 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-time Autoencoders for Regular and Irregular Time Series Imputation
Dec 29, 2023Time series imputation is one of the most fundamental tasks for time series. Real-world time series datasets are frequently incomplete (or irregular with missing observations), in which case imputation is strongly required. Many different time series imputation methods have been proposed. Recent self-attention-based methods show the state-of-the-art imputation performance. However, it has been overlooked for a long time to design an imputation method based on continuous-time recurrent neural networks (RNNs), i.e., neural controlled differential equations (NCDEs). To this end, we redesign time series (variational) autoencoders based on NCDEs. Our method, called continuous-time autoencoder (CTA), encodes an input time series sample into a continuous hidden path (rather than a hidden vector) and decodes it to reconstruct and impute the input. In our experiments with 4 datasets and 19 baselines, our method shows the best imputation performance in almost all cases.
Polynomial-based Self-Attention for Table Representation learning
Dec 18, 2023Structured data, which constitutes a significant portion of existing data types, has been a long-standing research topic in the field of machine learning. Various representation learning methods for tabular data have been proposed, ranging from encoder-decoder structures to Transformers. Among these, Transformer-based methods have achieved state-of-the-art performance not only in tabular data but also in various other fields, including computer vision and natural language processing. However, recent studies have revealed that self-attention, a key component of Transformers, can lead to an oversmoothing issue. We show that Transformers for tabular data also face this problem, and to address the problem, we propose a novel matrix polynomial-based self-attention layer as a substitute for the original self-attention layer, which enhances model scalability. In our experiments with three representative table learning models equipped with our proposed layer, we illustrate that the layer effectively mitigates the oversmoothing problem and enhances the representation performance of the existing methods, outperforming the state-of-the-art table representation methods.
An Attentive Inductive Bias for Sequential Recommendation Beyond the Self-Attention
Dec 16, 2023Sequential recommendation (SR) models based on Transformers have achieved remarkable successes. The self-attention mechanism of Transformers for computer vision and natural language processing suffers from the oversmoothing problem, i.e., hidden representations becoming similar to tokens. In the SR domain, we, for the first time, show that the same problem occurs. We present pioneering investigations that reveal the low-pass filtering nature of self-attention in the SR, which causes oversmoothing. To this end, we propose a novel method called Beyond Self-Attention for Sequential Recommendation (BSARec), which leverages the Fourier transform to i) inject an inductive bias by considering fine-grained sequential patterns and ii) integrate low and high-frequency information to mitigate oversmoothing. Our discovery shows significant advancements in the SR domain and is expected to bridge the gap for existing Transformer-based SR models. We test our proposed approach through extensive experiments on 6 benchmark datasets. The experimental results demonstrate that our model outperforms 7 baseline methods in terms of recommendation performance.
Graph Convolutions Enrich the Self-Attention in Transformers!
Dec 07, 2023Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph pattern classification, speech recognition, and code classification.
SOS: Score-based Oversampling for Tabular Data
Jun 17, 2022
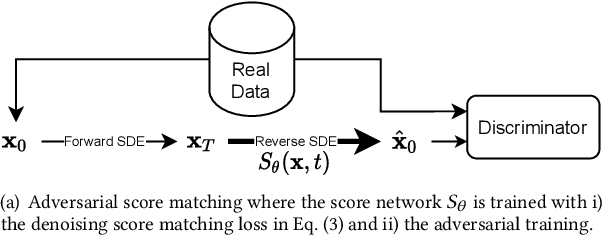
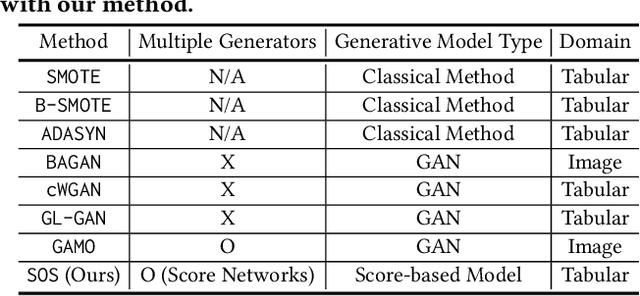
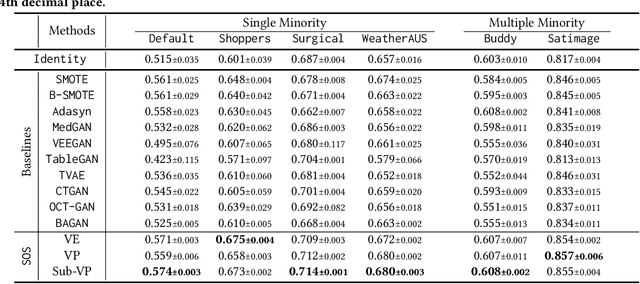
Score-based generative models (SGMs) are a recent breakthrough in generating fake images. SGMs are known to surpass other generative models, e.g., generative adversarial networks (GANs) and variational autoencoders (VAEs). Being inspired by their big success, in this work, we fully customize them for generating fake tabular data. In particular, we are interested in oversampling minor classes since imbalanced classes frequently lead to sub-optimal training outcomes. To our knowledge, we are the first presenting a score-based tabular data oversampling method. Firstly, we re-design our own score network since we have to process tabular data. Secondly, we propose two options for our generation method: the former is equivalent to a style transfer for tabular data and the latter uses the standard generative policy of SGMs. Lastly, we define a fine-tuning method, which further enhances the oversampling quality. In our experiments with 6 datasets and 10 baselines, our method outperforms other oversampling methods in all cases.