 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirGlove: Exploring Egocentric 3D Hand Tracking and Appearance Generalization for Sensing Gloves
Feb 05, 2026Sensing gloves have become important tools for teleoperation and robotic policy learning as they are able to provide rich signals like speed, acceleration and tactile feedback. A common approach to track gloved hands is to directly use the sensor signals (e.g., angular velocity, gravity orientation) to estimate 3D hand poses. However, sensor-based tracking can be restrictive in practice as the accuracy is often impacted by sensor signal and calibration quality. Recent advances in vision-based approaches have achieved strong performance on human hands via large-scale pre-training, but their performance on gloved hands with distinct visual appearances remains underexplored. In this work, we present the first systematic evaluation of vision-based hand tracking models on gloved hands under both zero-shot and fine-tuning setups. Our analysis shows that existing bare-hand models suffer from substantial performance degradation on sensing gloves due to large appearance gap between bare-hand and glove designs. We therefore propose AirGlove, which leverages existing gloves to generalize the learned glove representations towards new gloves with limited data. Experiments with multiple sensing gloves show that AirGlove effectively generalizes the hand pose models to new glove designs and achieves a significant performance boost over the compared schemes.
Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
Jan 27, 2026Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in vision-language representation learning, powering diverse downstream tasks and serving as the default vision backbone in multimodal large language models (MLLMs). Despite its success, CLIP's dense and opaque latent representations pose significant interpretability challenges. A common assumption is that interpretability and performance are in tension: enforcing sparsity during training degrades accuracy, motivating recent post-hoc approaches such as Sparse Autoencoders (SAEs). However, these post-hoc approaches often suffer from degraded downstream performance and loss of CLIP's inherent multimodal capabilities, with most learned features remaining unimodal. We propose a simple yet effective approach that integrates sparsity directly into CLIP training, yielding representations that are both interpretable and performant. Compared to SAEs, our Sparse CLIP representations preserve strong downstream task performance, achieve superior interpretability, and retain multimodal capabilities. We show that multimodal sparse features enable straightforward semantic concept alignment and reveal training dynamics of how cross-modal knowledge emerges. Finally, as a proof of concept, we train a vision-language model on sparse CLIP representations that enables interpretable, vision-based steering capabilities. Our findings challenge conventional wisdom that interpretability requires sacrificing accuracy and demonstrate that interpretability and performance can be co-optimized, offering a promising design principle for future models.
SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
Jan 21, 2026Large language models (LLMs) have shown growing promise in biomedical research, particularly for knowledge-driven interpretation tasks. However, their ability to reliably reason from gene-level knowledge to functional understanding, a core requirement for knowledge-enhanced cell atlas interpretation, remains largely underexplored. To address this gap, we introduce SciHorizon-GENE, a large-scale gene-centric benchmark constructed from authoritative biological databases. The benchmark integrates curated knowledge for over 190K human genes and comprises more than 540K questions covering diverse gene-to-function reasoning scenarios relevant to cell type annotation, functional interpretation, and mechanism-oriented analysis. Motivated by behavioral patterns observed in preliminary examinations, SciHorizon-GENE evaluates LLMs along four biologically critical perspectives: research attention sensitivity, hallucination tendency, answer completeness, and literature influence, explicitly targeting failure modes that limit the safe adoption of LLMs in biological interpretation pipelines. We systematically evaluate a wide range of state-of-the-art general-purpose and biomedical LLMs, revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations. Our benchmark establishes a systematic foundation for analyzing LLM behavior at the gene scale and offers insights for model selection and development, with direct relevance to knowledge-enhanced biological interpretation.
Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Enhancing Conversational Recommender Systems with Tree-Structured Knowledge and Pretrained Language Models
Nov 16, 2025



Recent advances in pretrained language models (PLMs) have significantly improved conversational recommender systems (CRS), enabling more fluent and context-aware interactions. To further enhance accuracy and mitigate hallucination, many methods integrate PLMs with knowledge graphs (KGs), but face key challenges: failing to fully exploit PLM reasoning over graph relationships, indiscriminately incorporating retrieved knowledge without context filtering, and neglecting collaborative preferences in multi-turn dialogues. To this end, we propose PCRS-TKA, a prompt-based framework employing retrieval-augmented generation to integrate PLMs with KGs. PCRS-TKA constructs dialogue-specific knowledge trees from KGs and serializes them into texts, enabling structure-aware reasoning while capturing rich entity semantics. Our approach selectively filters context-relevant knowledge and explicitly models collaborative preferences using specialized supervision signals. A semantic alignment module harmonizes heterogeneous inputs, reducing noise and enhancing accuracy. Extensive experiments demonstrate that PCRS-TKA consistently outperforms all baselines in both recommendation and conversational quality.
TransLLM: A Unified Multi-Task Foundation Framework for Urban Transportation via Learnable Prompting
Aug 20, 2025Urban transportation systems encounter diverse challenges across multiple tasks, such as traffic forecasting, electric vehicle (EV) charging demand prediction, and taxi dispatch. Existing approaches suffer from two key limitations: small-scale deep learning models are task-specific and data-hungry, limiting their generalizability across diverse scenarios, while large language models (LLMs), despite offering flexibility through natural language interfaces, struggle with structured spatiotemporal data and numerical reasoning in transportation domains. To address these limitations, we propose TransLLM, a unified foundation framework that integrates spatiotemporal modeling with large language models through learnable prompt composition. Our approach features a lightweight spatiotemporal encoder that captures complex dependencies via dilated temporal convolutions and dual-adjacency graph attention networks, seamlessly interfacing with LLMs through structured embeddings. A novel instance-level prompt routing mechanism, trained via reinforcement learning, dynamically personalizes prompts based on input characteristics, moving beyond fixed task-specific templates. The framework operates by encoding spatiotemporal patterns into contextual representations, dynamically composing personalized prompts to guide LLM reasoning, and projecting the resulting representations through specialized output layers to generate task-specific predictions. Experiments across seven datasets and three tasks demonstrate the exceptional effectiveness of TransLLM in both supervised and zero-shot settings. Compared to ten baseline models, it delivers competitive performance on both regression and planning problems, showing strong generalization and cross-task adaptability. Our code is available at https://github.com/BiYunying/TransLLM.
Application-Driven Value Alignment in Agentic AI Systems: Survey and Perspectives
Jun 11, 2025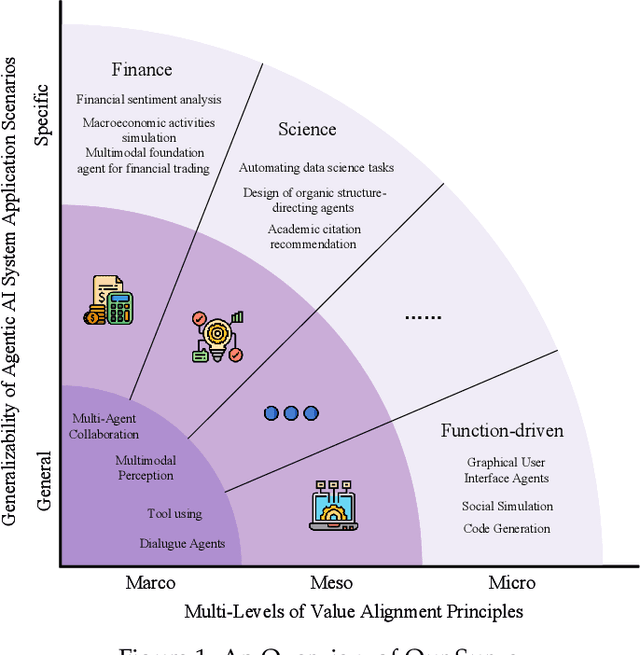
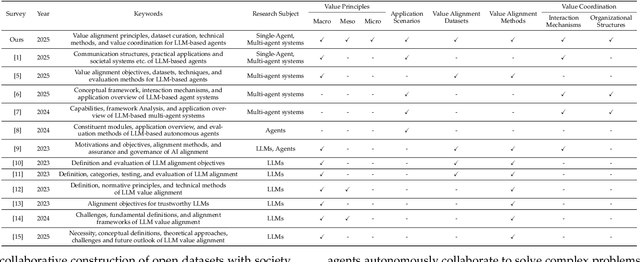
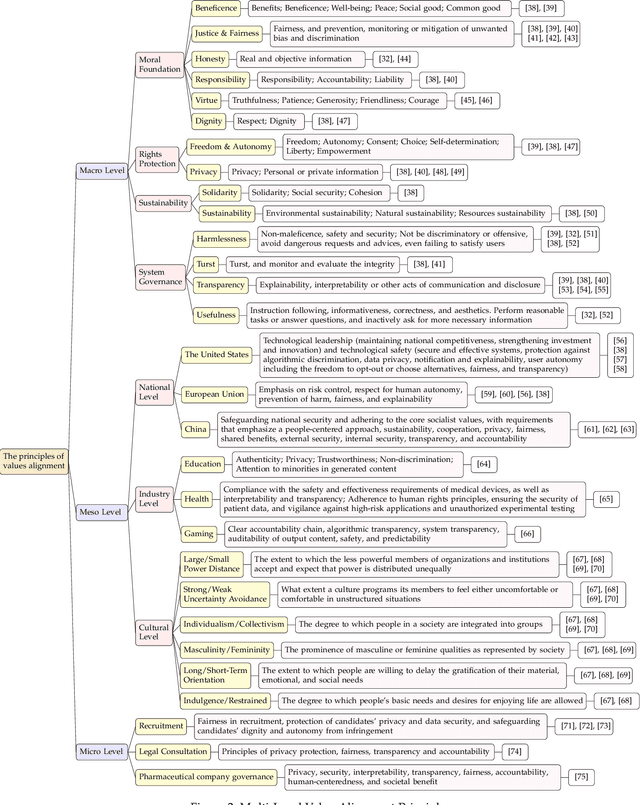
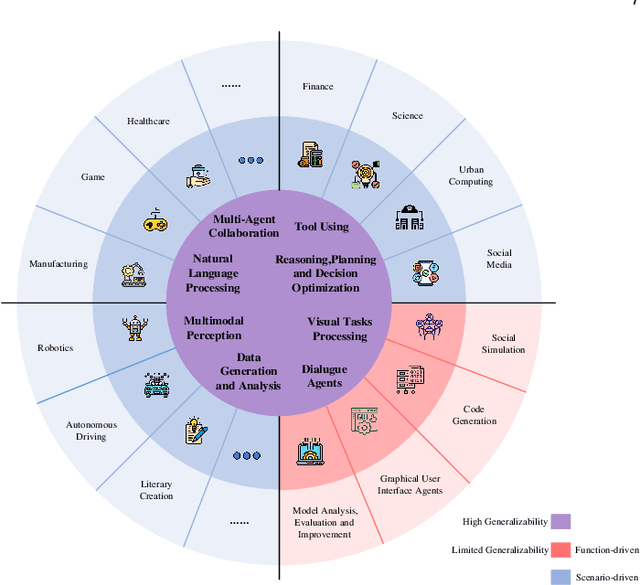
The ongoing evolution of AI paradigms has propelled AI research into the Agentic AI stage. Consequently, the focus of research has shifted from single agents and simple applications towards multi-agent autonomous decision-making and task collaboration in complex environments. As Large Language Models (LLMs) advance, their applications become more diverse and complex, leading to increasingly situational and systemic risks. This has brought significant attention to value alignment for AI agents, which aims to ensure that an agent's goals, preferences, and behaviors align with human values and societal norms. This paper reviews value alignment in agent systems within specific application scenarios. It integrates the advancements in AI driven by large models with the demands of social governance. Our review covers value principles, agent system application scenarios, and agent value alignment evaluation. Specifically, value principles are organized hierarchically from a top-down perspective, encompassing macro, meso, and micro levels. Agent system application scenarios are categorized and reviewed from a general-to-specific viewpoint. Agent value alignment evaluation systematically examines datasets for value alignment assessment and relevant value alignment methods. Additionally, we delve into value coordination among multiple agents within agent systems. Finally, we propose several potential research directions in this field.
GenKI: Enhancing Open-Domain Question Answering with Knowledge Integration and Controllable Generation in Large Language Models
May 26, 2025Open-domain question answering (OpenQA) represents a cornerstone in natural language processing (NLP), primarily focused on extracting answers from unstructured textual data. With the rapid advancements in Large Language Models (LLMs), LLM-based OpenQA methods have reaped the benefits of emergent understanding and answering capabilities enabled by massive parameters compared to traditional methods. However, most of these methods encounter two critical challenges: how to integrate knowledge into LLMs effectively and how to adaptively generate results with specific answer formats for various task situations. To address these challenges, we propose a novel framework named GenKI, which aims to improve the OpenQA performance by exploring Knowledge Integration and controllable Generation on LLMs simultaneously. Specifically, we first train a dense passage retrieval model to retrieve associated knowledge from a given knowledge base. Subsequently, we introduce a novel knowledge integration model that incorporates the retrieval knowledge into instructions during fine-tuning to intensify the model. Furthermore, to enable controllable generation in LLMs, we leverage a certain fine-tuned LLM and an ensemble based on text consistency incorporating all coherence, fluency, and answer format assurance. Finally, extensive experiments conducted on the TriviaQA, MSMARCO, and CMRC2018 datasets, featuring diverse answer formats, have demonstrated the effectiveness of GenKI with comparison of state-of-the-art baselines. Moreover, ablation studies have disclosed a linear relationship between the frequency of retrieved knowledge and the model's ability to recall knowledge accurately against the ground truth. Our code of GenKI is available at https://github.com/USTC-StarTeam/GenKI
Think Hierarchically, Act Dynamically: Hierarchical Multi-modal Fusion and Reasoning for Vision-and-Language Navigation
Apr 23, 2025Vision-and-Language Navigation (VLN) aims to enable embodied agents to follow natural language instructions and reach target locations in real-world environments. While prior methods often rely on either global scene representations or object-level features, these approaches are insufficient for capturing the complex interactions across modalities required for accurate navigation. In this paper, we propose a Multi-level Fusion and Reasoning Architecture (MFRA) to enhance the agent's ability to reason over visual observations, language instructions and navigation history. Specifically, MFRA introduces a hierarchical fusion mechanism that aggregates multi-level features-ranging from low-level visual cues to high-level semantic concepts-across multiple modalities. We further design a reasoning module that leverages fused representations to infer navigation actions through instruction-guided attention and dynamic context integration. By selectively capturing and combining relevant visual, linguistic, and temporal signals, MFRA improves decision-making accuracy in complex navigation scenarios. Extensive experiments on benchmark VLN datasets including REVERIE, R2R, and SOON demonstrate that MFRA achieves superior performance compared to state-of-the-art methods, validating the effectiveness of multi-level modal fusion for embodied navigation.
A Comprehensive Survey on Self-Interpretable Neural Networks
Jan 26, 2025Neural networks have achieved remarkable success across various fields. However, the lack of interpretability limits their practical use, particularly in critical decision-making scenarios. Post-hoc interpretability, which provides explanations for pre-trained models, is often at risk of robustness and fidelity. This has inspired a rising interest in self-interpretable neural networks, which inherently reveal the prediction rationale through the model structures. Although there exist surveys on post-hoc interpretability, a comprehensive and systematic survey of self-interpretable neural networks is still missing. To address this gap, we first collect and review existing works on self-interpretable neural networks and provide a structured summary of their methodologies from five key perspectives: attribution-based, function-based, concept-based, prototype-based, and rule-based self-interpretation. We also present concrete, visualized examples of model explanations and discuss their applicability across diverse scenarios, including image, text, graph data, and deep reinforcement learning. Additionally, we summarize existing evaluation metrics for self-interpretability and identify open challenges in this field, offering insights for future research. To support ongoing developments, we present a publicly accessible resource to track advancements in this domain: https://github.com/yangji721/Awesome-Self-Interpretable-Neural-Network.