 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Functional Fusion: A New Class of Strategic Backdoor in Dynamic Prompt Architectures
May 19, 2026Existing ViT backdoor attacks based on backbone-overwriting full-tuning are computationally expensive and inflict performance degradation. This has forced adversaries towards the Visual Parameter-Efficient Fine-Tuning (PEFT) paradigm, dominated by adapter-based (e.g., LoRA) and prompt-based (e.g., VPT) approaches. While adapter security has seen initial study, the risks of the burgeoning prompt-based ecosystem remain critically unexplored. We fill this critical gap, exposing how the evolution of VPT towards dynamic and context-aware architectures can facilitate a far more dangerous and emergent threat. This vulnerability arises even though these dynamic modules unlock superior benign performance. We propose VIPER, an attack framework built on a lightweight, dynamic Visual Prompt Generator (VPG) that demonstrates this vulnerability. Critically, this dynamic architecture enables Functional Fusion: an emergent phenomenon where malicious logic and benign task utility are tightly fused into the same sparse, high-magnitude parameter core. This fusion creates a formidable ``hostage" dilemma, as pruning the attack necessarily destroys the benign performance. Comprehensive evaluations show VIPER effectively addresses the attacker's trilemma: VIPER not only achieves state-of-the-art performance on clean data, but also maintains near-100% ASR even under 90% VPG-module pruning (where LoRA attacks collapse), while adding only an imperceptible 0.06ms (1.16%) of inference latency. VIPER's results, driven by Functional Fusion, expose a new, paradigm-level risk in dynamic prompt architectures.
DeepTracer: Tracing Stolen Model via Deep Coupled Watermarks
Nov 12, 2025Model watermarking techniques can embed watermark information into the protected model for ownership declaration by constructing specific input-output pairs. However, existing watermarks are easily removed when facing model stealing attacks, and make it difficult for model owners to effectively verify the copyright of stolen models. In this paper, we analyze the root cause of the failure of current watermarking methods under model stealing scenarios and then explore potential solutions. Specifically, we introduce a robust watermarking framework, DeepTracer, which leverages a novel watermark samples construction method and a same-class coupling loss constraint. DeepTracer can incur a high-coupling model between watermark task and primary task that makes adversaries inevitably learn the hidden watermark task when stealing the primary task functionality. Furthermore, we propose an effective watermark samples filtering mechanism that elaborately select watermark key samples used in model ownership verification to enhance the reliability of watermarks. Extensive experiments across multiple datasets and models demonstrate that our method surpasses existing approaches in defending against various model stealing attacks, as well as watermark attacks, and achieves new state-of-the-art effectiveness and robustness.
Value-Aligned Prompt Moderation via Zero-Shot Agentic Rewriting for Safe Image Generation
Nov 12, 2025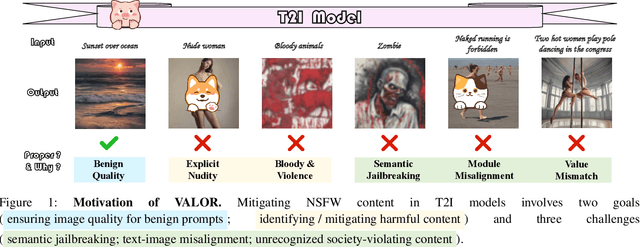
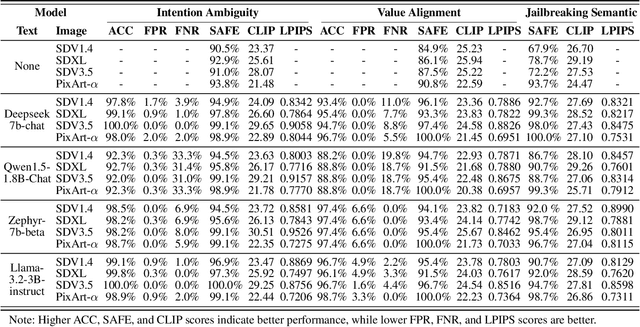


Generative vision-language models like Stable Diffusion demonstrate remarkable capabilities in creative media synthesis, but they also pose substantial risks of producing unsafe, offensive, or culturally inappropriate content when prompted adversarially. Current defenses struggle to align outputs with human values without sacrificing generation quality or incurring high costs. To address these challenges, we introduce VALOR (Value-Aligned LLM-Overseen Rewriter), a modular, zero-shot agentic framework for safer and more helpful text-to-image generation. VALOR integrates layered prompt analysis with human-aligned value reasoning: a multi-level NSFW detector filters lexical and semantic risks; a cultural value alignment module identifies violations of social norms, legality, and representational ethics; and an intention disambiguator detects subtle or indirect unsafe implications. When unsafe content is detected, prompts are selectively rewritten by a large language model under dynamic, role-specific instructions designed to preserve user intent while enforcing alignment. If the generated image still fails a safety check, VALOR optionally performs a stylistic regeneration to steer the output toward a safer visual domain without altering core semantics. Experiments across adversarial, ambiguous, and value-sensitive prompts show that VALOR significantly reduces unsafe outputs by up to 100.00% while preserving prompt usefulness and creativity. These results highlight VALOR as a scalable and effective approach for deploying safe, aligned, and helpful image generation systems in open-world settings.
AILoRA: Function-Aware Asymmetric Initialization for Low-Rank Adaptation of Large Language Models
Oct 09, 2025Parameter-efficient finetuning (PEFT) aims to mitigate the substantial computational and memory overhead involved in adapting large-scale pretrained models to diverse downstream tasks. Among numerous PEFT strategies, Low-Rank Adaptation (LoRA) has emerged as one of the most widely adopted approaches due to its robust empirical performance and low implementation complexity. In practical deployment, LoRA is typically applied to the $W^Q$ and $W^V$ projection matrices of self-attention modules, enabling an effective trade-off between model performance and parameter efficiency. While LoRA has achieved considerable empirical success, it still encounters challenges such as suboptimal performance and slow convergence. To address these limitations, we introduce \textbf{AILoRA}, a novel parameter-efficient method that incorporates function-aware asymmetric low-rank priors. Our empirical analysis reveals that the projection matrices $W^Q$ and $W^V$ in the self-attention mechanism exhibit distinct parameter characteristics, stemming from their functional differences. Specifically, $W^Q$ captures task-specific semantic space knowledge essential for attention distributions computation, making its parameters highly sensitive to downstream task variations. In contrast, $W^V$ encodes token-level feature representations that tend to remain stable across tasks and layers. Leveraging these insights, AILoRA performs a function-aware initialization by injecting the principal components of $W^Q$ to retain task-adaptive capacity, and the minor components of $W^V$ to preserve generalizable feature representations. This asymmetric initialization strategy enables LoRA modules to better capture the specialized roles of attention parameters, thereby enhancing both finetuning performance and convergence efficiency.
IPBA: Imperceptible Perturbation Backdoor Attack in Federated Self-Supervised Learning
Aug 11, 2025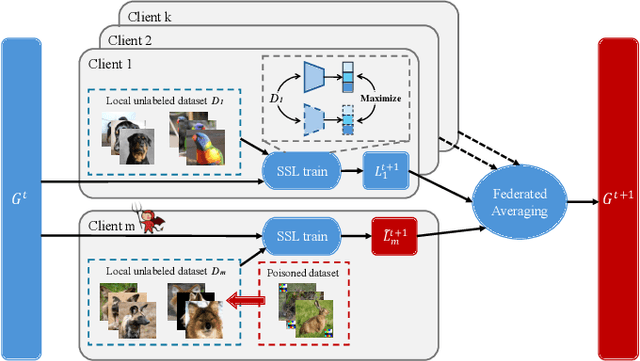
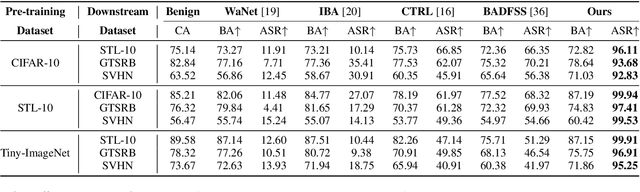

Federated self-supervised learning (FSSL) combines the advantages of decentralized modeling and unlabeled representation learning, serving as a cutting-edge paradigm with strong potential for scalability and privacy preservation. Although FSSL has garnered increasing attention, research indicates that it remains vulnerable to backdoor attacks. Existing methods generally rely on visually obvious triggers, which makes it difficult to meet the requirements for stealth and practicality in real-world deployment. In this paper, we propose an imperceptible and effective backdoor attack method against FSSL, called IPBA. Our empirical study reveals that existing imperceptible triggers face a series of challenges in FSSL, particularly limited transferability, feature entanglement with augmented samples, and out-of-distribution properties. These issues collectively undermine the effectiveness and stealthiness of traditional backdoor attacks in FSSL. To overcome these challenges, IPBA decouples the feature distributions of backdoor and augmented samples, and introduces Sliced-Wasserstein distance to mitigate the out-of-distribution properties of backdoor samples, thereby optimizing the trigger generation process. Our experimental results on several FSSL scenarios and datasets show that IPBA significantly outperforms existing backdoor attack methods in performance and exhibits strong robustness under various defense mechanisms.
Think Hierarchically, Act Dynamically: Hierarchical Multi-modal Fusion and Reasoning for Vision-and-Language Navigation
Apr 23, 2025Vision-and-Language Navigation (VLN) aims to enable embodied agents to follow natural language instructions and reach target locations in real-world environments. While prior methods often rely on either global scene representations or object-level features, these approaches are insufficient for capturing the complex interactions across modalities required for accurate navigation. In this paper, we propose a Multi-level Fusion and Reasoning Architecture (MFRA) to enhance the agent's ability to reason over visual observations, language instructions and navigation history. Specifically, MFRA introduces a hierarchical fusion mechanism that aggregates multi-level features-ranging from low-level visual cues to high-level semantic concepts-across multiple modalities. We further design a reasoning module that leverages fused representations to infer navigation actions through instruction-guided attention and dynamic context integration. By selectively capturing and combining relevant visual, linguistic, and temporal signals, MFRA improves decision-making accuracy in complex navigation scenarios. Extensive experiments on benchmark VLN datasets including REVERIE, R2R, and SOON demonstrate that MFRA achieves superior performance compared to state-of-the-art methods, validating the effectiveness of multi-level modal fusion for embodied navigation.
Buster: Incorporating Backdoor Attacks into Text Encoder to Mitigate NSFW Content Generation
Dec 10, 2024



In the digital age, the proliferation of deep learning models has led to significant concerns about the generation of Not Safe for Work (NSFW) content. Existing defense methods primarily involve model fine-tuning and post-hoc content moderation. However, these approaches often lack scalability in eliminating harmful content, degrade the quality of benign image generation, or incur high inference costs. To tackle these challenges, we propose an innovative framework called \textbf{Buster}, which injects backdoor attacks into the text encoder to prevent NSFW content generation. Specifically, Buster leverages deep semantic information rather than explicit prompts as triggers, redirecting NSFW prompts towards targeted benign prompts. This approach demonstrates exceptional resilience and scalability in mitigating NSFW content. Remarkably, Buster fine-tunes the text encoder of Text-to-Image models within just five minutes, showcasing high efficiency. Our extensive experiments reveal that Buster outperforms all other baselines, achieving superior NSFW content removal rate while preserving the quality of harmless images.
CipherDM: Secure Three-Party Inference for Diffusion Model Sampling
Sep 09, 2024



Diffusion Models (DMs) achieve state-of-the-art synthesis results in image generation and have been applied to various fields. However, DMs sometimes seriously violate user privacy during usage, making the protection of privacy an urgent issue. Using traditional privacy computing schemes like Secure Multi-Party Computation (MPC) directly in DMs faces significant computation and communication challenges. To address these issues, we propose CipherDM, the first novel, versatile and universal framework applying MPC technology to DMs for secure sampling, which can be widely implemented on multiple DM based tasks. We thoroughly analyze sampling latency breakdown, find time-consuming parts and design corresponding secure MPC protocols for computing nonlinear activations including SoftMax, SiLU and Mish. CipherDM is evaluated on popular architectures (DDPM, DDIM) using MNIST dataset and on SD deployed by diffusers. Compared to direct implementation on SPU, our approach improves running time by approximately 1.084\times \sim 2.328\times, and reduces communication costs by approximately 1.212\times \sim 1.791\times.
Federated Learning with Limited Node Labels
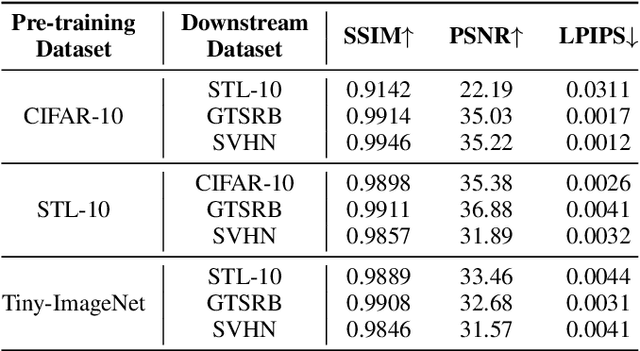
Jun 18, 2024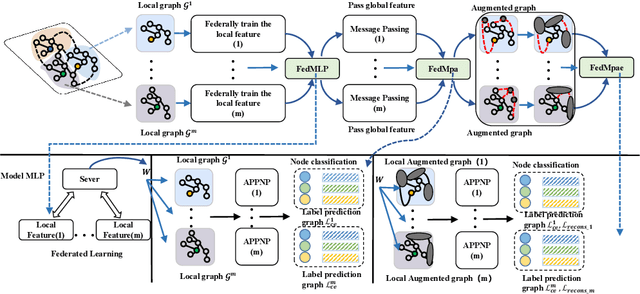
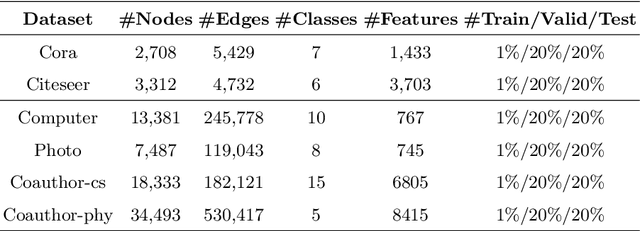
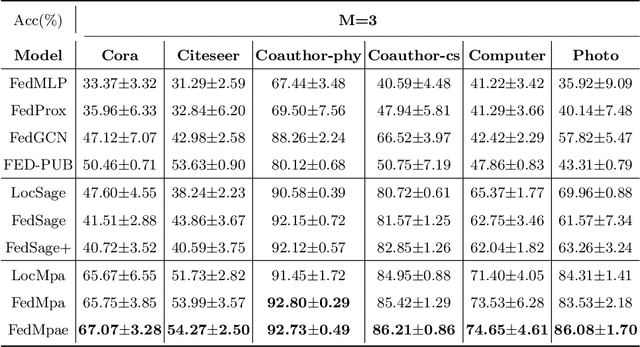
Subgraph federated learning (SFL) is a research methodology that has gained significant attention for its potential to handle distributed graph-structured data. In SFL, the local model comprises graph neural networks (GNNs) with a partial graph structure. However, some SFL models have overlooked the significance of missing cross-subgraph edges, which can lead to local GNNs being unable to message-pass global representations to other parties' GNNs. Moreover, existing SFL models require substantial labeled data, which limits their practical applications. To overcome these limitations, we present a novel SFL framework called FedMpa that aims to learn cross-subgraph node representations. FedMpa first trains a multilayer perceptron (MLP) model using a small amount of data and then propagates the federated feature to the local structures. To further improve the embedding representation of nodes with local subgraphs, we introduce the FedMpae method, which reconstructs the local graph structure with an innovation view that applies pooling operation to form super-nodes. Our extensive experiments on six graph datasets demonstrate that FedMpa is highly effective in node classification. Furthermore, our ablation experiments verify the effectiveness of FedMpa.
Practical and General Backdoor Attacks against Vertical Federated Learning
Jun 19, 2023Federated learning (FL), which aims to facilitate data collaboration across multiple organizations without exposing data privacy, encounters potential security risks. One serious threat is backdoor attacks, where an attacker injects a specific trigger into the training dataset to manipulate the model's prediction. Most existing FL backdoor attacks are based on horizontal federated learning (HFL), where the data owned by different parties have the same features. However, compared to HFL, backdoor attacks on vertical federated learning (VFL), where each party only holds a disjoint subset of features and the labels are only owned by one party, are rarely studied. The main challenge of this attack is to allow an attacker without access to the data labels, to perform an effective attack. To this end, we propose BadVFL, a novel and practical approach to inject backdoor triggers into victim models without label information. BadVFL mainly consists of two key steps. First, to address the challenge of attackers having no knowledge of labels, we introduce a SDD module that can trace data categories based on gradients. Second, we propose a SDP module that can improve the attack's effectiveness by enhancing the decision dependency between the trigger and attack target. Extensive experiments show that BadVFL supports diverse datasets and models, and achieves over 93% attack success rate with only 1% poisoning rate.