 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Respiratory Sound Classification with Architecture-Agnostic Knowledge Distillation from Ensembles
May 28, 2025



Respiratory sound datasets are limited in size and quality, making high performance difficult to achieve. Ensemble models help but inevitably increase compute cost at inference time. Soft label training distills knowledge efficiently with extra cost only at training. In this study, we explore soft labels for respiratory sound classification as an architecture-agnostic approach to distill an ensemble of teacher models into a student model. We examine different variations of our approach and find that even a single teacher, identical to the student, considerably improves performance beyond its own capability, with optimal gains achieved using only a few teachers. We achieve the new state-of-the-art Score of 64.39 on ICHBI, surpassing the previous best by 0.85 and improving average Scores across architectures by more than 1.16. Our results highlight the effectiveness of knowledge distillation with soft labels for respiratory sound classification, regardless of size or architecture.
Tri-MTL: A Triple Multitask Learning Approach for Respiratory Disease Diagnosis
May 06, 2025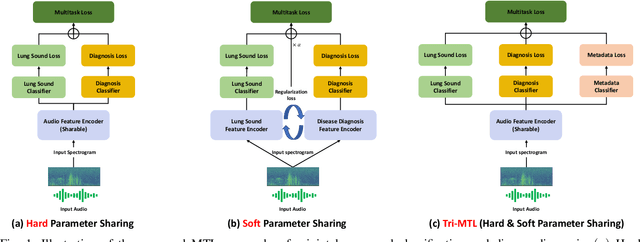
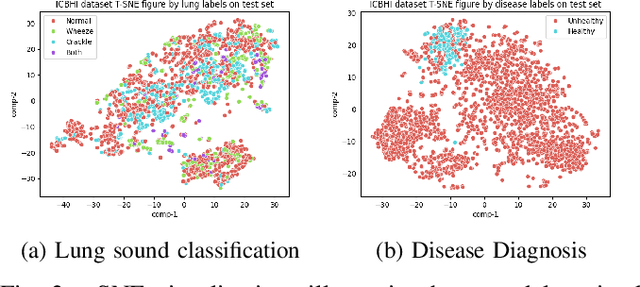
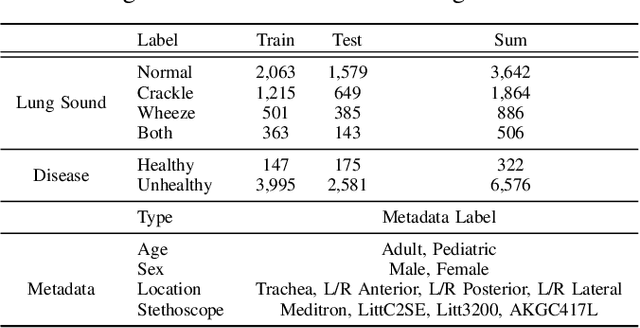
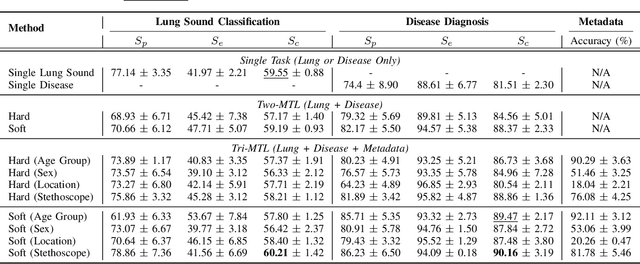
Auscultation remains a cornerstone of clinical practice, essential for both initial evaluation and continuous monitoring. Clinicians listen to the lung sounds and make a diagnosis by combining the patient's medical history and test results. Given this strong association, multitask learning (MTL) can offer a compelling framework to simultaneously model these relationships, integrating respiratory sound patterns with disease manifestations. While MTL has shown considerable promise in medical applications, a significant research gap remains in understanding the complex interplay between respiratory sounds, disease manifestations, and patient metadata attributes. This study investigates how integrating MTL with cutting-edge deep learning architectures can enhance both respiratory sound classification and disease diagnosis. Specifically, we extend recent findings regarding the beneficial impact of metadata on respiratory sound classification by evaluating its effectiveness within an MTL framework. Our comprehensive experiments reveal significant improvements in both lung sound classification and diagnostic performance when the stethoscope information is incorporated into the MTL architecture.
BTS: Bridging Text and Sound Modalities for Metadata-Aided Respiratory Sound Classification
Jun 10, 2024



Respiratory sound classification (RSC) is challenging due to varied acoustic signatures, primarily influenced by patient demographics and recording environments. To address this issue, we introduce a text-audio multimodal model that utilizes metadata of respiratory sounds, which provides useful complementary information for RSC. Specifically, we fine-tune a pretrained text-audio multimodal model using free-text descriptions derived from the sound samples' metadata which includes the gender and age of patients, type of recording devices, and recording location on the patient's body. Our method achieves state-of-the-art performance on the ICBHI dataset, surpassing the previous best result by a notable margin of 1.17%. This result validates the effectiveness of leveraging metadata and respiratory sound samples in enhancing RSC performance. Additionally, we investigate the model performance in the case where metadata is partially unavailable, which may occur in real-world clinical setting.
RepAugment: Input-Agnostic Representation-Level Augmentation for Respiratory Sound Classification
May 05, 2024



Recent advancements in AI have democratized its deployment as a healthcare assistant. While pretrained models from large-scale visual and audio datasets have demonstrably generalized to this task, surprisingly, no studies have explored pretrained speech models, which, as human-originated sounds, intuitively would share closer resemblance to lung sounds. This paper explores the efficacy of pretrained speech models for respiratory sound classification. We find that there is a characterization gap between speech and lung sound samples, and to bridge this gap, data augmentation is essential. However, the most widely used augmentation technique for audio and speech, SpecAugment, requires 2-dimensional spectrogram format and cannot be applied to models pretrained on speech waveforms. To address this, we propose RepAugment, an input-agnostic representation-level augmentation technique that outperforms SpecAugment, but is also suitable for respiratory sound classification with waveform pretrained models. Experimental results show that our approach outperforms the SpecAugment, demonstrating a substantial improvement in the accuracy of minority disease classes, reaching up to 7.14%.
Adversarial Fine-tuning using Generated Respiratory Sound to Address Class Imbalance
Nov 11, 2023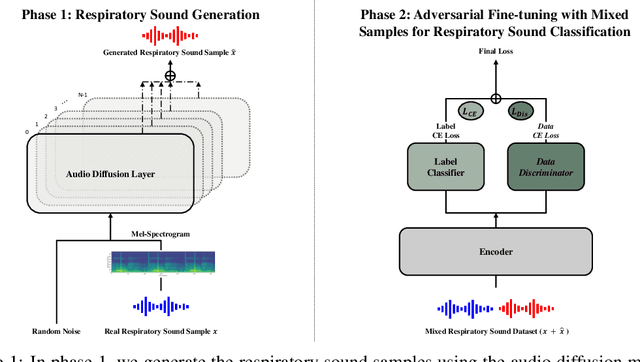

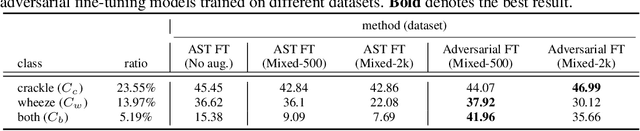
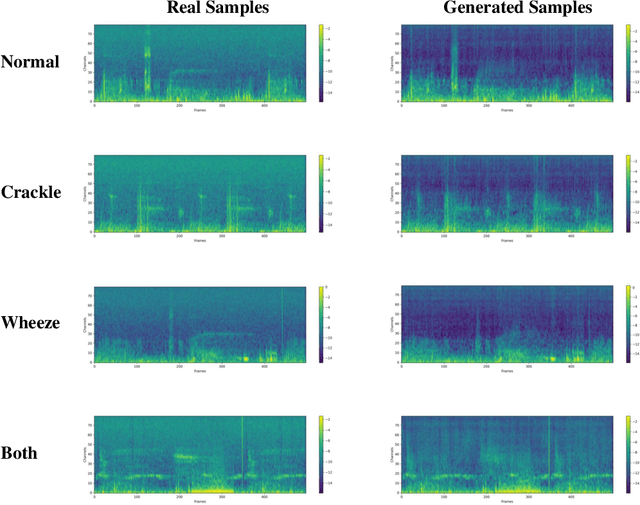
Deep generative models have emerged as a promising approach in the medical image domain to address data scarcity. However, their use for sequential data like respiratory sounds is less explored. In this work, we propose a straightforward approach to augment imbalanced respiratory sound data using an audio diffusion model as a conditional neural vocoder. We also demonstrate a simple yet effective adversarial fine-tuning method to align features between the synthetic and real respiratory sound samples to improve respiratory sound classification performance. Our experimental results on the ICBHI dataset demonstrate that the proposed adversarial fine-tuning is effective, while only using the conventional augmentation method shows performance degradation. Moreover, our method outperforms the baseline by 2.24% on the ICBHI Score and improves the accuracy of the minority classes up to 26.58%. For the supplementary material, we provide the code at https://github.com/kaen2891/adversarial_fine-tuning_using_generated_respiratory_sound.