 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Semantic Collapse in Partially Relevant Video Retrieval
Oct 31, 2025
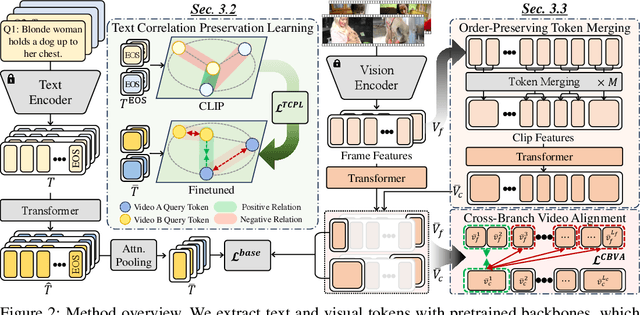
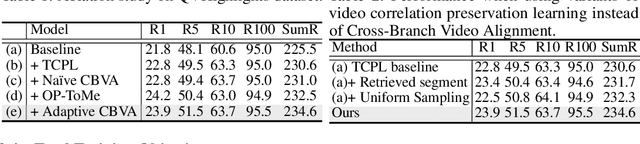
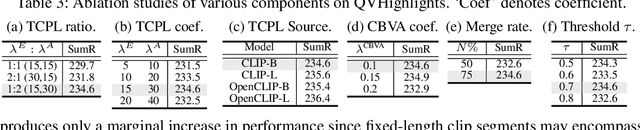
Partially Relevant Video Retrieval (PRVR) seeks videos where only part of the content matches a text query. Existing methods treat every annotated text-video pair as a positive and all others as negatives, ignoring the rich semantic variation both within a single video and across different videos. Consequently, embeddings of both queries and their corresponding video-clip segments for distinct events within the same video collapse together, while embeddings of semantically similar queries and segments from different videos are driven apart. This limits retrieval performance when videos contain multiple, diverse events. This paper addresses the aforementioned problems, termed as semantic collapse, in both the text and video embedding spaces. We first introduce Text Correlation Preservation Learning, which preserves the semantic relationships encoded by the foundation model across text queries. To address collapse in video embeddings, we propose Cross-Branch Video Alignment (CBVA), a contrastive alignment method that disentangles hierarchical video representations across temporal scales. Subsequently, we introduce order-preserving token merging and adaptive CBVA to enhance alignment by producing video segments that are internally coherent yet mutually distinctive. Extensive experiments on PRVR benchmarks demonstrate that our framework effectively prevents semantic collapse and substantially improves retrieval accuracy.
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Aug 14, 2025Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of ``Charlie Chaplin", a ``mustache" consistently appears even if explicitly instructed not to include it, as the concept of ``mustache" is strongly entangled with ``Charlie Chaplin". To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
Mitigating Background Shift in Class-Incremental Semantic Segmentation
Jul 16, 2024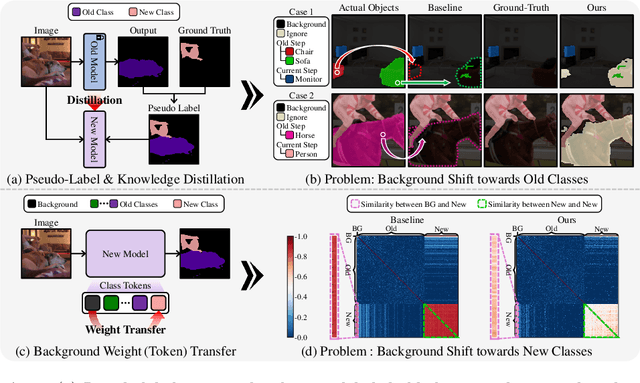
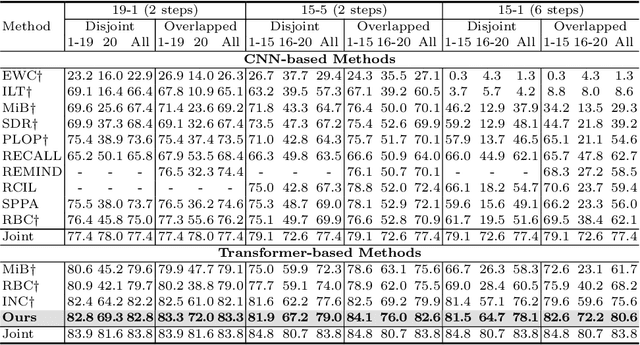
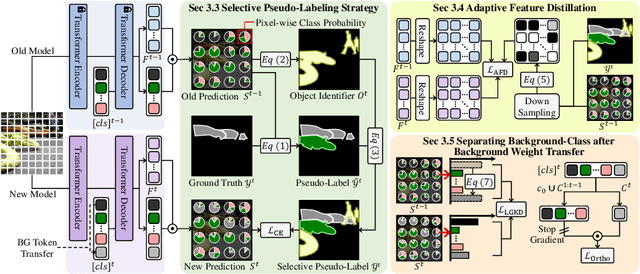
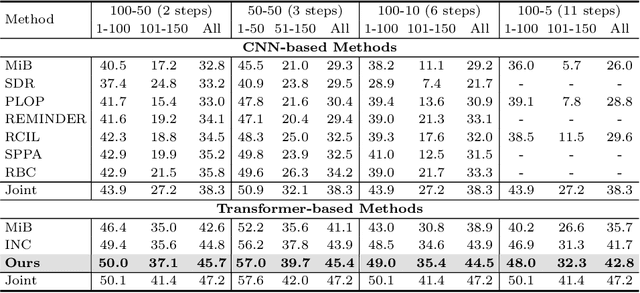
Class-Incremental Semantic Segmentation(CISS) aims to learn new classes without forgetting the old ones, using only the labels of the new classes. To achieve this, two popular strategies are employed: 1) pseudo-labeling and knowledge distillation to preserve prior knowledge; and 2) background weight transfer, which leverages the broad coverage of background in learning new classes by transferring background weight to the new class classifier. However, the first strategy heavily relies on the old model in detecting old classes while undetected pixels are regarded as the background, thereby leading to the background shift towards the old classes(i.e., misclassification of old class as background). Additionally, in the case of the second approach, initializing the new class classifier with background knowledge triggers a similar background shift issue, but towards the new classes. To address these issues, we propose a background-class separation framework for CISS. To begin with, selective pseudo-labeling and adaptive feature distillation are to distill only trustworthy past knowledge. On the other hand, we encourage the separation between the background and new classes with a novel orthogonal objective along with label-guided output distillation. Our state-of-the-art results validate the effectiveness of these proposed methods.
Fine-Tuning the Retrieval Mechanism for Tabular Deep Learning
Nov 13, 2023


While interests in tabular deep learning has significantly grown, conventional tree-based models still outperform deep learning methods. To narrow this performance gap, we explore the innovative retrieval mechanism, a methodology that allows neural networks to refer to other data points while making predictions. Our experiments reveal that retrieval-based training, especially when fine-tuning the pretrained TabPFN model, notably surpasses existing methods. Moreover, the extensive pretraining plays a crucial role to enhance the performance of the model. These insights imply that blending the retrieval mechanism with pretraining and transfer learning schemes offers considerable potential for advancing the field of tabular deep learning.
Lifelog Patterns Analyzation using Graph Embedding based on Deep Neural Network
Sep 10, 2019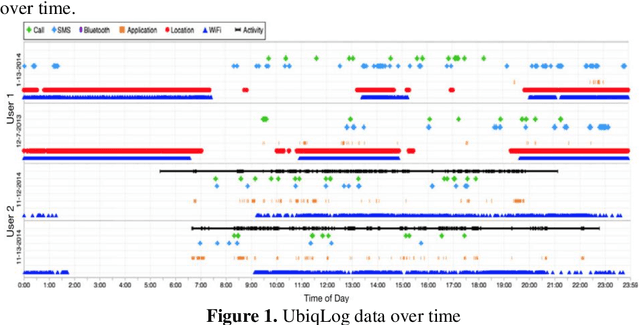
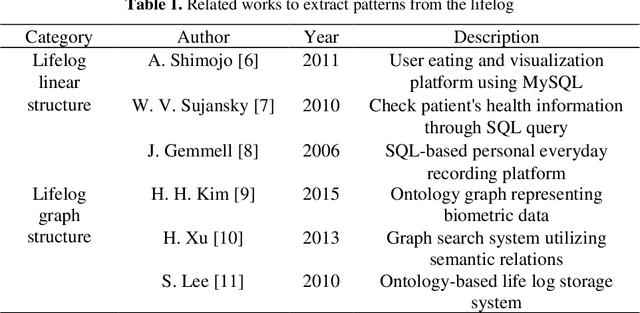
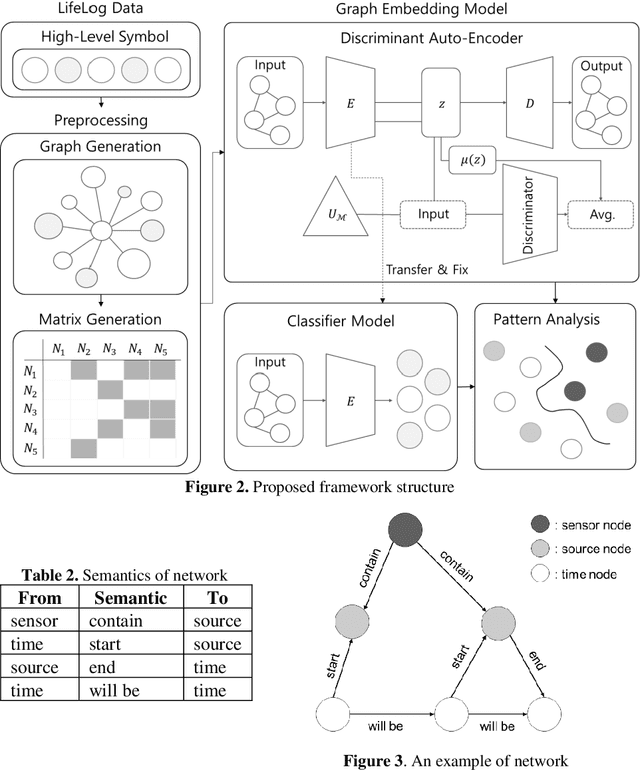
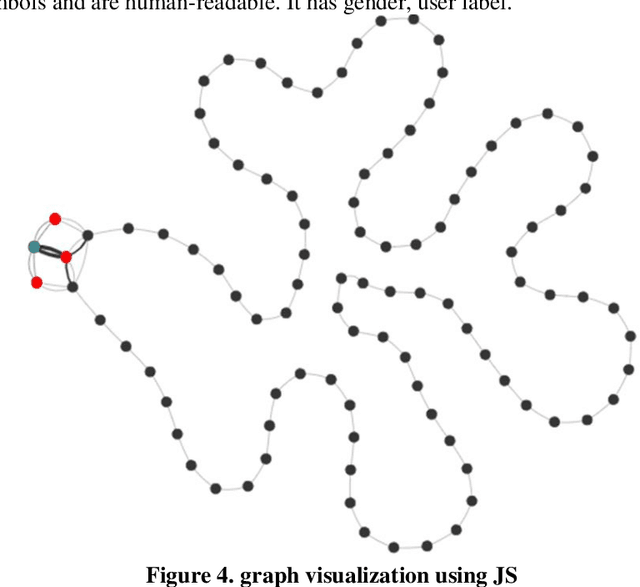
Recently, as the spread of smart devices increases, the amount of data collected through sensors is increasing. A lifelog is a kind of big data to analyze behavior patterns in the daily life of individuals collected from various smart de-vices. However, sensor data is a low-level signal that makes it difficult for hu-mans to recognize the situation directly and cannot express relations clearly. It is also difficult to identify the daily behavior pattern because it records heterogene-ous data by various sensors. In this paper, we propose a method to define a graph structure with node and edge and to extract the daily behavior pattern from the generated lifelog graph. We use the graph convolution method to embeds the lifelog graph and maps it to low dimension. The graph convolution layer im-proves the expressive power of the daily behavior pattern by implanting the life-log graph in the non-Euclidean space and learns the patterns of graphs. Experi-mental results show that the proposed method automatically extracts meaningful user patterns from UbiqLog dataset. In addition, we confirm the usefulness by comparing our method with existing methods to evaluate performance.