 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Sampling for Contrastive Views and Hard Negative Samples in Graph-based Collaborative Filtering
May 01, 2024Graph-based collaborative filtering (CF) has emerged as a promising approach in recommendation systems. Despite its achievements, graph-based CF models face challenges due to data sparsity and negative sampling. In this paper, we propose a novel Stochastic sampling for i) COntrastive views and ii) hard NEgative samples (SCONE) to overcome these issues. By considering that they are both sampling tasks, we generate dynamic augmented views and diverse hard negative samples via our unified stochastic sampling framework based on score-based generative models. In our comprehensive evaluations with 6 benchmark datasets, our proposed SCONE significantly improves recommendation accuracy and robustness, and demonstrates the superiority of our approach over existing CF models. Furthermore, we prove the efficacy of user-item specific stochastic sampling for addressing the user sparsity and item popularity issues. The integration of the stochastic sampling and graph-based CF obtains the state-of-the-art in personalized recommendation systems, making significant strides in information-rich environments.
RDGCL: Reaction-Diffusion Graph Contrastive Learning for Recommendation
Dec 27, 2023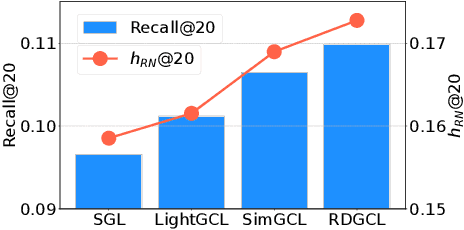

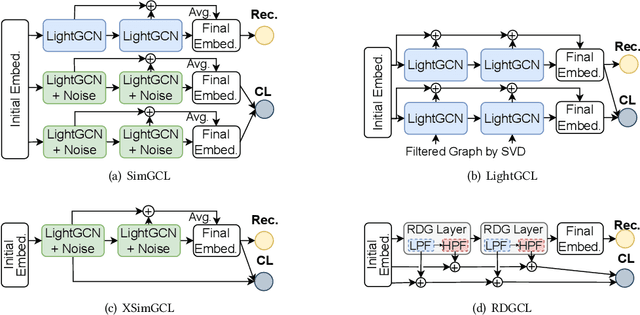

Contrastive learning (CL) has emerged as a promising technique for improving recommender systems, addressing the challenge of data sparsity by leveraging self-supervised signals from raw data. Integration of CL with graph convolutional network (GCN)-based collaborative filterings (CFs) has been explored in recommender systems. However, current CL-based recommendation models heavily rely on low-pass filters and graph augmentations. In this paper, we propose a novel CL method for recommender systems called the reaction-diffusion graph contrastive learning model (RDGCL). We design our own GCN for CF based on both the diffusion, i.e., low-pass filter, and the reaction, i.e., high-pass filter, equations. Our proposed CL-based training occurs between reaction and diffusion-based embeddings, so there is no need for graph augmentations. Experimental evaluation on 6 benchmark datasets demonstrates that our proposed method outperforms state-of-the-art CL-based recommendation models. By enhancing recommendation accuracy and diversity, our method brings an advancement in CL for recommender systems.
CoDi: Co-evolving Contrastive Diffusion Models for Mixed-type Tabular Synthesis
Apr 25, 2023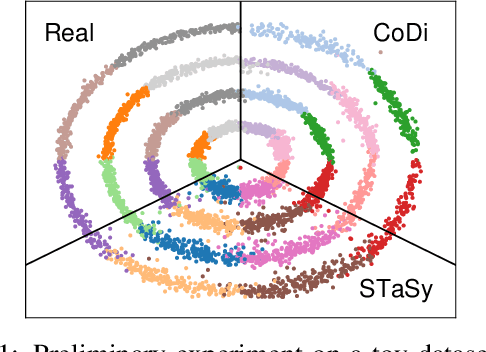
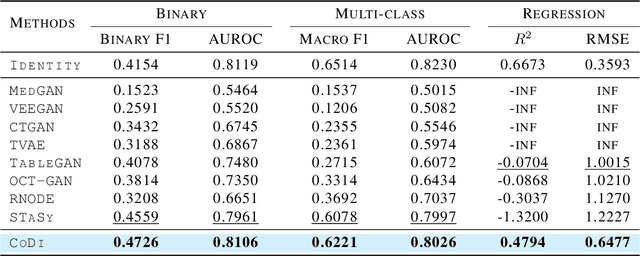
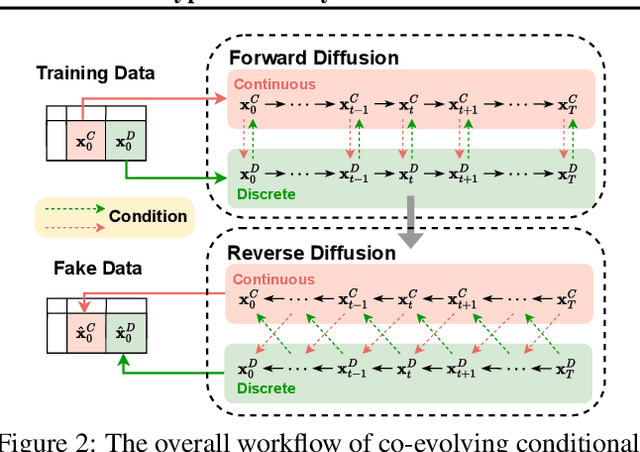
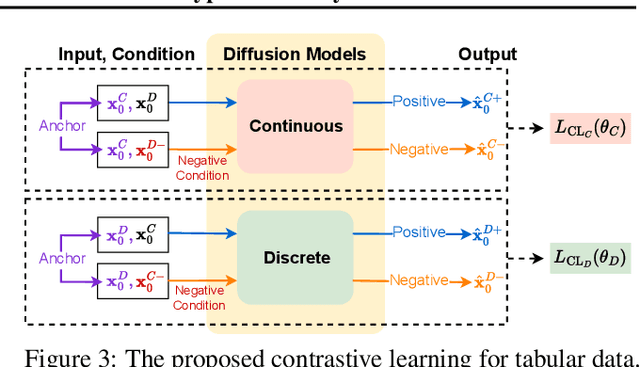
With growing attention to tabular data these days, the attempt to apply a synthetic table to various tasks has been expanded toward various scenarios. Owing to the recent advances in generative modeling, fake data generated by tabular data synthesis models become sophisticated and realistic. However, there still exists a difficulty in modeling discrete variables (columns) of tabular data. In this work, we propose to process continuous and discrete variables separately (but being conditioned on each other) by two diffusion models. The two diffusion models are co-evolved during training by reading conditions from each other. In order to further bind the diffusion models, moreover, we introduce a contrastive learning method with a negative sampling method. In our experiments with 11 real-world tabular datasets and 8 baseline methods, we prove the efficacy of the proposed method, called CoDi.
STaSy: Score-based Tabular data Synthesis
Oct 08, 2022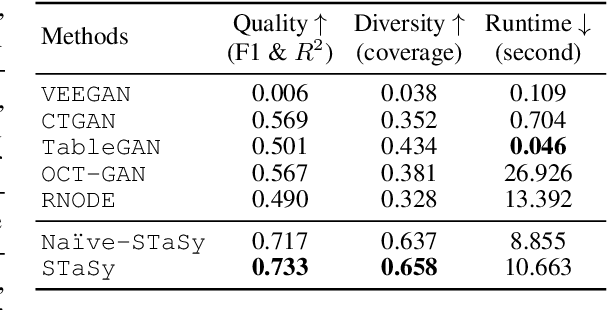
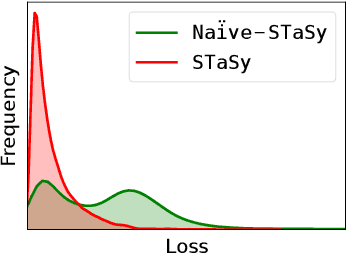
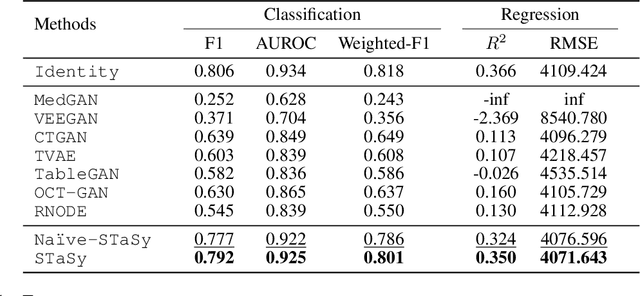

Tabular data synthesis is a long-standing research topic in machine learning. Many different methods have been proposed over the past decades, ranging from statistical methods to deep generative methods. However, it has not always been successful due to the complicated nature of real-world tabular data. In this paper, we present a new model named Score-based Tabular data Synthesis (STaSy) and its training strategy based on the paradigm of score-based generative modeling. Despite the fact that score-based generative models have resolved many issues in generative models, there still exists room for improvement in tabular data synthesis. Our proposed training strategy includes a self-paced learning technique and a fine-tuning strategy, which further increases the sampling quality and diversity by stabilizing the denoising score matching training. Furthermore, we also conduct rigorous experimental studies in terms of the generative task trilemma: sampling quality, diversity, and time. In our experiments with 15 benchmark tabular datasets and 7 baselines, our method outperforms existing methods in terms of task-dependant evaluations and diversity.
SOS: Score-based Oversampling for Tabular Data
Jun 17, 2022
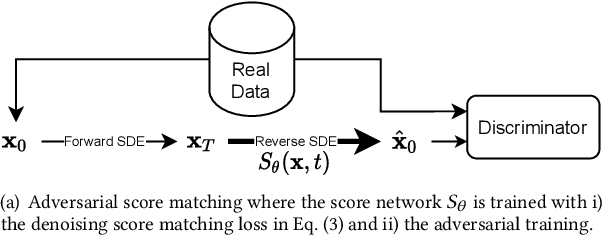
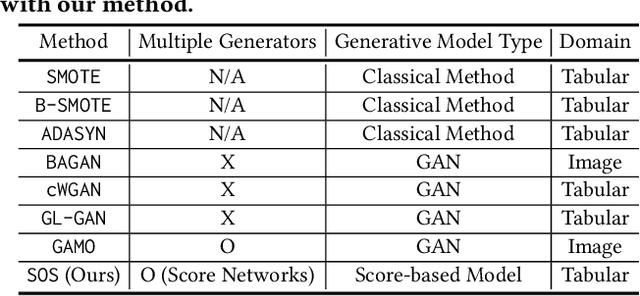
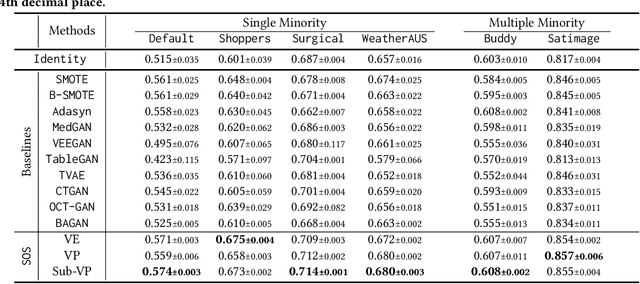
Score-based generative models (SGMs) are a recent breakthrough in generating fake images. SGMs are known to surpass other generative models, e.g., generative adversarial networks (GANs) and variational autoencoders (VAEs). Being inspired by their big success, in this work, we fully customize them for generating fake tabular data. In particular, we are interested in oversampling minor classes since imbalanced classes frequently lead to sub-optimal training outcomes. To our knowledge, we are the first presenting a score-based tabular data oversampling method. Firstly, we re-design our own score network since we have to process tabular data. Secondly, we propose two options for our generation method: the former is equivalent to a style transfer for tabular data and the latter uses the standard generative policy of SGMs. Lastly, we define a fine-tuning method, which further enhances the oversampling quality. In our experiments with 6 datasets and 10 baselines, our method outperforms other oversampling methods in all cases.