 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Training Grounded LLMs with Verifiable Rewards
Jun 18, 2025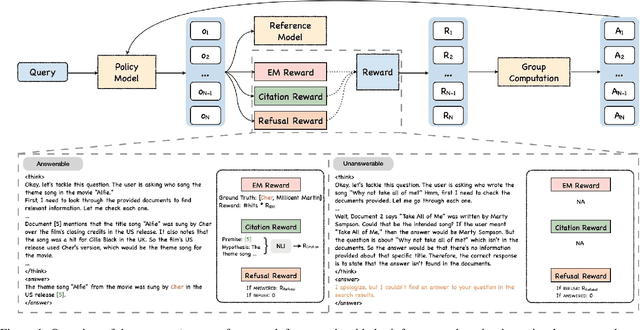
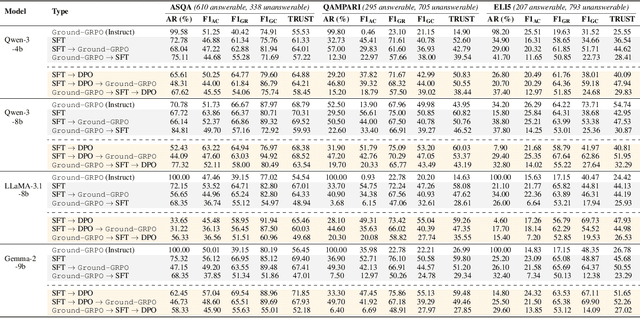
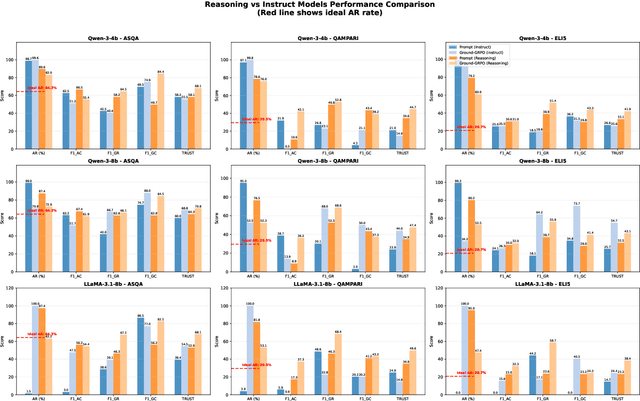
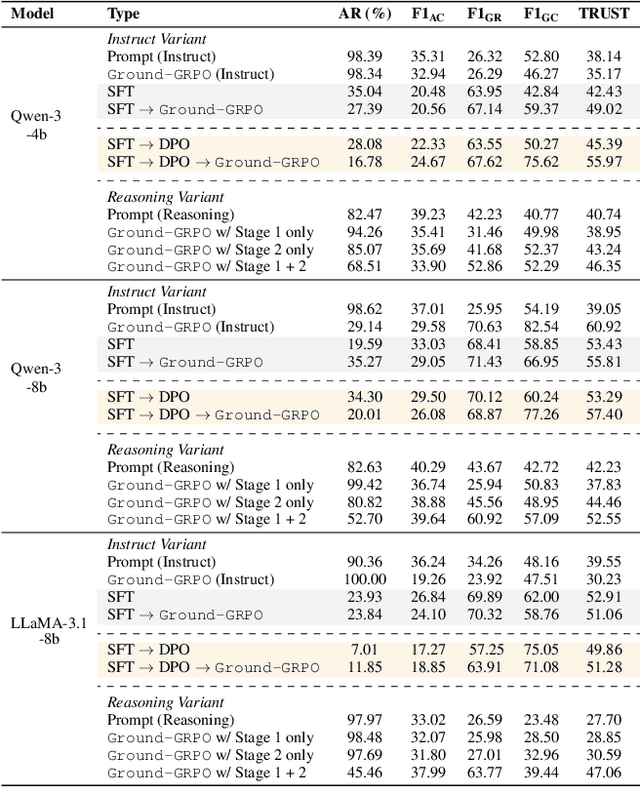
Generating grounded and trustworthy responses remains a key challenge for large language models (LLMs). While retrieval-augmented generation (RAG) with citation-based grounding holds promise, instruction-tuned models frequently fail even in straightforward scenarios: missing explicitly stated answers, citing incorrectly, or refusing when evidence is available. In this work, we explore how reinforcement learning (RL) and internal reasoning can enhance grounding in LLMs. We use the GRPO (Group Relative Policy Optimization) method to train models using verifiable outcome-based rewards targeting answer correctness, citation sufficiency, and refusal quality, without requiring gold reasoning traces or expensive annotations. Through comprehensive experiments across ASQA, QAMPARI, ELI5, and ExpertQA we show that reasoning-augmented models significantly outperform instruction-only variants, especially in handling unanswerable queries and generating well-cited responses. A two-stage training setup, first optimizing answer and citation behavior and then refusal, further improves grounding by stabilizing the learning signal. Additionally, we revisit instruction tuning via GPT-4 distillation and find that combining it with GRPO enhances performance on long-form, generative QA tasks. Overall, our findings highlight the value of reasoning, stage-wise optimization, and outcome-driven RL for building more verifiable and reliable LLMs.
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
Sep 17, 2024



LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (up 10.7), QAMPARI (up 29.2) and ELI5 (up 14.9). We release our code at: https://github.com/declare-lab/trust-align.
Multi-label and Multi-target Sampling of Machine Annotation for Computational Stance Detection
Nov 08, 2023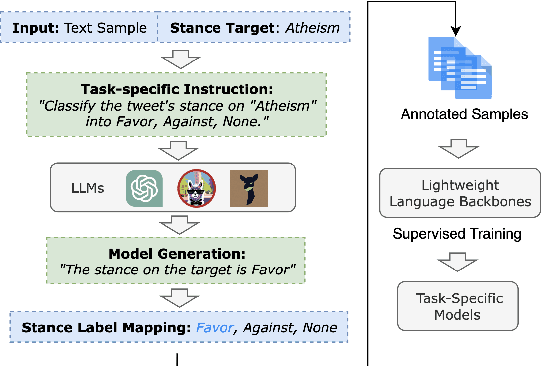



Data collection from manual labeling provides domain-specific and task-aligned supervision for data-driven approaches, and a critical mass of well-annotated resources is required to achieve reasonable performance in natural language processing tasks. However, manual annotations are often challenging to scale up in terms of time and budget, especially when domain knowledge, capturing subtle semantic features, and reasoning steps are needed. In this paper, we investigate the efficacy of leveraging large language models on automated labeling for computational stance detection. We empirically observe that while large language models show strong potential as an alternative to human annotators, their sensitivity to task-specific instructions and their intrinsic biases pose intriguing yet unique challenges in machine annotation. We introduce a multi-label and multi-target sampling strategy to optimize the annotation quality. Experimental results on the benchmark stance detection corpora show that our method can significantly improve performance and learning efficacy.
Guiding Computational Stance Detection with Expanded Stance Triangle Framework
May 31, 2023
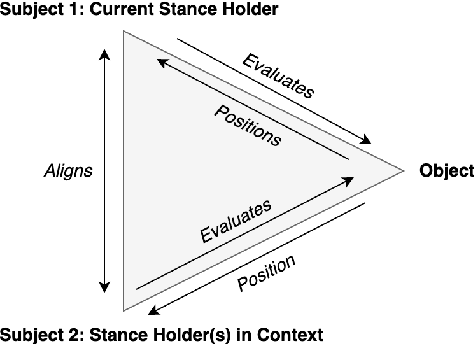
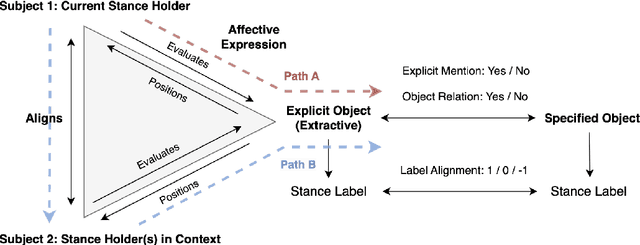
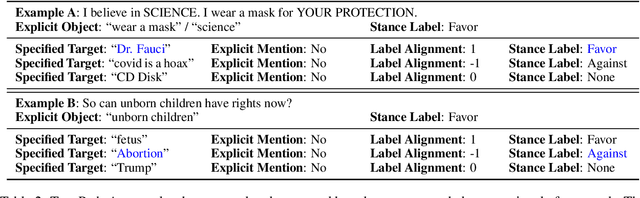
Stance detection determines whether the author of a piece of text is in favor of, against, or neutral towards a specified target, and can be used to gain valuable insights into social media. The ubiquitous indirect referral of targets makes this task challenging, as it requires computational solutions to model semantic features and infer the corresponding implications from a literal statement. Moreover, the limited amount of available training data leads to subpar performance in out-of-domain and cross-target scenarios, as data-driven approaches are prone to rely on superficial and domain-specific features. In this work, we decompose the stance detection task from a linguistic perspective, and investigate key components and inference paths in this task. The stance triangle is a generic linguistic framework previously proposed to describe the fundamental ways people express their stance. We further expand it by characterizing the relationship between explicit and implicit objects. We then use the framework to extend one single training corpus with additional annotation. Experimental results show that strategically-enriched data can significantly improve the performance on out-of-domain and cross-target evaluation.
Interpretable Rumor Detection in Microblogs by Attending to User Interactions
Jan 29, 2020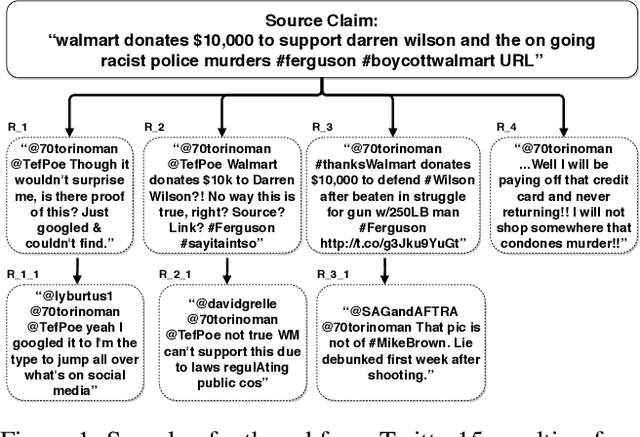
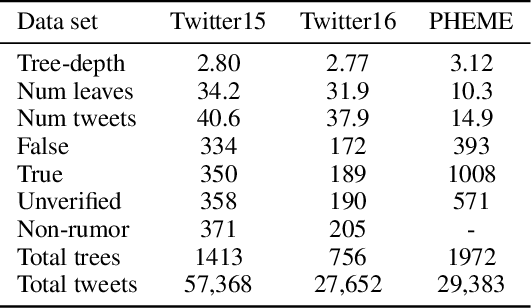
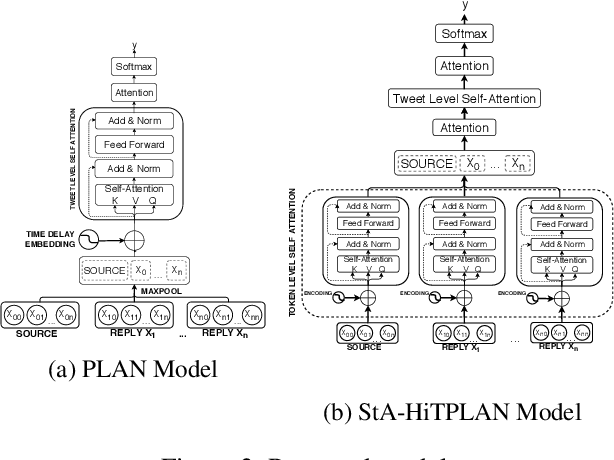
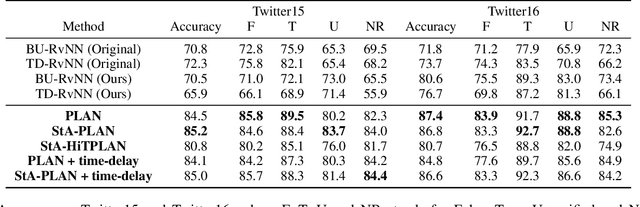
We address rumor detection by learning to differentiate between the community's response to real and fake claims in microblogs. Existing state-of-the-art models are based on tree models that model conversational trees. However, in social media, a user posting a reply might be replying to the entire thread rather than to a specific user. We propose a post-level attention model (PLAN) to model long distance interactions between tweets with the multi-head attention mechanism in a transformer network. We investigated variants of this model: (1) a structure aware self-attention model (StA-PLAN) that incorporates tree structure information in the transformer network, and (2) a hierarchical token and post-level attention model (StA-HiTPLAN) that learns a sentence representation with token-level self-attention. To the best of our knowledge, we are the first to evaluate our models on two rumor detection data sets: the PHEME data set as well as the Twitter15 and Twitter16 data sets. We show that our best models outperform current state-of-the-art models for both data sets. Moreover, the attention mechanism allows us to explain rumor detection predictions at both token-level and post-level.
Chemical Structure Elucidation from Mass Spectrometry by Matching Substructures
Nov 17, 2018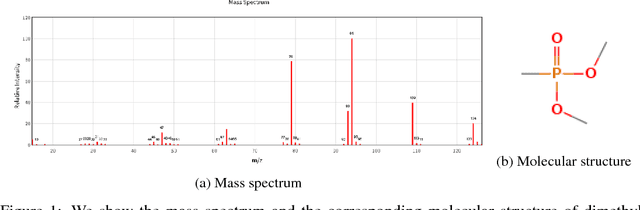

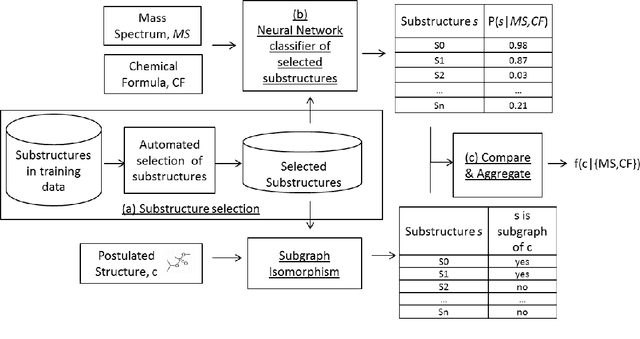
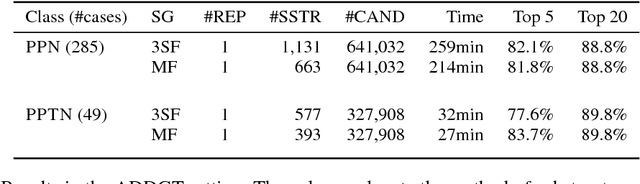
Chemical structure elucidation is a serious bottleneck in analytical chemistry today. We address the problem of identifying an unknown chemical threat given its mass spectrum and its chemical formula, a task which might take well trained chemists several days to complete. Given a chemical formula, there could be over a million possible candidate structures. We take a data driven approach to rank these structures by using neural networks to predict the presence of substructures given the mass spectrum, and matching these substructures to the candidate structures. Empirically, we evaluate our approach on a data set of chemical agents built for unknown chemical threat identification. We show that our substructure classifiers can attain over 90% micro F1-score, and we can find the correct structure among the top 20 candidates in 88% and 71% of test cases for two compound classes.
Universal Dependencies Parsing for Colloquial Singaporean English
May 18, 2017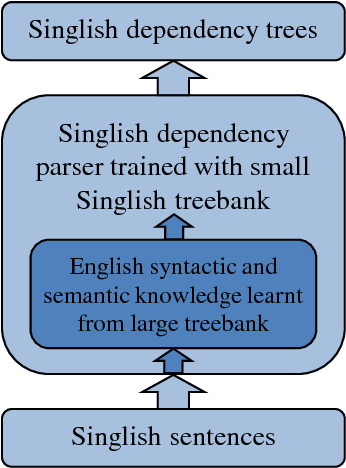
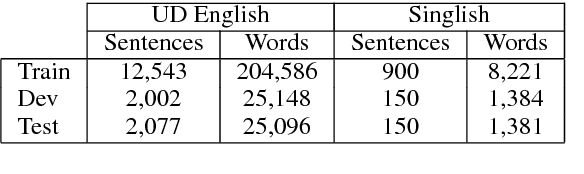
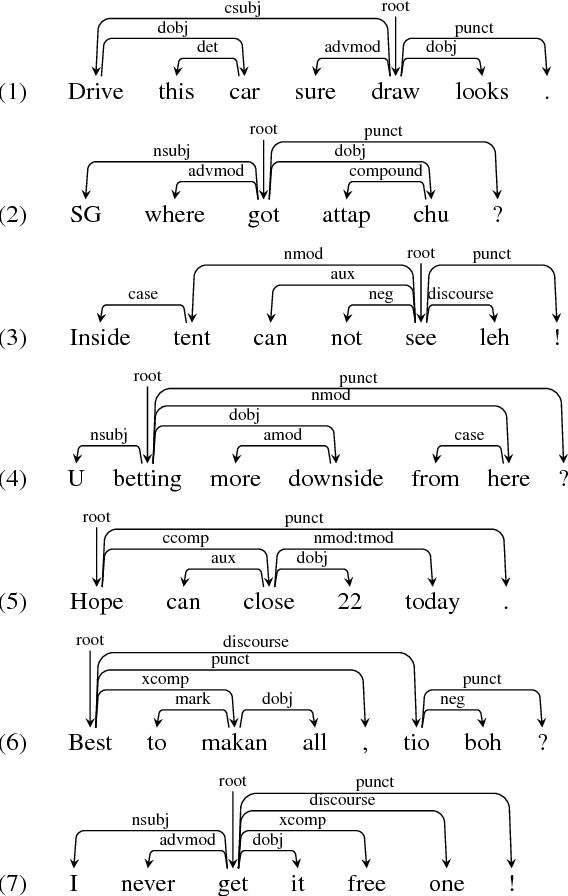

Singlish can be interesting to the ACL community both linguistically as a major creole based on English, and computationally for information extraction and sentiment analysis of regional social media. We investigate dependency parsing of Singlish by constructing a dependency treebank under the Universal Dependencies scheme, and then training a neural network model by integrating English syntactic knowledge into a state-of-the-art parser trained on the Singlish treebank. Results show that English knowledge can lead to 25% relative error reduction, resulting in a parser of 84.47% accuracies. To the best of our knowledge, we are the first to use neural stacking to improve cross-lingual dependency parsing on low-resource languages. We make both our annotation and parser available for further research.
Relaxed Survey Propagation for The Weighted Maximum Satisfiability Problem
Jan 15, 2014
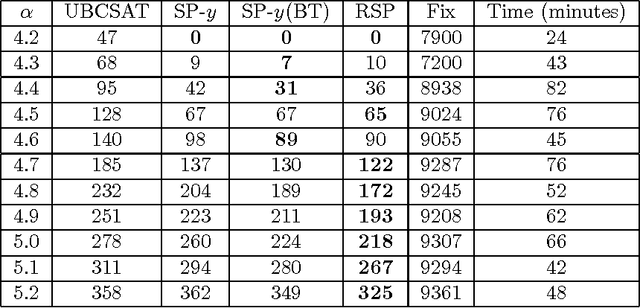
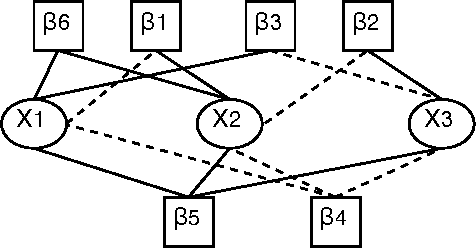
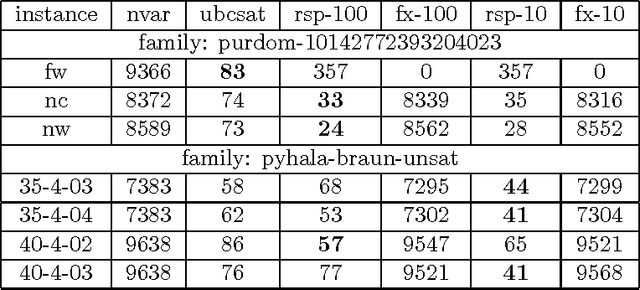
The survey propagation (SP) algorithm has been shown to work well on large instances of the random 3-SAT problem near its phase transition. It was shown that SP estimates marginals over covers that represent clusters of solutions. The SP-y algorithm generalizes SP to work on the maximum satisfiability (Max-SAT) problem, but the cover interpretation of SP does not generalize to SP-y. In this paper, we formulate the relaxed survey propagation (RSP) algorithm, which extends the SP algorithm to apply to the weighted Max-SAT problem. We show that RSP has an interpretation of estimating marginals over covers violating a set of clauses with minimal weight. This naturally generalizes the cover interpretation of SP. Empirically, we show that RSP outperforms SP-y and other state-of-the-art Max-SAT solvers on random Max-SAT instances. RSP also outperforms state-of-the-art weighted Max-SAT solvers on random weighted Max-SAT instances.
A Split-Merge Framework for Comparing Clusterings
Sep 04, 2012



Clustering evaluation measures are frequently used to evaluate the performance of algorithms. However, most measures are not properly normalized and ignore some information in the inherent structure of clusterings. We model the relation between two clusterings as a bipartite graph and propose a general component-based decomposition formula based on the components of the graph. Most existing measures are examples of this formula. In order to satisfy consistency in the component, we further propose a split-merge framework for comparing clusterings of different data sets. Our framework gives measures that are conditionally normalized, and it can make use of data point information, such as feature vectors and pairwise distances. We use an entropy-based instance of the framework and a coreference resolution data set to demonstrate empirically the utility of our framework over other measures.
Optimizing F-measure: A Tale of Two Approaches
Jun 18, 2012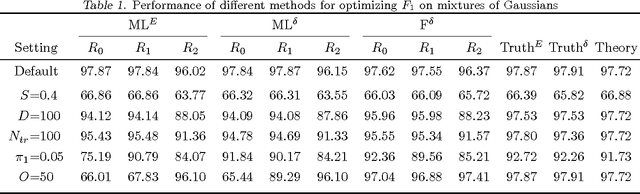
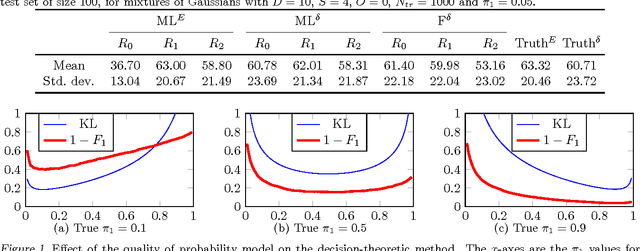
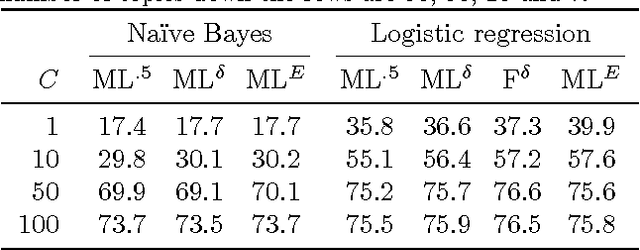
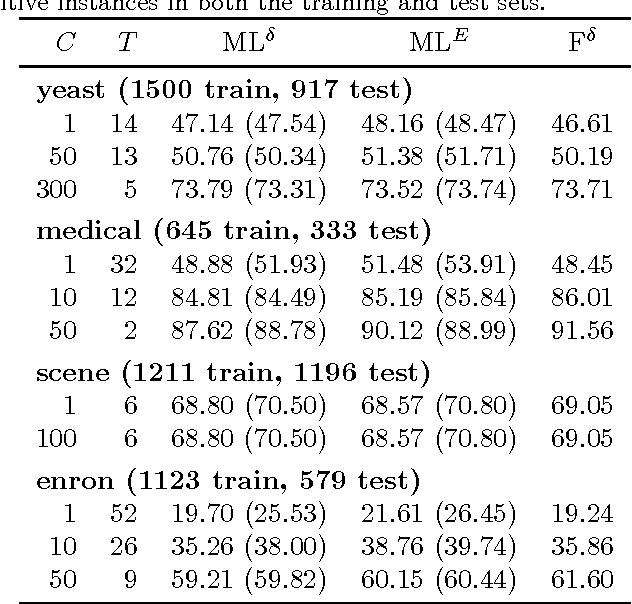
F-measures are popular performance metrics, particularly for tasks with imbalanced data sets. Algorithms for learning to maximize F-measures follow two approaches: the empirical utility maximization (EUM) approach learns a classifier having optimal performance on training data, while the decision-theoretic approach learns a probabilistic model and then predicts labels with maximum expected F-measure. In this paper, we investigate the theoretical justifications and connections for these two approaches, and we study the conditions under which one approach is preferable to the other using synthetic and real datasets. Given accurate models, our results suggest that the two approaches are asymptotically equivalent given large training and test sets. Nevertheless, empirically, the EUM approach appears to be more robust against model misspecification, and given a good model, the decision-theoretic approach appears to be better for handling rare classes and a common domain adaptation scenario.