 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Graph Transformers Necessary? Efficient Long-Range Message Passing with Fractal Nodes in MPNNs
Nov 17, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning on graph-structured data, but often struggle to balance local and global information. While graph Transformers aim to address this by enabling long-range interactions, they often overlook the inherent locality and efficiency of Message Passing Neural Networks (MPNNs). We propose a new concept called fractal nodes, inspired by the fractal structure observed in real-world networks. Our approach is based on the intuition that graph partitioning naturally induces fractal structure, where subgraphs often reflect the connectivity patterns of the full graph. Fractal nodes are designed to coexist with the original nodes and adaptively aggregate subgraph-level feature representations, thereby enforcing feature similarity within each subgraph. We show that fractal nodes alleviate the over-squashing problem by providing direct shortcut connections that enable long-range propagation of subgraph-level representations. Experiment results show that our method improves the expressive power of MPNNs and achieves comparable or better performance to graph Transformers while maintaining the computational efficiency of MPNN by improving the long-range dependencies of MPNN.
Expandable and Differentiable Dual Memories with Orthogonal Regularization for Exemplar-free Continual Learning
Nov 13, 2025Continual learning methods used to force neural networks to process sequential tasks in isolation, preventing them from leveraging useful inter-task relationships and causing them to repeatedly relearn similar features or overly differentiate them. To address this problem, we propose a fully differentiable, exemplar-free expandable method composed of two complementary memories: One learns common features that can be used across all tasks, and the other combines the shared features to learn discriminative characteristics unique to each sample. Both memories are differentiable so that the network can autonomously learn latent representations for each sample. For each task, the memory adjustment module adaptively prunes critical slots and minimally expands capacity to accommodate new concepts, and orthogonal regularization enforces geometric separation between preserved and newly learned memory components to prevent interference. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet show that the proposed method outperforms 14 state-of-the-art methods for class-incremental learning, achieving final accuracies of 55.13\%, 37.24\%, and 30.11\%, respectively. Additional analysis confirms that, through effective integration and utilization of knowledge, the proposed method can increase average performance across sequential tasks, and it produces feature extraction results closest to the upper bound, thus establishing a new milestone in continual learning.
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring
Jun 06, 2024Recent research in the field of graph neural network (GNN) has identified a critical issue known as "over-squashing," resulting from the bottleneck phenomenon in graph structures, which impedes the propagation of long-range information. Prior works have proposed a variety of graph rewiring concepts that aim at optimizing the spatial or spectral properties of graphs to promote the signal propagation. However, such approaches inevitably deteriorate the original graph topology, which may lead to a distortion of information flow. To address this, we introduce an expanded width-aware (PANDA) message passing, a new message passing paradigm where nodes with high centrality, a potential source of over-squashing, are selectively expanded in width to encapsulate the growing influx of signals from distant nodes. Experimental results show that our method outperforms existing rewiring methods, suggesting that selectively expanding the hidden state of nodes can be a compelling alternative to graph rewiring for addressing the over-squashing.
Stochastic Sampling for Contrastive Views and Hard Negative Samples in Graph-based Collaborative Filtering
May 01, 2024Graph-based collaborative filtering (CF) has emerged as a promising approach in recommendation systems. Despite its achievements, graph-based CF models face challenges due to data sparsity and negative sampling. In this paper, we propose a novel Stochastic sampling for i) COntrastive views and ii) hard NEgative samples (SCONE) to overcome these issues. By considering that they are both sampling tasks, we generate dynamic augmented views and diverse hard negative samples via our unified stochastic sampling framework based on score-based generative models. In our comprehensive evaluations with 6 benchmark datasets, our proposed SCONE significantly improves recommendation accuracy and robustness, and demonstrates the superiority of our approach over existing CF models. Furthermore, we prove the efficacy of user-item specific stochastic sampling for addressing the user sparsity and item popularity issues. The integration of the stochastic sampling and graph-based CF obtains the state-of-the-art in personalized recommendation systems, making significant strides in information-rich environments.
RDGCL: Reaction-Diffusion Graph Contrastive Learning for Recommendation
Dec 27, 2023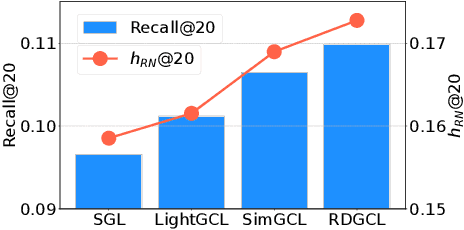

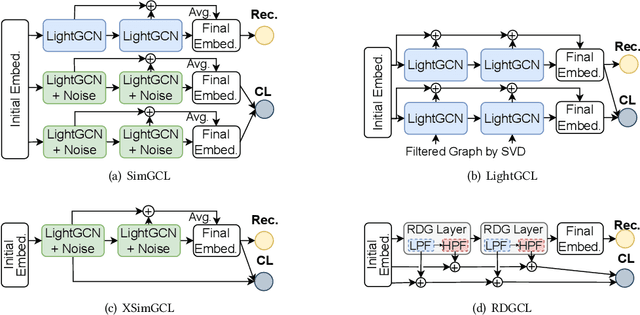

Contrastive learning (CL) has emerged as a promising technique for improving recommender systems, addressing the challenge of data sparsity by leveraging self-supervised signals from raw data. Integration of CL with graph convolutional network (GCN)-based collaborative filterings (CFs) has been explored in recommender systems. However, current CL-based recommendation models heavily rely on low-pass filters and graph augmentations. In this paper, we propose a novel CL method for recommender systems called the reaction-diffusion graph contrastive learning model (RDGCL). We design our own GCN for CF based on both the diffusion, i.e., low-pass filter, and the reaction, i.e., high-pass filter, equations. Our proposed CL-based training occurs between reaction and diffusion-based embeddings, so there is no need for graph augmentations. Experimental evaluation on 6 benchmark datasets demonstrates that our proposed method outperforms state-of-the-art CL-based recommendation models. By enhancing recommendation accuracy and diversity, our method brings an advancement in CL for recommender systems.
GREAD: Graph Neural Reaction-Diffusion Equations
Nov 25, 2022



Graph neural networks (GNNs) are one of the most popular research topics for deep learning. GNN methods typically have been designed on top of the graph signal processing theory. In particular, diffusion equations have been widely used for designing the core processing layer of GNNs and therefore, they are inevitably vulnerable to the oversmoothing problem. Recently, a couple of papers paid attention to reaction equations in conjunctions with diffusion equations. However, they all consider limited forms of reaction equations. To this end, we present a reaction-diffusion equation-based GNN method that considers all popular types of reaction equations in addition to one special reaction equation designed by us. To our knowledge, our paper is one of the most comprehensive studies on reaction-diffusion equation-based GNNs. In our experiments with 9 datasets and 17 baselines, our method, called GREAD, outperforms them in almost all cases. Further synthetic data experiments show that GREAD mitigates the oversmoothing and performs well for various homophily rates.
Perturbation-Recovery Method for Recommendation
Nov 17, 2022Collaborative filtering is one of the most influential recommender system types. Various methods have been proposed for collaborative filtering, ranging from matrix factorization to graph convolutional methods. Being inspired by recent successes of GF-CF and diffusion models, we present a novel concept of blurring-sharpening process model (BSPM). Diffusion models and BSPMs share the same processing philosophy in that new information is discovered (e.g., a new image is generated in the case of diffusion models) while original information is first perturbed and then recovered to its original form. However, diffusion models and our BSPMs deal with different types of information, and their optimal perturbation and recovery processes have a fundamental discrepancy. Therefore, our BSPMs have different forms from diffusion models. In addition, our concept not only theoretically subsumes many existing collaborative filtering models but also outperforms them in terms of Recall and NDCG in the three benchmark datasets, Gowalla, Yelp2018, and Amazon-book. Our model marks the best accuracy in them. In addition, the processing time of our method is one of the shortest cases ever in collaborative filtering. Our proposed concept has much potential in the future to be enhanced by designing better blurring (i.e., perturbation) and sharpening (i.e., recovery) processes than what we use in this paper.
TimeKit: A Time-series Forecasting-based Upgrade Kit for Collaborative Filtering
Nov 08, 2022



Recommender systems are a long-standing research problem in data mining and machine learning. They are incremental in nature, as new user-item interaction logs arrive. In real-world applications, we need to periodically train a collaborative filtering algorithm to extract user/item embedding vectors and therefore, a time-series of embedding vectors can be naturally defined. We present a time-series forecasting-based upgrade kit (TimeKit), which works in the following way: it i) first decides a base collaborative filtering algorithm, ii) extracts user/item embedding vectors with the base algorithm from user-item interaction logs incrementally, e.g., every month, iii) trains our time-series forecasting model with the extracted time-series of embedding vectors, and then iv) forecasts the future embedding vectors and recommend with their dot-product scores owing to a recent breakthrough in processing complicated time-series data, i.e., neural controlled differential equations (NCDEs). Our experiments with four real-world benchmark datasets show that the proposed time-series forecasting-based upgrade kit can significantly enhance existing popular collaborative filtering algorithms.
Lifelog Patterns Analyzation using Graph Embedding based on Deep Neural Network
Sep 10, 2019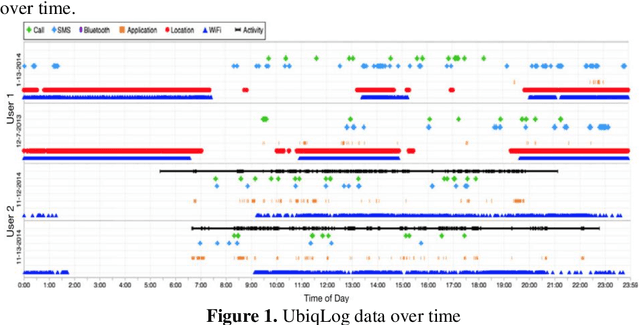
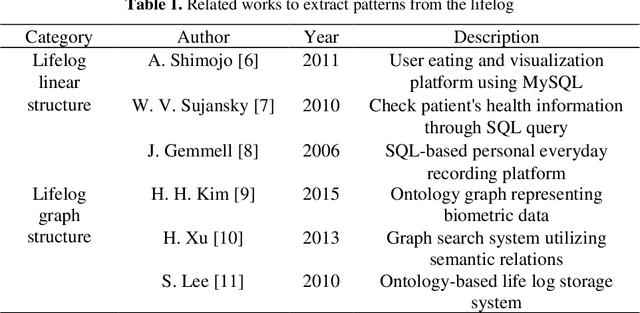
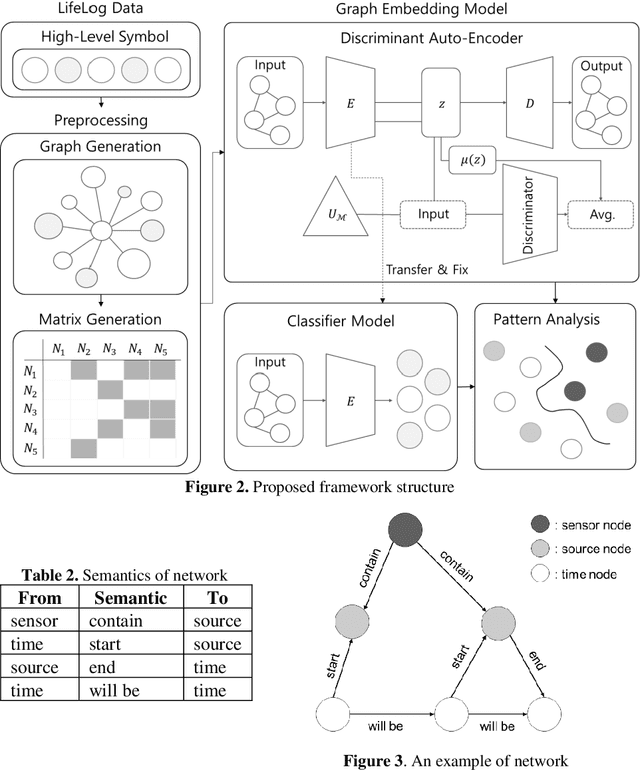
Recently, as the spread of smart devices increases, the amount of data collected through sensors is increasing. A lifelog is a kind of big data to analyze behavior patterns in the daily life of individuals collected from various smart de-vices. However, sensor data is a low-level signal that makes it difficult for hu-mans to recognize the situation directly and cannot express relations clearly. It is also difficult to identify the daily behavior pattern because it records heterogene-ous data by various sensors. In this paper, we propose a method to define a graph structure with node and edge and to extract the daily behavior pattern from the generated lifelog graph. We use the graph convolution method to embeds the lifelog graph and maps it to low dimension. The graph convolution layer im-proves the expressive power of the daily behavior pattern by implanting the life-log graph in the non-Euclidean space and learns the patterns of graphs. Experi-mental results show that the proposed method automatically extracts meaningful user patterns from UbiqLog dataset. In addition, we confirm the usefulness by comparing our method with existing methods to evaluate performance.
Automatic Financial Trading Agent for Low-risk Portfolio Management using Deep Reinforcement Learning
Sep 07, 2019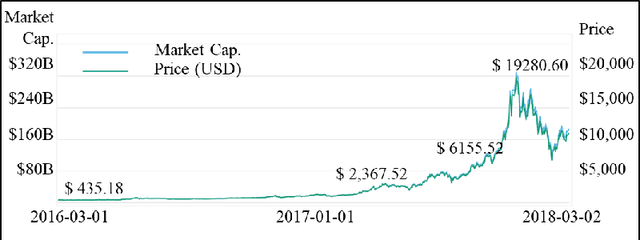


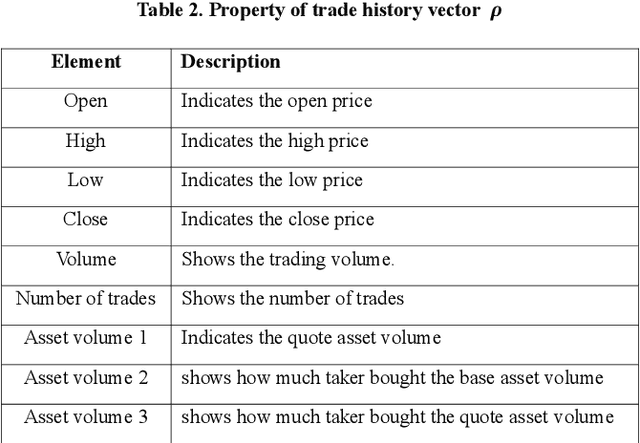
The autonomous trading agent is one of the most actively studied areas of artificial intelligence to solve the capital market portfolio management problem. The two primary goals of the portfolio management problem are maximizing profit and restrainting risk. However, most approaches to this problem solely take account of maximizing returns. Therefore, this paper proposes a deep reinforcement learning based trading agent that can manage the portfolio considering not only profit maximization but also risk restraint. We also propose a new target policy to allow the trading agent to learn to prefer low-risk actions. The new target policy can be reflected in the update by adjusting the greediness for the optimal action through the hyper parameter. The proposed trading agent verifies the performance through the data of the cryptocurrency market. The Cryptocurrency market is the best test-ground for testing our trading agents because of the huge amount of data accumulated every minute and the market volatility is extremely large. As a experimental result, during the test period, our agents achieved a return of 1800% and provided the least risky investment strategy among the existing methods. And, another experiment shows that the agent can maintain robust generalized performance even if market volatility is large or training period is short.