 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Advanced Self-Attention for Linear Transformers in the Singular Value Domain
May 13, 2025Transformers have demonstrated remarkable performance across diverse domains. The key component of Transformers is self-attention, which learns the relationship between any two tokens in the input sequence. Recent studies have revealed that the self-attention can be understood as a normalized adjacency matrix of a graph. Notably, from the perspective of graph signal processing (GSP), the self-attention can be equivalently defined as a simple graph filter, applying GSP using the value vector as the signal. However, the self-attention is a graph filter defined with only the first order of the polynomial matrix, and acts as a low-pass filter preventing the effective leverage of various frequency information. Consequently, existing self-attention mechanisms are designed in a rather simplified manner. Therefore, we propose a novel method, called \underline{\textbf{A}}ttentive \underline{\textbf{G}}raph \underline{\textbf{F}}ilter (AGF), interpreting the self-attention as learning the graph filter in the singular value domain from the perspective of graph signal processing for directed graphs with the linear complexity w.r.t. the input length $n$, i.e., $\mathcal{O}(nd^2)$. In our experiments, we demonstrate that AGF achieves state-of-the-art performance on various tasks, including Long Range Arena benchmark and time series classification.
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring
Jun 06, 2024Recent research in the field of graph neural network (GNN) has identified a critical issue known as "over-squashing," resulting from the bottleneck phenomenon in graph structures, which impedes the propagation of long-range information. Prior works have proposed a variety of graph rewiring concepts that aim at optimizing the spatial or spectral properties of graphs to promote the signal propagation. However, such approaches inevitably deteriorate the original graph topology, which may lead to a distortion of information flow. To address this, we introduce an expanded width-aware (PANDA) message passing, a new message passing paradigm where nodes with high centrality, a potential source of over-squashing, are selectively expanded in width to encapsulate the growing influx of signals from distant nodes. Experimental results show that our method outperforms existing rewiring methods, suggesting that selectively expanding the hidden state of nodes can be a compelling alternative to graph rewiring for addressing the over-squashing.
Stochastic Sampling for Contrastive Views and Hard Negative Samples in Graph-based Collaborative Filtering
May 01, 2024Graph-based collaborative filtering (CF) has emerged as a promising approach in recommendation systems. Despite its achievements, graph-based CF models face challenges due to data sparsity and negative sampling. In this paper, we propose a novel Stochastic sampling for i) COntrastive views and ii) hard NEgative samples (SCONE) to overcome these issues. By considering that they are both sampling tasks, we generate dynamic augmented views and diverse hard negative samples via our unified stochastic sampling framework based on score-based generative models. In our comprehensive evaluations with 6 benchmark datasets, our proposed SCONE significantly improves recommendation accuracy and robustness, and demonstrates the superiority of our approach over existing CF models. Furthermore, we prove the efficacy of user-item specific stochastic sampling for addressing the user sparsity and item popularity issues. The integration of the stochastic sampling and graph-based CF obtains the state-of-the-art in personalized recommendation systems, making significant strides in information-rich environments.
Continuous-time Autoencoders for Regular and Irregular Time Series Imputation
Dec 29, 2023Time series imputation is one of the most fundamental tasks for time series. Real-world time series datasets are frequently incomplete (or irregular with missing observations), in which case imputation is strongly required. Many different time series imputation methods have been proposed. Recent self-attention-based methods show the state-of-the-art imputation performance. However, it has been overlooked for a long time to design an imputation method based on continuous-time recurrent neural networks (RNNs), i.e., neural controlled differential equations (NCDEs). To this end, we redesign time series (variational) autoencoders based on NCDEs. Our method, called continuous-time autoencoder (CTA), encodes an input time series sample into a continuous hidden path (rather than a hidden vector) and decodes it to reconstruct and impute the input. In our experiments with 4 datasets and 19 baselines, our method shows the best imputation performance in almost all cases.
RDGCL: Reaction-Diffusion Graph Contrastive Learning for Recommendation
Dec 27, 2023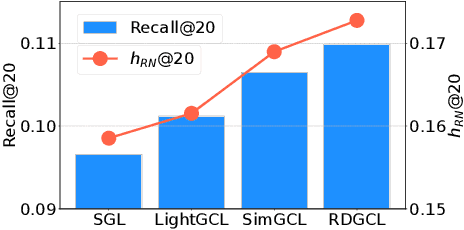

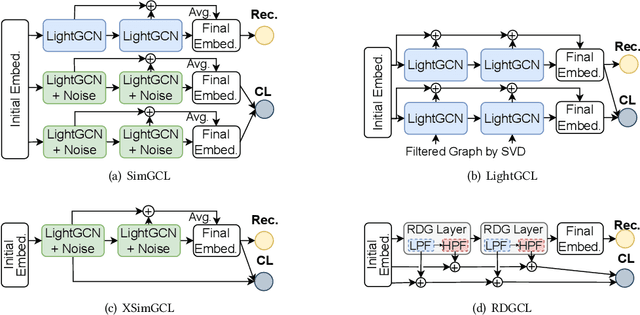

Contrastive learning (CL) has emerged as a promising technique for improving recommender systems, addressing the challenge of data sparsity by leveraging self-supervised signals from raw data. Integration of CL with graph convolutional network (GCN)-based collaborative filterings (CFs) has been explored in recommender systems. However, current CL-based recommendation models heavily rely on low-pass filters and graph augmentations. In this paper, we propose a novel CL method for recommender systems called the reaction-diffusion graph contrastive learning model (RDGCL). We design our own GCN for CF based on both the diffusion, i.e., low-pass filter, and the reaction, i.e., high-pass filter, equations. Our proposed CL-based training occurs between reaction and diffusion-based embeddings, so there is no need for graph augmentations. Experimental evaluation on 6 benchmark datasets demonstrates that our proposed method outperforms state-of-the-art CL-based recommendation models. By enhancing recommendation accuracy and diversity, our method brings an advancement in CL for recommender systems.
Polynomial-based Self-Attention for Table Representation learning
Dec 18, 2023Structured data, which constitutes a significant portion of existing data types, has been a long-standing research topic in the field of machine learning. Various representation learning methods for tabular data have been proposed, ranging from encoder-decoder structures to Transformers. Among these, Transformer-based methods have achieved state-of-the-art performance not only in tabular data but also in various other fields, including computer vision and natural language processing. However, recent studies have revealed that self-attention, a key component of Transformers, can lead to an oversmoothing issue. We show that Transformers for tabular data also face this problem, and to address the problem, we propose a novel matrix polynomial-based self-attention layer as a substitute for the original self-attention layer, which enhances model scalability. In our experiments with three representative table learning models equipped with our proposed layer, we illustrate that the layer effectively mitigates the oversmoothing problem and enhances the representation performance of the existing methods, outperforming the state-of-the-art table representation methods.
An Attentive Inductive Bias for Sequential Recommendation Beyond the Self-Attention
Dec 16, 2023Sequential recommendation (SR) models based on Transformers have achieved remarkable successes. The self-attention mechanism of Transformers for computer vision and natural language processing suffers from the oversmoothing problem, i.e., hidden representations becoming similar to tokens. In the SR domain, we, for the first time, show that the same problem occurs. We present pioneering investigations that reveal the low-pass filtering nature of self-attention in the SR, which causes oversmoothing. To this end, we propose a novel method called Beyond Self-Attention for Sequential Recommendation (BSARec), which leverages the Fourier transform to i) inject an inductive bias by considering fine-grained sequential patterns and ii) integrate low and high-frequency information to mitigate oversmoothing. Our discovery shows significant advancements in the SR domain and is expected to bridge the gap for existing Transformer-based SR models. We test our proposed approach through extensive experiments on 6 benchmark datasets. The experimental results demonstrate that our model outperforms 7 baseline methods in terms of recommendation performance.
Graph Convolutions Enrich the Self-Attention in Transformers!
Dec 07, 2023Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph pattern classification, speech recognition, and code classification.
Long-term Time Series Forecasting based on Decomposition and Neural Ordinary Differential Equations
Nov 10, 2023



Long-term time series forecasting (LTSF) is a challenging task that has been investigated in various domains such as finance investment, health care, traffic, and weather forecasting. In recent years, Linear-based LTSF models showed better performance, pointing out the problem of Transformer-based approaches causing temporal information loss. However, Linear-based approach has also limitations that the model is too simple to comprehensively exploit the characteristics of the dataset. To solve these limitations, we propose LTSF-DNODE, which applies a model based on linear ordinary differential equations (ODEs) and a time series decomposition method according to data statistical characteristics. We show that LTSF-DNODE outperforms the baselines on various real-world datasets. In addition, for each dataset, we explore the impacts of regularization in the neural ordinary differential equation (NODE) framework.
TimeKit: A Time-series Forecasting-based Upgrade Kit for Collaborative Filtering
Nov 08, 2022



Recommender systems are a long-standing research problem in data mining and machine learning. They are incremental in nature, as new user-item interaction logs arrive. In real-world applications, we need to periodically train a collaborative filtering algorithm to extract user/item embedding vectors and therefore, a time-series of embedding vectors can be naturally defined. We present a time-series forecasting-based upgrade kit (TimeKit), which works in the following way: it i) first decides a base collaborative filtering algorithm, ii) extracts user/item embedding vectors with the base algorithm from user-item interaction logs incrementally, e.g., every month, iii) trains our time-series forecasting model with the extracted time-series of embedding vectors, and then iv) forecasts the future embedding vectors and recommend with their dot-product scores owing to a recent breakthrough in processing complicated time-series data, i.e., neural controlled differential equations (NCDEs). Our experiments with four real-world benchmark datasets show that the proposed time-series forecasting-based upgrade kit can significantly enhance existing popular collaborative filtering algorithms.