 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Alignment: Preventing Positional Collapse in Multimodal Recommender Systems
Mar 13, 2026Multimodal recommender systems (MMRS) leverage images, text, and interaction signals to enrich item representations. However, recent alignment based MMRSs that enforce a unified embedding space often blur modality specific structures and exacerbate ID dominance. Therefore, we propose AnchorRec, a multimodal recommendation framework that performs indirect, anchor based alignment in a lightweight projection domain. By decoupling alignment from representation learning, AnchorRec preserves each modality's native structure while maintaining cross modal consistency and avoiding positional collapse. Experiments on four Amazon datasets show that AnchorRec achieves competitive top N recommendation accuracy, while qualitative analyses demonstrate improved multimodal expressiveness and coherence. The codebase of AnchorRec is available at https://github.com/hun9008/AnchorRec.
E-MMKGR: A Unified Multimodal Knowledge Graph Framework for E-commerce Applications
Feb 24, 2026Multimodal recommender systems (MMRSs) enhance collaborative filtering by leveraging item-side modalities, but their reliance on a fixed set of modalities and task-specific objectives limits both modality extensibility and task generalization. We propose E-MMKGR, a framework that constructs an e-commerce-specific Multimodal Knowledge Graph E-MMKG and learns unified item representations through GNN-based propagation and KG-oriented optimization. These representations provide a shared semantic foundation applicable to diverse tasks. Experiments on real-world Amazon datasets show improvements of up to 10.18% in Recall@10 for recommendation and up to 21.72% over vector-based retrieval for product search, demonstrating the effectiveness and extensibility of our approach.
Echoes in the Loop: Diagnosing Risks in LLM-Powered Recommender Systems under Feedback Loops
Feb 07, 2026Large language models (LLMs) are increasingly embedded into recommender systems, where they operate across multiple functional roles such as data augmentation, profiling, and decision making. While prior work emphasizes recommendation performance, the systemic risks of LLMs, such as bias and hallucination, and their propagation through feedback loops remain largely unexplored. In this paper, we propose a role-aware, phase-wise diagnostic framework that traces how these risks emerge, manifest in ranking outcomes, and accumulate over repeated recommendation cycles. We formalize a controlled feedback-loop pipeline that simulates long-term interaction dynamics and enables empirical measurement of risks at the LLM-generated content, ranking, and ecosystem levels. Experiments on widely used benchmarks demonstrate that LLM-based components can amplify popularity bias, introduce spurious signals through hallucination, and lead to polarized and self-reinforcing exposure patterns over time. We plan to release our framework as an open-source toolkit to facilitate systematic risk analysis across diverse LLM-powered recommender systems.
Improving the Accuracy of Community Detection on Signed Networks via Community Refinement and Contrastive Learning
Jan 23, 2026Community detection (CD) on signed networks is crucial for understanding how positive and negative relations jointly shape network structure. However, existing CD methods often yield inconsistent communities due to noisy or conflicting edge signs. In this paper, we propose ReCon, a model-agnostic post-processing framework that progressively refines community structures through four iterative steps: (1) structural refinement, (2) boundary refinement, (3) contrastive learning, and (4) clustering. Extensive experiments on eighteen synthetic and four real-world networks using four CD methods demonstrate that ReCon consistently enhances community detection accuracy, serving as an effective and easily integrable solution for reliable CD across diverse network properties.
CAPER: Enhancing Career Trajectory Prediction using Temporal Knowledge Graph and Ternary Relationship
Aug 28, 2024



The problem of career trajectory prediction (CTP) aims to predict one's future employer or job position. While several CTP methods have been developed for this problem, we posit that none of these methods (1) jointly considers the mutual ternary dependency between three key units (i.e., user, position, and company) of a career and (2) captures the characteristic shifts of key units in career over time, leading to an inaccurate understanding of the job movement patterns in the labor market. To address the above challenges, we propose a novel solution, named as CAPER, that solves the challenges via sophisticated temporal knowledge graph (TKG) modeling. It enables the utilization of a graph-structured knowledge base with rich expressiveness, effectively preserving the changes in job movement patterns. Furthermore, we devise an extrapolated career reasoning task on TKG for a realistic evaluation. The experiments on a real-world career trajectory dataset demonstrate that CAPER consistently and significantly outperforms four baselines, two recent TKG reasoning methods, and five state-of-the-art CTP methods in predicting one's future companies and positions-i.e., on average, yielding 6.80% and 34.58% more accurate predictions, respectively.
Disentangling, Amplifying, and Debiasing: Learning Disentangled Representations for Fair Graph Neural Networks
Aug 23, 2024Graph Neural Networks (GNNs) have become essential tools for graph representation learning in various domains, such as social media and healthcare. However, they often suffer from fairness issues due to inherent biases in node attributes and graph structure, leading to unfair predictions. To address these challenges, we propose a novel GNN framework, DAB-GNN, that Disentangles, Amplifies, and deBiases attribute, structure, and potential biases in the GNN mechanism. DAB-GNN employs a disentanglement and amplification module that isolates and amplifies each type of bias through specialized disentanglers, followed by a debiasing module that minimizes the distance between subgroup distributions to ensure fairness. Extensive experiments on five datasets demonstrate that DAB-GNN significantly outperforms ten state-of-the-art competitors in terms of achieving an optimal balance between accuracy and fairness.
Empowering Interdisciplinary Insights with Dynamic Graph Embedding Trajectories
Jun 25, 2024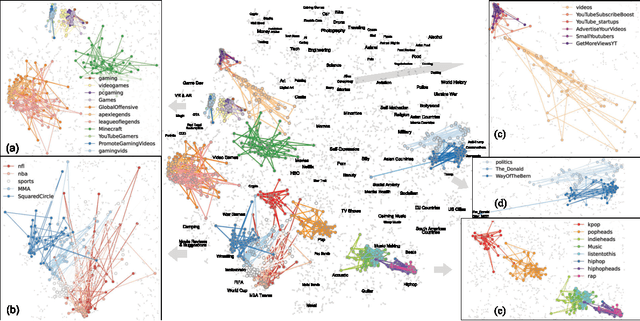
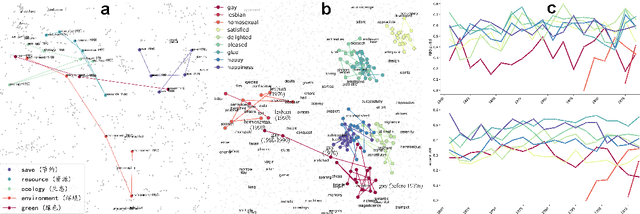
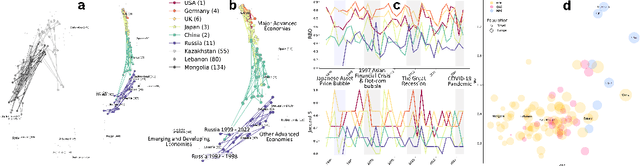
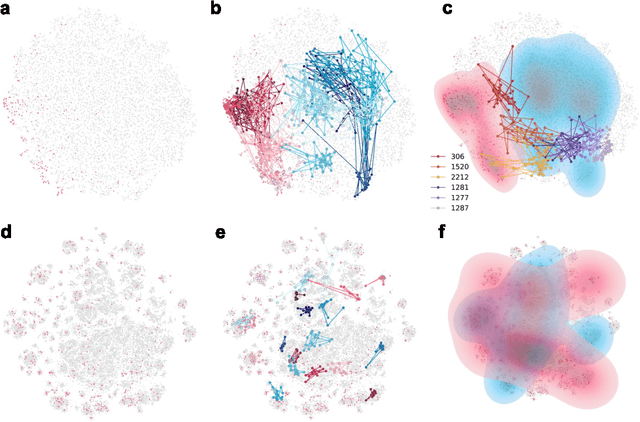
We developed DyGETViz, a novel framework for effectively visualizing dynamic graphs (DGs) that are ubiquitous across diverse real-world systems. This framework leverages recent advancements in discrete-time dynamic graph (DTDG) models to adeptly handle the temporal dynamics inherent in dynamic graphs. DyGETViz effectively captures both micro- and macro-level structural shifts within these graphs, offering a robust method for representing complex and massive dynamic graphs. The application of DyGETViz extends to a diverse array of domains, including ethology, epidemiology, finance, genetics, linguistics, communication studies, social studies, and international relations. Through its implementation, DyGETViz has revealed or confirmed various critical insights. These include the diversity of content sharing patterns and the degree of specialization within online communities, the chronological evolution of lexicons across decades, and the distinct trajectories exhibited by aging-related and non-related genes. Importantly, DyGETViz enhances the accessibility of scientific findings to non-domain experts by simplifying the complexities of dynamic graphs. Our framework is released as an open-source Python package for use across diverse disciplines. Our work not only addresses the ongoing challenges in visualizing and analyzing DTDG models but also establishes a foundational framework for future investigations into dynamic graph representation and analysis across various disciplines.
SVD-AE: Simple Autoencoders for Collaborative Filtering
May 08, 2024Collaborative filtering (CF) methods for recommendation systems have been extensively researched, ranging from matrix factorization and autoencoder-based to graph filtering-based methods. Recently, lightweight methods that require almost no training have been recently proposed to reduce overall computation. However, existing methods still have room to improve the trade-offs among accuracy, efficiency, and robustness. In particular, there are no well-designed closed-form studies for \emph{balanced} CF in terms of the aforementioned trade-offs. In this paper, we design SVD-AE, a simple yet effective singular vector decomposition (SVD)-based linear autoencoder, whose closed-form solution can be defined based on SVD for CF. SVD-AE does not require iterative training processes as its closed-form solution can be calculated at once. Furthermore, given the noisy nature of the rating matrix, we explore the robustness against such noisy interactions of existing CF methods and our SVD-AE. As a result, we demonstrate that our simple design choice based on truncated SVD can be used to strengthen the noise robustness of the recommendation while improving efficiency. Code is available at https://github.com/seoyoungh/svd-ae.
Towards Fair Graph Anomaly Detection: Problem, New Datasets, and Evaluation
Feb 25, 2024



The Fair Graph Anomaly Detection (FairGAD) problem aims to accurately detect anomalous nodes in an input graph while ensuring fairness and avoiding biased predictions against individuals from sensitive subgroups such as gender or political leanings. Fairness in graphs is particularly crucial in anomaly detection areas such as misinformation detection in search/ranking systems, where decision outcomes can significantly affect individuals. However, the current literature does not comprehensively discuss this problem, nor does it provide realistic datasets that encompass actual graph structures, anomaly labels, and sensitive attributes for research in FairGAD. To bridge this gap, we introduce a formal definition of the FairGAD problem and present two novel graph datasets constructed from the globally prominent social media platforms Reddit and Twitter. These datasets comprise 1.2 million and 400,000 edges associated with 9,000 and 47,000 nodes, respectively, and leverage political leanings as sensitive attributes and misinformation spreaders as anomaly labels. We demonstrate that our FairGAD datasets significantly differ from the synthetic datasets used currently by the research community. These new datasets offer significant values for FairGAD by providing realistic data that captures the intricacies of social networks. Using our datasets, we investigate the performance-fairness trade-off in eleven existing GAD and non-graph AD methods on five state-of-the-art fairness methods, which sheds light on their effectiveness and limitations in addressing the FairGAD problem.
Trustworthiness-Driven Graph Convolutional Networks for Signed Network Embedding
Sep 02, 2023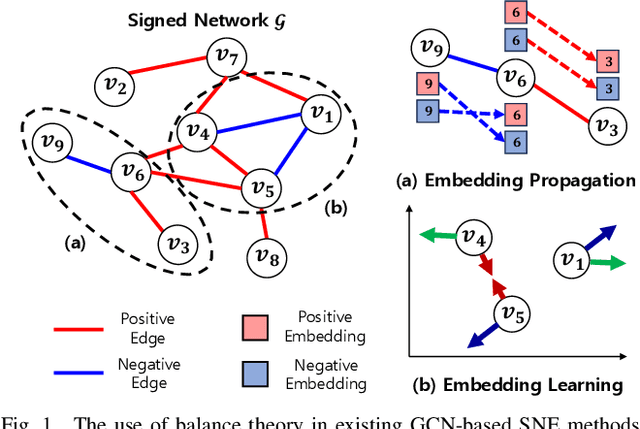

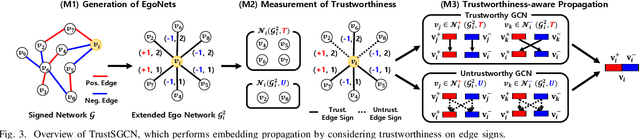
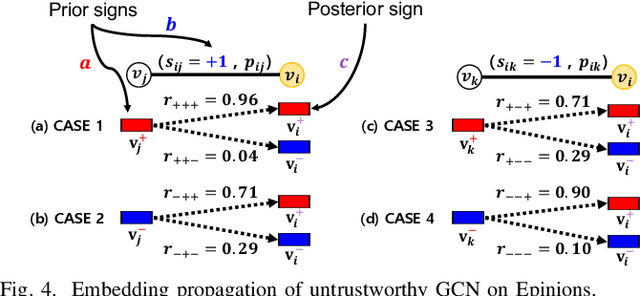
The problem of representing nodes in a signed network as low-dimensional vectors, known as signed network embedding (SNE), has garnered considerable attention in recent years. While several SNE methods based on graph convolutional networks (GCN) have been proposed for this problem, we point out that they significantly rely on the assumption that the decades-old balance theory always holds in the real-world. To address this limitation, we propose a novel GCN-based SNE approach, named as TrustSGCN, which corrects for incorrect embedding propagation in GCN by utilizing the trustworthiness on edge signs for high-order relationships inferred by the balance theory. The proposed approach consists of three modules: (M1) generation of each node's extended ego-network; (M2) measurement of trustworthiness on edge signs; and (M3) trustworthiness-aware propagation of embeddings. Furthermore, TrustSGCN learns the node embeddings by leveraging two well-known societal theories, i.e., balance and status. The experiments on four real-world signed network datasets demonstrate that TrustSGCN consistently outperforms five state-of-the-art GCN-based SNE methods. The code is available at https://github.com/kmj0792/TrustSGCN.