions. In this study, our study addresses this issue by introducing a domain adversarial training approach that explicitly considers gender differences in speech-based depression and PTSD detection. Specifically, we treat different genders as distinct domains and integrate this information into a pretrained speech foundation model. We then validate its effectiveness on the E-DAIC dataset to assess its impact on performance. Experimental results show that our method notably improves detection performance, increasing the F1-score by up to 13.29 percentage points compared to the baseline. This highlights the importance of addressing demographic disparities in AI-driven mental health assessment.