 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning is Not Enough: Representational Entanglement in Dual-output Second Language Speech Recognition
Jun 04, 2026Second-language (L2) speech recognition often requires transcriptions of pronunciations and intended meanings. Multi-task learning (MTL) is a natural approach because it assumes that shared representations benefit both outputs. However, this paper shows that this assumption does not hold across Korean and English. MTL improves meaning but degrades surface transcription, especially in English, where the degradation scales with surface-meaning divergence measured by Levenshtein edit distance.Encoder analysis links these patterns to encoder-level entanglement, with Korean preserving distinct task representations while English produces nearly identical ones. Cross-task decoder analysis shows that the meaning dual-output decoder adapts with a unique representation, while the surface dual-output decoder remains constrained by the encoder. These findings motivate the design of MTL frameworks that mitigate encoder-level entanglement to reduce surface degradation in dual-output L2 automatic speech recognition.
MARC: Multimodal and Multi-Task Agentic Retrieval-Augmented Generation for Cold-Start Recommender System
Nov 15, 2025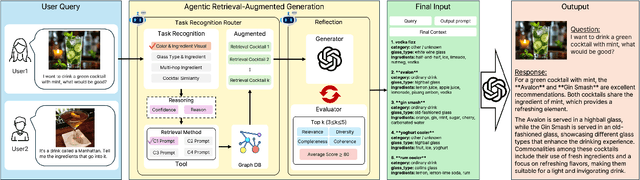
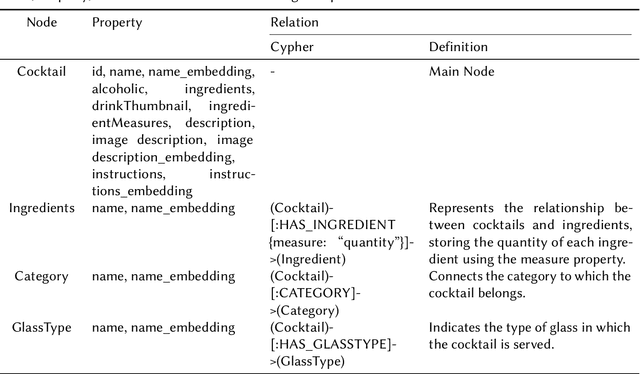
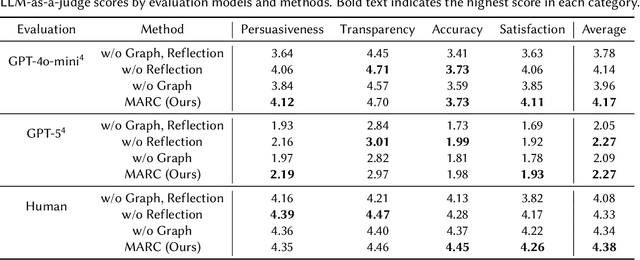
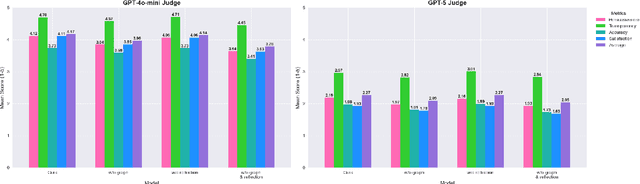
Recommender systems (RS) are currently being studied to mitigate limitations during cold-start conditions by leveraging modality information or introducing Agent concepts based on the exceptional reasoning capabilities of Large Language Models (LLMs). Meanwhile, food and beverage recommender systems have traditionally used knowledge graph and ontology concepts due to the domain's unique data attributes and relationship characteristics. On this background, we propose MARC, a multimodal and multi-task cocktail recommender system based on Agentic Retrieval-Augmented Generation (RAG) utilizing graph database under cold-start conditions. The proposed system generates high-quality, contextually appropriate answers through two core processes: a task recognition router and a reflection process. The graph database was constructed by processing cocktail data from Kaggle, and its effectiveness was evaluated using 200 manually crafted questions. The evaluation used both LLM-as-a-judge and human evaluation to demonstrate that answers generated via the graph database outperformed those from a simple vector database in terms of quality. The code is available at https://github.com/diddbwls/cocktail_rec_agentrag
Bridging Dynamic Factor Models and Neural Controlled Differential Equations for Nowcasting GDP
Sep 13, 2024
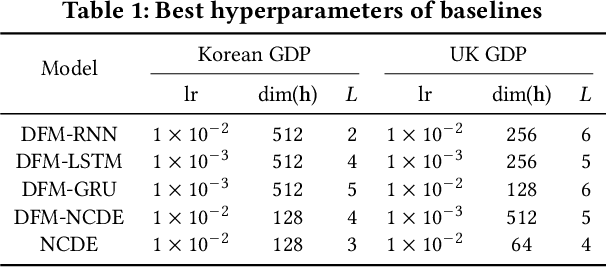


Gross domestic product (GDP) nowcasting is crucial for policy-making as GDP growth is a key indicator of economic conditions. Dynamic factor models (DFMs) have been widely adopted by government agencies for GDP nowcasting due to their ability to handle irregular or missing macroeconomic indicators and their interpretability. However, DFMs face two main challenges: i) the lack of capturing economic uncertainties such as sudden recessions or booms, and ii) the limitation of capturing irregular dynamics from mixed-frequency data. To address these challenges, we introduce NCDENow, a novel GDP nowcasting framework that integrates neural controlled differential equations (NCDEs) with DFMs. This integration effectively handles the dynamics of irregular time series. NCDENow consists of 3 main modules: i) factor extraction leveraging DFM, ii) dynamic modeling using NCDE, and iii) GDP growth prediction through regression. We evaluate NCDENow against 6 baselines on 2 real-world GDP datasets from South Korea and the United Kingdom, demonstrating its enhanced predictive capability. Our empirical results favor our method, highlighting the significant potential of integrating NCDE into nowcasting models. Our code and dataset are available at https://github.com/sklim84/NCDENow_CIKM2024.
Key-point Guided Deformable Image Manipulation Using Diffusion Model
Jan 16, 2024In this paper, we introduce a Key-point-guided Diffusion probabilistic Model (KDM) that gains precise control over images by manipulating the object's key-point. We propose a two-stage generative model incorporating an optical flow map as an intermediate output. By doing so, a dense pixel-wise understanding of the semantic relation between the image and sparse key point is configured, leading to more realistic image generation. Additionally, the integration of optical flow helps regulate the inter-frame variance of sequential images, demonstrating an authentic sequential image generation. The KDM is evaluated with diverse key-point conditioned image synthesis tasks, including facial image generation, human pose synthesis, and echocardiography video prediction, demonstrating the KDM is proving consistency enhanced and photo-realistic images compared with state-of-the-art models.
Image-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023



While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
Balanced Supervised Contrastive Learning for Few-Shot Class-Incremental Learning
May 26, 2023



Few-shot class-incremental learning (FSCIL) presents the primary challenge of balancing underfitting to a new session's task and forgetting the tasks from previous sessions. To address this challenge, we develop a simple yet powerful learning scheme that integrates effective methods for each core component of the FSCIL network, including the feature extractor, base session classifiers, and incremental session classifiers. In feature extractor training, our goal is to obtain balanced generic representations that benefit both current viewable and unseen or past classes. To achieve this, we propose a balanced supervised contrastive loss that effectively balances these two objectives. In terms of classifiers, we analyze and emphasize the importance of unifying initialization methods for both the base and incremental session classifiers. Our method demonstrates outstanding ability for new task learning and preventing forgetting on CUB200, CIFAR100, and miniImagenet datasets, with significant improvements over previous state-of-the-art methods across diverse metrics. We conduct experiments to analyze the significance and rationale behind our approach and visualize the effectiveness of our representations on new tasks. Furthermore, we conduct diverse ablation studies to analyze the effects of each module.
Temporal Multinomial Mixture for Instance-Oriented Evolutionary Clustering
Jan 11, 2016

Evolutionary clustering aims at capturing the temporal evolution of clusters. This issue is particularly important in the context of social media data that are naturally temporally driven. In this paper, we propose a new probabilistic model-based evolutionary clustering technique. The Temporal Multinomial Mixture (TMM) is an extension of classical mixture model that optimizes feature co-occurrences in the trade-off with temporal smoothness. Our model is evaluated for two recent case studies on opinion aggregation over time. We compare four different probabilistic clustering models and we show the superiority of our proposal in the task of instance-oriented clustering.