 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Small Step with Fingerprints, One Giant Leap for emph{De Novo} Molecule Generation from Mass Spectra
Aug 06, 2025
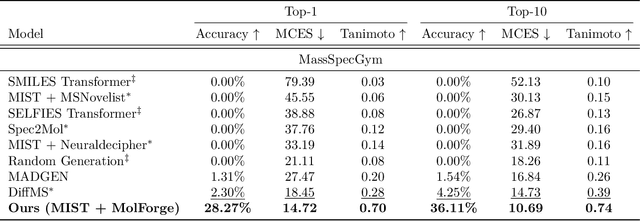

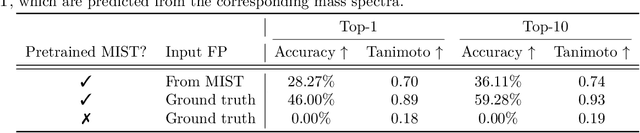
A common approach to the \emph{de novo} molecular generation problem from mass spectra involves a two-stage pipeline: (1) encoding mass spectra into molecular fingerprints, followed by (2) decoding these fingerprints into molecular structures. In our work, we adopt \textsc{MIST}~\citep{MISTgoldmanAnnotatingMetaboliteMass2023} as the encoder and \textsc{MolForge}~\citep{ucakReconstructionLosslessMolecular2023} as the decoder, leveraging pretraining to enhance performance. Notably, pretraining \textsc{MolForge} proves especially effective, enabling it to serve as a robust fingerprint-to-structure decoder. Additionally, instead of passing the probability of each bit in the fingerprint, thresholding the probabilities as a step function helps focus the decoder on the presence of substructures, improving recovery of accurate molecular structures even when the fingerprints predicted by \textsc{MIST} only moderately resembles the ground truth in terms of Tanimoto similarity. This combination of encoder and decoder results in a tenfold improvement over previous state-of-the-art methods, generating top-1 28\% / top-10 36\% of molecular structures correctly from mass spectra. We position this pipeline as a strong baseline for future research in \emph{de novo} molecule elucidation from mass spectra.
Towards Fair Graph Anomaly Detection: Problem, New Datasets, and Evaluation
Feb 25, 2024



The Fair Graph Anomaly Detection (FairGAD) problem aims to accurately detect anomalous nodes in an input graph while ensuring fairness and avoiding biased predictions against individuals from sensitive subgroups such as gender or political leanings. Fairness in graphs is particularly crucial in anomaly detection areas such as misinformation detection in search/ranking systems, where decision outcomes can significantly affect individuals. However, the current literature does not comprehensively discuss this problem, nor does it provide realistic datasets that encompass actual graph structures, anomaly labels, and sensitive attributes for research in FairGAD. To bridge this gap, we introduce a formal definition of the FairGAD problem and present two novel graph datasets constructed from the globally prominent social media platforms Reddit and Twitter. These datasets comprise 1.2 million and 400,000 edges associated with 9,000 and 47,000 nodes, respectively, and leverage political leanings as sensitive attributes and misinformation spreaders as anomaly labels. We demonstrate that our FairGAD datasets significantly differ from the synthetic datasets used currently by the research community. These new datasets offer significant values for FairGAD by providing realistic data that captures the intricacies of social networks. Using our datasets, we investigate the performance-fairness trade-off in eleven existing GAD and non-graph AD methods on five state-of-the-art fairness methods, which sheds light on their effectiveness and limitations in addressing the FairGAD problem.
Chemical Structure Elucidation from Mass Spectrometry by Matching Substructures
Nov 17, 2018

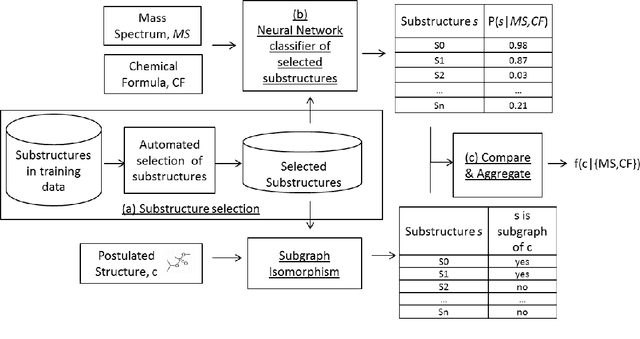
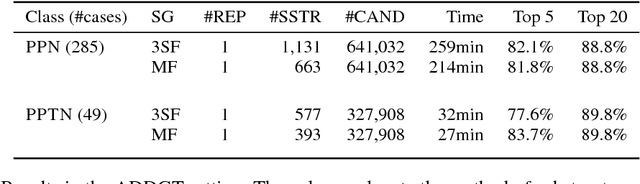
Chemical structure elucidation is a serious bottleneck in analytical chemistry today. We address the problem of identifying an unknown chemical threat given its mass spectrum and its chemical formula, a task which might take well trained chemists several days to complete. Given a chemical formula, there could be over a million possible candidate structures. We take a data driven approach to rank these structures by using neural networks to predict the presence of substructures given the mass spectrum, and matching these substructures to the candidate structures. Empirically, we evaluate our approach on a data set of chemical agents built for unknown chemical threat identification. We show that our substructure classifiers can attain over 90% micro F1-score, and we can find the correct structure among the top 20 candidates in 88% and 71% of test cases for two compound classes.