 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023



While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
Balanced Supervised Contrastive Learning for Few-Shot Class-Incremental Learning
May 26, 2023



Few-shot class-incremental learning (FSCIL) presents the primary challenge of balancing underfitting to a new session's task and forgetting the tasks from previous sessions. To address this challenge, we develop a simple yet powerful learning scheme that integrates effective methods for each core component of the FSCIL network, including the feature extractor, base session classifiers, and incremental session classifiers. In feature extractor training, our goal is to obtain balanced generic representations that benefit both current viewable and unseen or past classes. To achieve this, we propose a balanced supervised contrastive loss that effectively balances these two objectives. In terms of classifiers, we analyze and emphasize the importance of unifying initialization methods for both the base and incremental session classifiers. Our method demonstrates outstanding ability for new task learning and preventing forgetting on CUB200, CIFAR100, and miniImagenet datasets, with significant improvements over previous state-of-the-art methods across diverse metrics. We conduct experiments to analyze the significance and rationale behind our approach and visualize the effectiveness of our representations on new tasks. Furthermore, we conduct diverse ablation studies to analyze the effects of each module.
s-DRN: Stabilized Developmental Resonance Network
Dec 18, 2019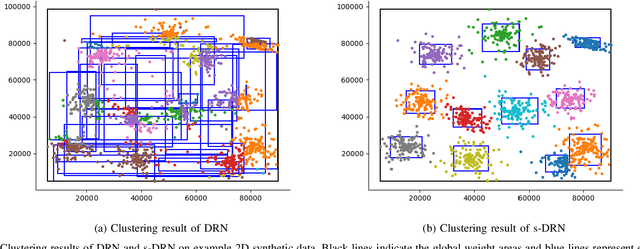
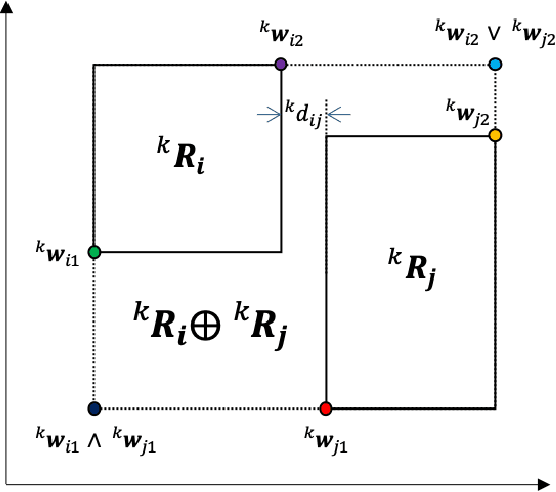
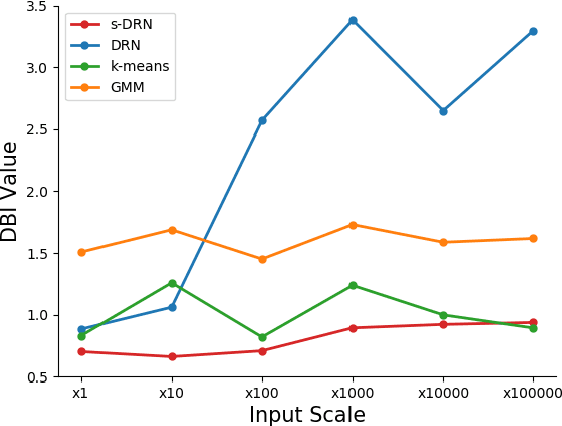
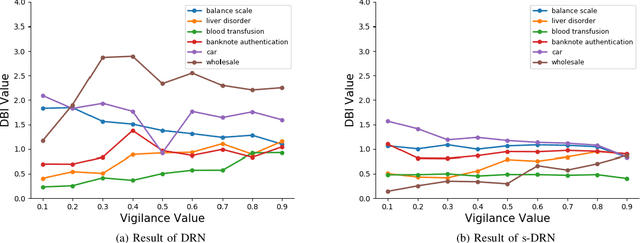
Online incremental clustering of sequentially incoming data without prior knowledge suffers from changing cluster numbers and tends to fall into local extrema according to given data order. To overcome these limitations, we propose a stabilized developmental resonance network (s-DRN). First, we analyze the instability of the conventional choice function during the node activation process and design a scalable activation function to make clustering performance stable over all input data scales. Next, we devise three criteria for the node grouping algorithm: distance, intersection over union (IoU) and size criteria. The proposed node grouping algorithm effectively excludes unnecessary clusters from incrementally created clusters, diminishes the performance dependency on vigilance parameters and makes the clustering process robust. To verify the performance of the proposed s-DRN model, comparative studies are conducted on six real-world datasets whose statistical characteristics are distinctive. The comparative studies demonstrate the proposed s-DRN outperforms baselines in terms of stability and accuracy.