 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan TabPFN Compete with GNNs for Node Classification via Graph Tabularization?
Dec 09, 2025Foundation models pretrained on large data have demonstrated remarkable zero-shot generalization capabilities across domains. Building on the success of TabPFN for tabular data and its recent extension to time series, we investigate whether graph node classification can be effectively reformulated as a tabular learning problem. We introduce TabPFN-GN, which transforms graph data into tabular features by extracting node attributes, structural properties, positional encodings, and optionally smoothed neighborhood features. This enables TabPFN to perform direct node classification without any graph-specific training or language model dependencies. Our experiments on 12 benchmark datasets reveal that TabPFN-GN achieves competitive performance with GNNs on homophilous graphs and consistently outperforms them on heterophilous graphs. These results demonstrate that principled feature engineering can bridge the gap between tabular and graph domains, providing a practical alternative to task-specific GNN training and LLM-dependent graph foundation models.
Are Graph Transformers Necessary? Efficient Long-Range Message Passing with Fractal Nodes in MPNNs
Nov 17, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning on graph-structured data, but often struggle to balance local and global information. While graph Transformers aim to address this by enabling long-range interactions, they often overlook the inherent locality and efficiency of Message Passing Neural Networks (MPNNs). We propose a new concept called fractal nodes, inspired by the fractal structure observed in real-world networks. Our approach is based on the intuition that graph partitioning naturally induces fractal structure, where subgraphs often reflect the connectivity patterns of the full graph. Fractal nodes are designed to coexist with the original nodes and adaptively aggregate subgraph-level feature representations, thereby enforcing feature similarity within each subgraph. We show that fractal nodes alleviate the over-squashing problem by providing direct shortcut connections that enable long-range propagation of subgraph-level representations. Experiment results show that our method improves the expressive power of MPNNs and achieves comparable or better performance to graph Transformers while maintaining the computational efficiency of MPNN by improving the long-range dependencies of MPNN.
Learning Advanced Self-Attention for Linear Transformers in the Singular Value Domain
May 13, 2025Transformers have demonstrated remarkable performance across diverse domains. The key component of Transformers is self-attention, which learns the relationship between any two tokens in the input sequence. Recent studies have revealed that the self-attention can be understood as a normalized adjacency matrix of a graph. Notably, from the perspective of graph signal processing (GSP), the self-attention can be equivalently defined as a simple graph filter, applying GSP using the value vector as the signal. However, the self-attention is a graph filter defined with only the first order of the polynomial matrix, and acts as a low-pass filter preventing the effective leverage of various frequency information. Consequently, existing self-attention mechanisms are designed in a rather simplified manner. Therefore, we propose a novel method, called \underline{\textbf{A}}ttentive \underline{\textbf{G}}raph \underline{\textbf{F}}ilter (AGF), interpreting the self-attention as learning the graph filter in the singular value domain from the perspective of graph signal processing for directed graphs with the linear complexity w.r.t. the input length $n$, i.e., $\mathcal{O}(nd^2)$. In our experiments, we demonstrate that AGF achieves state-of-the-art performance on various tasks, including Long Range Arena benchmark and time series classification.
Possibility for Proactive Anomaly Detection
Apr 15, 2025Time-series anomaly detection, which detects errors and failures in a workflow, is one of the most important topics in real-world applications. The purpose of time-series anomaly detection is to reduce potential damages or losses. However, existing anomaly detection models detect anomalies through the error between the model output and the ground truth (observed) value, which makes them impractical. In this work, we present a \textit{proactive} approach for time-series anomaly detection based on a time-series forecasting model specialized for anomaly detection and a data-driven anomaly detection model. Our proactive approach establishes an anomaly threshold from training data with a data-driven anomaly detection model, and anomalies are subsequently detected by identifying predicted values that exceed the anomaly threshold. In addition, we extensively evaluated the model using four anomaly detection benchmarks and analyzed both predictable and unpredictable anomalies. We attached the source code as supplementary material.
PIORF: Physics-Informed Ollivier-Ricci Flow for Long-Range Interactions in Mesh Graph Neural Networks
Apr 05, 2025Recently, data-driven simulators based on graph neural networks have gained attention in modeling physical systems on unstructured meshes. However, they struggle with long-range dependencies in fluid flows, particularly in refined mesh regions. This challenge, known as the 'over-squashing' problem, hinders information propagation. While existing graph rewiring methods address this issue to some extent, they only consider graph topology, overlooking the underlying physical phenomena. We propose Physics-Informed Ollivier-Ricci Flow (PIORF), a novel rewiring method that combines physical correlations with graph topology. PIORF uses Ollivier-Ricci curvature (ORC) to identify bottleneck regions and connects these areas with nodes in high-velocity gradient nodes, enabling long-range interactions and mitigating over-squashing. Our approach is computationally efficient in rewiring edges and can scale to larger simulations. Experimental results on 3 fluid dynamics benchmark datasets show that PIORF consistently outperforms baseline models and existing rewiring methods, achieving up to 26.2 improvement.
Bridging Dynamic Factor Models and Neural Controlled Differential Equations for Nowcasting GDP
Sep 13, 2024
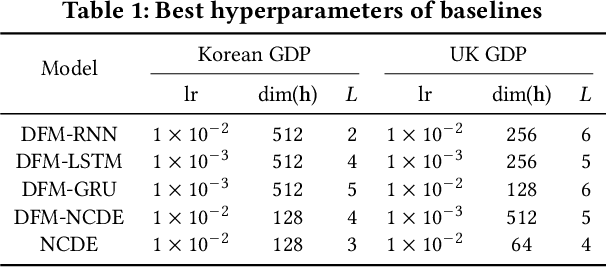


Gross domestic product (GDP) nowcasting is crucial for policy-making as GDP growth is a key indicator of economic conditions. Dynamic factor models (DFMs) have been widely adopted by government agencies for GDP nowcasting due to their ability to handle irregular or missing macroeconomic indicators and their interpretability. However, DFMs face two main challenges: i) the lack of capturing economic uncertainties such as sudden recessions or booms, and ii) the limitation of capturing irregular dynamics from mixed-frequency data. To address these challenges, we introduce NCDENow, a novel GDP nowcasting framework that integrates neural controlled differential equations (NCDEs) with DFMs. This integration effectively handles the dynamics of irregular time series. NCDENow consists of 3 main modules: i) factor extraction leveraging DFM, ii) dynamic modeling using NCDE, and iii) GDP growth prediction through regression. We evaluate NCDENow against 6 baselines on 2 real-world GDP datasets from South Korea and the United Kingdom, demonstrating its enhanced predictive capability. Our empirical results favor our method, highlighting the significant potential of integrating NCDE into nowcasting models. Our code and dataset are available at https://github.com/sklim84/NCDENow_CIKM2024.
Graph Signal Processing for Cross-Domain Recommendation
Jul 17, 2024Cross-domain recommendation (CDR) extends conventional recommender systems by leveraging user-item interactions from dense domains to mitigate data sparsity and the cold start problem. While CDR offers substantial potential for enhancing recommendation performance, most existing CDR methods suffer from sensitivity to the ratio of overlapping users and intrinsic discrepancy between source and target domains. To overcome these limitations, in this work, we explore the application of graph signal processing (GSP) in CDR scenarios. We propose CGSP, a unified CDR framework based on GSP, which employs a cross-domain similarity graph constructed by flexibly combining target-only similarity and source-bridged similarity. By processing personalized graph signals computed for users from either the source or target domain, our framework effectively supports both inter-domain and intra-domain recommendations. Our empirical evaluation demonstrates that CGSP consistently outperforms various encoder-based CDR approaches in both intra-domain and inter-domain recommendation scenarios, especially when the ratio of overlapping users is low, highlighting its significant practical implication in real-world applications.
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring
Jun 06, 2024Recent research in the field of graph neural network (GNN) has identified a critical issue known as "over-squashing," resulting from the bottleneck phenomenon in graph structures, which impedes the propagation of long-range information. Prior works have proposed a variety of graph rewiring concepts that aim at optimizing the spatial or spectral properties of graphs to promote the signal propagation. However, such approaches inevitably deteriorate the original graph topology, which may lead to a distortion of information flow. To address this, we introduce an expanded width-aware (PANDA) message passing, a new message passing paradigm where nodes with high centrality, a potential source of over-squashing, are selectively expanded in width to encapsulate the growing influx of signals from distant nodes. Experimental results show that our method outperforms existing rewiring methods, suggesting that selectively expanding the hidden state of nodes can be a compelling alternative to graph rewiring for addressing the over-squashing.
SVD-AE: Simple Autoencoders for Collaborative Filtering
May 08, 2024Collaborative filtering (CF) methods for recommendation systems have been extensively researched, ranging from matrix factorization and autoencoder-based to graph filtering-based methods. Recently, lightweight methods that require almost no training have been recently proposed to reduce overall computation. However, existing methods still have room to improve the trade-offs among accuracy, efficiency, and robustness. In particular, there are no well-designed closed-form studies for \emph{balanced} CF in terms of the aforementioned trade-offs. In this paper, we design SVD-AE, a simple yet effective singular vector decomposition (SVD)-based linear autoencoder, whose closed-form solution can be defined based on SVD for CF. SVD-AE does not require iterative training processes as its closed-form solution can be calculated at once. Furthermore, given the noisy nature of the rating matrix, we explore the robustness against such noisy interactions of existing CF methods and our SVD-AE. As a result, we demonstrate that our simple design choice based on truncated SVD can be used to strengthen the noise robustness of the recommendation while improving efficiency. Code is available at https://github.com/seoyoungh/svd-ae.
Stochastic Sampling for Contrastive Views and Hard Negative Samples in Graph-based Collaborative Filtering
May 01, 2024Graph-based collaborative filtering (CF) has emerged as a promising approach in recommendation systems. Despite its achievements, graph-based CF models face challenges due to data sparsity and negative sampling. In this paper, we propose a novel Stochastic sampling for i) COntrastive views and ii) hard NEgative samples (SCONE) to overcome these issues. By considering that they are both sampling tasks, we generate dynamic augmented views and diverse hard negative samples via our unified stochastic sampling framework based on score-based generative models. In our comprehensive evaluations with 6 benchmark datasets, our proposed SCONE significantly improves recommendation accuracy and robustness, and demonstrates the superiority of our approach over existing CF models. Furthermore, we prove the efficacy of user-item specific stochastic sampling for addressing the user sparsity and item popularity issues. The integration of the stochastic sampling and graph-based CF obtains the state-of-the-art in personalized recommendation systems, making significant strides in information-rich environments.