 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisRefiner: Learning from Visual Differences for Screenshot-to-Code Generation
Feb 05, 2026Screenshot-to-code generation aims to translate user interface screenshots into executable frontend code that faithfully reproduces the target layout and style. Existing multimodal large language models perform this mapping directly from screenshots but are trained without observing the visual outcomes of their generated code. In contrast, human developers iteratively render their implementation, compare it with the design, and learn how visual differences relate to code changes. Inspired by this process, we propose VisRefiner, a training framework that enables models to learn from visual differences between rendered predictions and reference designs. We construct difference-aligned supervision that associates visual discrepancies with corresponding code edits, allowing the model to understand how appearance variations arise from implementation changes. Building on this, we introduce a reinforcement learning stage for self-refinement, where the model improves its generated code by observing both the rendered output and the target design, identifying their visual differences, and updating the code accordingly. Experiments show that VisRefiner substantially improves single-step generation quality and layout fidelity, while also endowing models with strong self-refinement ability. These results demonstrate the effectiveness of learning from visual differences for advancing screenshot-to-code generation.
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning
Aug 18, 2025Linux kernel tuning is essential for optimizing operating system (OS) performance. However, existing methods often face challenges in terms of efficiency, scalability, and generalization. This paper introduces OS-R1, an agentic Linux kernel tuning framework powered by rule-based reinforcement learning (RL). By abstracting the kernel configuration space as an RL environment, OS-R1 facilitates efficient exploration by large language models (LLMs) and ensures accurate configuration modifications. Additionally, custom reward functions are designed to enhance reasoning standardization, configuration modification accuracy, and system performance awareness of the LLMs. Furthermore, we propose a two-phase training process that accelerates convergence and minimizes retraining across diverse tuning scenarios. Experimental results show that OS-R1 significantly outperforms existing baseline methods, achieving up to 5.6% performance improvement over heuristic tuning and maintaining high data efficiency. Notably, OS-R1 is adaptable across various real-world applications, demonstrating its potential for practical deployment in diverse environments. Our dataset and code are publicly available at https://github.com/LHY-24/OS-R1.
KGCompiler: Deep Learning Compilation Optimization for Knowledge Graph Complex Logical Query Answering
Mar 04, 2025
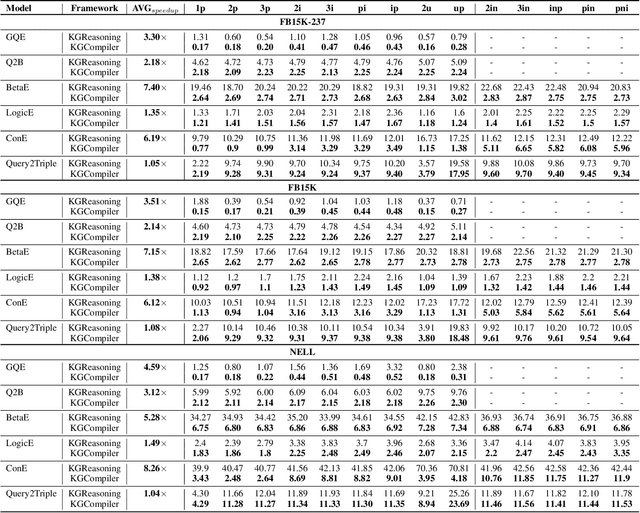


Complex Logical Query Answering (CLQA) involves intricate multi-hop logical reasoning over large-scale and potentially incomplete Knowledge Graphs (KGs). Although existing CLQA algorithms achieve high accuracy in answering such queries, their reasoning time and memory usage scale significantly with the number of First-Order Logic (FOL) operators involved, creating serious challenges for practical deployment. In addition, current research primarily focuses on algorithm-level optimizations for CLQA tasks, often overlooking compiler-level optimizations, which can offer greater generality and scalability. To address these limitations, we introduce a Knowledge Graph Compiler, namely KGCompiler, the first deep learning compiler specifically designed for CLQA tasks. By incorporating KG-specific optimizations proposed in this paper, KGCompiler enhances the reasoning performance of CLQA algorithms without requiring additional manual modifications to their implementations. At the same time, it significantly reduces memory usage. Extensive experiments demonstrate that KGCompiler accelerates CLQA algorithms by factors ranging from 1.04x to 8.26x, with an average speedup of 3.71x. We also provide an interface to enable hands-on experience with KGCompiler.
Towards Efficient Resume Understanding: A Multi-Granularity Multi-Modal Pre-Training Approach
Apr 13, 2024
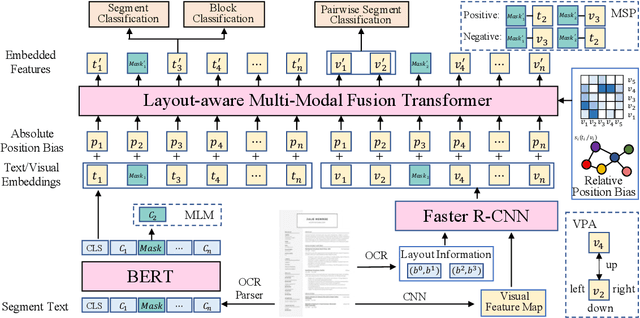


In the contemporary era of widespread online recruitment, resume understanding has been widely acknowledged as a fundamental and crucial task, which aims to extract structured information from resume documents automatically. Compared to the traditional rule-based approaches, the utilization of recently proposed pre-trained document understanding models can greatly enhance the effectiveness of resume understanding. The present approaches have, however, disregarded the hierarchical relations within the structured information presented in resumes, and have difficulty parsing resumes in an efficient manner. To this end, in this paper, we propose a novel model, namely ERU, to achieve efficient resume understanding. Specifically, we first introduce a layout-aware multi-modal fusion transformer for encoding the segments in the resume with integrated textual, visual, and layout information. Then, we design three self-supervised tasks to pre-train this module via a large number of unlabeled resumes. Next, we fine-tune the model with a multi-granularity sequence labeling task to extract structured information from resumes. Finally, extensive experiments on a real-world dataset clearly demonstrate the effectiveness of ERU.
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Apr 10, 2024



Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Seq-HGNN: Learning Sequential Node Representation on Heterogeneous Graph
May 18, 2023



Recent years have witnessed the rapid development of heterogeneous graph neural networks (HGNNs) in information retrieval (IR) applications. Many existing HGNNs design a variety of tailor-made graph convolutions to capture structural and semantic information in heterogeneous graphs. However, existing HGNNs usually represent each node as a single vector in the multi-layer graph convolution calculation, which makes the high-level graph convolution layer fail to distinguish information from different relations and different orders, resulting in the information loss in the message passing. %insufficient mining of information. To this end, we propose a novel heterogeneous graph neural network with sequential node representation, namely Seq-HGNN. To avoid the information loss caused by the single vector node representation, we first design a sequential node representation learning mechanism to represent each node as a sequence of meta-path representations during the node message passing. Then we propose a heterogeneous representation fusion module, empowering Seq-HGNN to identify important meta-paths and aggregate their representations into a compact one. We conduct extensive experiments on four widely used datasets from Heterogeneous Graph Benchmark (HGB) and Open Graph Benchmark (OGB). Experimental results show that our proposed method outperforms state-of-the-art baselines in both accuracy and efficiency. The source code is available at https://github.com/nobrowning/SEQ_HGNN.