 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Agnostic Multitask Whisper Training for Reducing False Alarm Errors in Call-for-Help Detection
Jan 20, 2025Keyword spotting is often implemented by keyword classifier to the encoder in acoustic models, enabling the classification of predefined or open vocabulary keywords. Although keyword spotting is a crucial task in various applications and can be extended to call-for-help detection in emergencies, however, the previous method often suffers from scalability limitations due to retraining required to introduce new keywords or adapt to changing contexts. We explore a simple yet effective approach that leverages off-the-shelf pretrained ASR models to address these challenges, especially in call-for-help detection scenarios. Furthermore, we observed a substantial increase in false alarms when deploying call-for-help detection system in real-world scenarios due to noise introduced by microphones or different environments. To address this, we propose a novel noise-agnostic multitask learning approach that integrates a noise classification head into the ASR encoder. Our method enhances the model's robustness to noisy environments, leading to a significant reduction in false alarms and improved overall call-for-help performance. Despite the added complexity of multitask learning, our approach is computationally efficient and provides a promising solution for call-for-help detection in real-world scenarios.
Unified Microphone Conversion: Many-to-Many Device Mapping via Feature-wise Linear Modulation
Oct 23, 2024
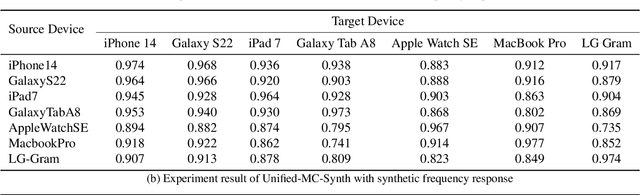
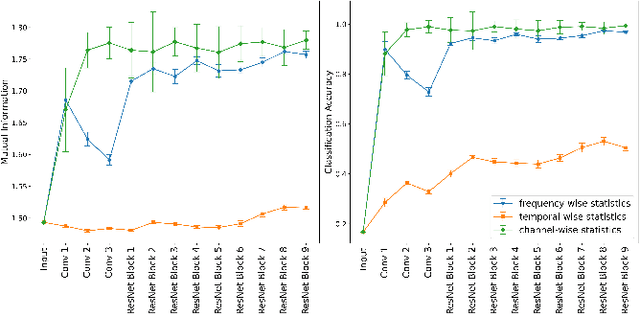
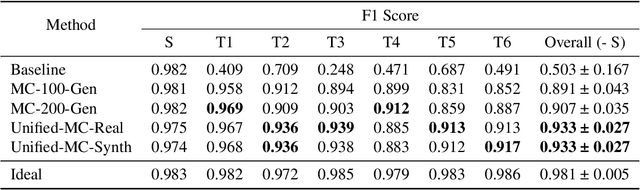
In this study, we introduce Unified Microphone Conversion, a unified generative framework to enhance the resilience of sound event classification systems against device variability. Building on the limitations of previous works, we condition the generator network with frequency response information to achieve many-to-many device mapping. This approach overcomes the inherent limitation of CycleGAN, requiring separate models for each device pair. Our framework leverages the strengths of CycleGAN for unpaired training to simulate device characteristics in audio recordings and significantly extends its scalability by integrating frequency response related information via Feature-wise Linear Modulation. The experiment results show that our method outperforms the state-of-the-art method by 2.6% and reducing variability by 0.8% in macro-average F1 score.
Microphone Conversion: Mitigating Device Variability in Sound Event Classification
Jan 12, 2024
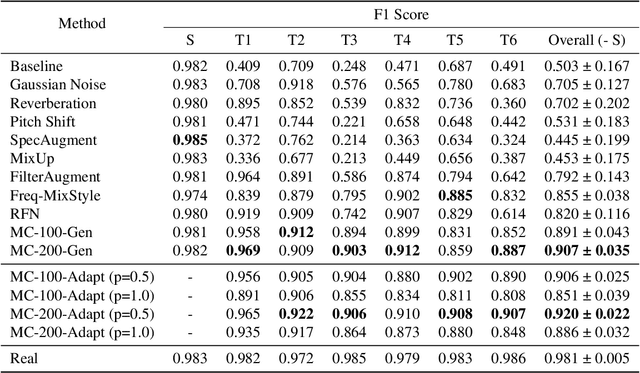
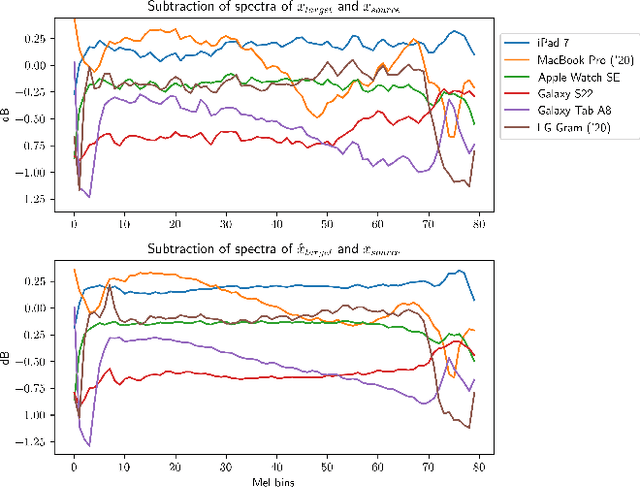

In this study, we introduce a new augmentation technique to enhance the resilience of sound event classification (SEC) systems against device variability through the use of CycleGAN. We also present a unique dataset to evaluate this method. As SEC systems become increasingly common, it is crucial that they work well with audio from diverse recording devices. Our method addresses limited device diversity in training data by enabling unpaired training to transform input spectrograms as if they are recorded on a different device. Our experiments show that our approach outperforms existing methods in generalization by 5.2% - 11.5% in weighted f1 score. Additionally, it surpasses the current methods in adaptability across diverse recording devices by achieving a 6.5% - 12.8% improvement in weighted f1 score.