 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Rollback Correction for Quality-Diverse Web Agent Imitation
Jun 10, 2026Training interactive web agents through imitation learning from expert trajectories has emerged as a highly effective approach. However, determining the optimal timing for expert intervention presents a critical challenge in this context. Delayed intervention often leads to the accumulation of early-stage errors, pushing the page state into an irrecoverable regime. Conversely, premature or excessive intervention causes the agent to become overly reliant on expert policies, trapping the model in local optima characterized by a single, rigid trajectory. We propose Speculative Rollback Correction (SRC), a branch-level imitation framework for resettable agent environments. Instead of requesting teacher labels at every visited state or correcting only after a completed trajectory, SRC uses fixed-horizon branch review: the student executes a short speculative segment before teacher review, and the teacher localizes the first harmful deviation only when local progress breaks. Rollback preserves useful prefixes, while successful rollouts are filtered by a hard verifier and retained in a lightweight quality-diversity archive. The resulting data supports next-action supervised fine-tuning on both localized corrections and verifier-passing trajectories. On WebArena-Infinity, SRC collects 977 verifier-passing trajectories and 9,183 next-action examples; fixed-horizon review improves the recovery-versus-query tradeoff over step-level review while retaining verifier-passing solution variants. Code is available at https://github.com/LongkunHao/SRC_gui_agent.
Toward Compiler World Models: Learning Latent Dynamics for Efficient Tensor Program Search
Jun 08, 2026Tensor program optimization is essential for modern machine learning systems, but its search space is enormous. Existing auto-schedulers reduce measurement cost with learned cost models, yet they usually evaluate each candidate as a static code snapshot, ignoring the schedule trajectory that produced it. This makes them insensitive to action dependencies and vulnerable to superficial code variations. We propose a \emph{world-model-inspired} evaluator that models schedule evaluation as action-conditioned latent dynamics over program states. Starting from the initial program, it rolls out scheduling actions in a continuous latent space with a lightweight transition model, avoiding expensive AST mutation and repeated code encoding. The final dynamic representation is combined with action and hardware features to rank candidates. Implemented in TVM AutoScheduler, our method improves representative-subgraph latency over Ansor by 1.37$\times$ on GPU and 1.54$\times$ on CPU under the same 64-trial budget. It also matches Ansor-10K within 2.2% geometric mean using 10$\times$ fewer measurements, and accelerates full-model inference over PyTorch/PyTorch-opt(cuDNN) by 4.61$\times$/3.67$\times$ geometric mean.
A Case for Agentic Tuning: From Documentation to Action in PostgreSQL
May 19, 2026Documentation has long guided computer system tuning by distilling expert knowledge into per-parameter recommendations. Yet such guides capture only what experts conclude, discarding how they reason. This fundamental gap manifests in three concrete deficiencies: documentation grows stale as software evolves, fails under heterogeneous workloads, and ignores inter-parameter dependencies. We propose shifting from static documentation to dynamic action for system tuning. We introduce PerfEvolve, which translates expert tuning methodologies into executable skills that equip LLM-based agents to perform version-consistency verification, workload-specific profiling, and multi-parameter joint optimization. Evaluated on PostgreSQL under TPC-C and TPC-H benchmarks, PerfEvolve outperforms state-of-the-art documentation-driven tuning baselines by up to 35.2%. The tool is available at https://github.com/ISCAS-OSLab/PerfEvolve.
Stable-LoRA: Stabilizing Feature Learning of Low-Rank Adaptation
Mar 05, 2026Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient method for fine-tuning Large Langauge Models. It updates the weight matrix as $W=W_0+sBA$, where $W_0$ is the original frozen weight, $s$ is a scaling factor and $A$,$B$ are trainable low-rank matrices. Despite its robust empirical effectiveness, the theoretical foundations of LoRA remain insufficiently understood, particularly with respect to feature learning stability. In this paper, we first establish that, LoRA can, in principle, naturally achieve and sustain stable feature learning (i.e., be self-stabilized) under appropriate hyper-parameters and initializations of $A$ and $B$. However, we also uncover a fundamental limitation that the necessary non-zero initialization of $A$ compromises self-stability, leading to suboptimal performances. To address this challenge, we propose Stable-LoRA, a weight-shrinkage optimization strategy that dynamically enhances stability of LoRA feature learning. By progressively shrinking $A$ during the earliest training steps, Stable-LoRA is both theoretically and empirically validated to effectively eliminate instability of LoRA feature learning while preserving the benefits of the non-zero start. Experiments show that Stable-LoRA consistently outperforms other baselines across diverse models and tasks, with no additional memory usage and only negligible computation overheads. The code is available at https://github.com/Yize-Wu/Stable-LoRA.
ECCO: Evidence-Driven Causal Reasoning for Compiler Optimization
Jan 23, 2026Compiler auto-tuning faces a dichotomy between traditional black-box search methods, which lack semantic guidance, and recent Large Language Model (LLM) approaches, which often suffer from superficial pattern matching and causal opacity. In this paper, we introduce ECCO, a framework that bridges interpretable reasoning with combinatorial search. We first propose a reverse engineering methodology to construct a Chain-of-Thought dataset, explicitly mapping static code features to verifiable performance evidence. This enables the model to learn the causal logic governing optimization decisions rather than merely imitating sequences. Leveraging this interpretable prior, we design a collaborative inference mechanism where the LLM functions as a strategist, defining optimization intents that dynamically guide the mutation operations of a genetic algorithm. Experimental results on seven datasets demonstrate that ECCO significantly outperforms the LLVM opt -O3 baseline, achieving an average 24.44% reduction in cycles.
Exploring the Feasibility of End-to-End Large Language Model as a Compiler
Nov 06, 2025In recent years, end-to-end Large Language Model (LLM) technology has shown substantial advantages across various domains. As critical system software and infrastructure, compilers are responsible for transforming source code into target code. While LLMs have been leveraged to assist in compiler development and maintenance, their potential as an end-to-end compiler remains largely unexplored. This paper explores the feasibility of LLM as a Compiler (LaaC) and its future directions. We designed the CompilerEval dataset and framework specifically to evaluate the capabilities of mainstream LLMs in source code comprehension and assembly code generation. In the evaluation, we analyzed various errors, explored multiple methods to improve LLM-generated code, and evaluated cross-platform compilation capabilities. Experimental results demonstrate that LLMs exhibit basic capabilities as compilers but currently achieve low compilation success rates. By optimizing prompts, scaling up the model, and incorporating reasoning methods, the quality of assembly code generated by LLMs can be significantly enhanced. Based on these findings, we maintain an optimistic outlook for LaaC and propose practical architectural designs and future research directions. We believe that with targeted training, knowledge-rich prompts, and specialized infrastructure, LaaC has the potential to generate high-quality assembly code and drive a paradigm shift in the field of compilation.
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning
Aug 18, 2025Linux kernel tuning is essential for optimizing operating system (OS) performance. However, existing methods often face challenges in terms of efficiency, scalability, and generalization. This paper introduces OS-R1, an agentic Linux kernel tuning framework powered by rule-based reinforcement learning (RL). By abstracting the kernel configuration space as an RL environment, OS-R1 facilitates efficient exploration by large language models (LLMs) and ensures accurate configuration modifications. Additionally, custom reward functions are designed to enhance reasoning standardization, configuration modification accuracy, and system performance awareness of the LLMs. Furthermore, we propose a two-phase training process that accelerates convergence and minimizes retraining across diverse tuning scenarios. Experimental results show that OS-R1 significantly outperforms existing baseline methods, achieving up to 5.6% performance improvement over heuristic tuning and maintaining high data efficiency. Notably, OS-R1 is adaptable across various real-world applications, demonstrating its potential for practical deployment in diverse environments. Our dataset and code are publicly available at https://github.com/LHY-24/OS-R1.
QiMeng-Attention: SOTA Attention Operator is generated by SOTA Attention Algorithm
Jun 14, 2025The attention operator remains a critical performance bottleneck in large language models (LLMs), particularly for long-context scenarios. While FlashAttention is the most widely used and effective GPU-aware acceleration algorithm, it must require time-consuming and hardware-specific manual implementation, limiting adaptability across GPU architectures. Existing LLMs have shown a lot of promise in code generation tasks, but struggle to generate high-performance attention code. The key challenge is it cannot comprehend the complex data flow and computation process of the attention operator and utilize low-level primitive to exploit GPU performance. To address the above challenge, we propose an LLM-friendly Thinking Language (LLM-TL) to help LLMs decouple the generation of high-level optimization logic and low-level implementation on GPU, and enhance LLMs' understanding of attention operator. Along with a 2-stage reasoning workflow, TL-Code generation and translation, the LLMs can automatically generate FlashAttention implementation on diverse GPUs, establishing a self-optimizing paradigm for generating high-performance attention operators in attention-centric algorithms. Verified on A100, RTX8000, and T4 GPUs, the performance of our methods significantly outshines that of vanilla LLMs, achieving a speed-up of up to 35.16x. Besides, our method not only surpasses human-optimized libraries (cuDNN and official library) in most scenarios but also extends support to unsupported hardware and data types, reducing development time from months to minutes compared with human experts.
QiMeng-TensorOp: Automatically Generating High-Performance Tensor Operators with Hardware Primitives
May 08, 2025Computation-intensive tensor operators constitute over 90\% of the computations in Large Language Models (LLMs) and Deep Neural Networks.Automatically and efficiently generating high-performance tensor operators with hardware primitives is crucial for diverse and ever-evolving hardware architectures like RISC-V, ARM, and GPUs, as manually optimized implementation takes at least months and lacks portability.LLMs excel at generating high-level language codes, but they struggle to fully comprehend hardware characteristics and produce high-performance tensor operators. We introduce a tensor-operator auto-generation framework with a one-line user prompt (QiMeng-TensorOp), which enables LLMs to automatically exploit hardware characteristics to generate tensor operators with hardware primitives, and tune parameters for optimal performance across diverse hardware. Experimental results on various hardware platforms, SOTA LLMs, and typical tensor operators demonstrate that QiMeng-TensorOp effectively unleashes the computing capability of various hardware platforms, and automatically generates tensor operators of superior performance. Compared with vanilla LLMs, QiMeng-TensorOp achieves up to $1291 \times$ performance improvement. Even compared with human experts, QiMeng-TensorOp could reach $251 \%$ of OpenBLAS on RISC-V CPUs, and $124 \%$ of cuBLAS on NVIDIA GPUs. Additionally, QiMeng-TensorOp also significantly reduces development costs by $200 \times$ compared with human experts.
KGCompiler: Deep Learning Compilation Optimization for Knowledge Graph Complex Logical Query Answering
Mar 04, 2025
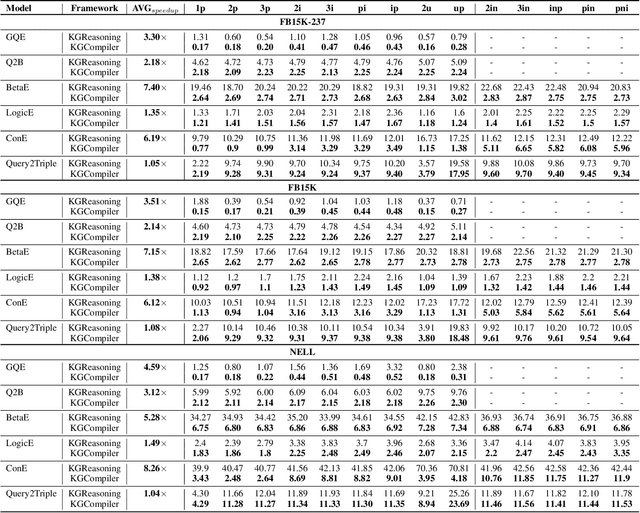


Complex Logical Query Answering (CLQA) involves intricate multi-hop logical reasoning over large-scale and potentially incomplete Knowledge Graphs (KGs). Although existing CLQA algorithms achieve high accuracy in answering such queries, their reasoning time and memory usage scale significantly with the number of First-Order Logic (FOL) operators involved, creating serious challenges for practical deployment. In addition, current research primarily focuses on algorithm-level optimizations for CLQA tasks, often overlooking compiler-level optimizations, which can offer greater generality and scalability. To address these limitations, we introduce a Knowledge Graph Compiler, namely KGCompiler, the first deep learning compiler specifically designed for CLQA tasks. By incorporating KG-specific optimizations proposed in this paper, KGCompiler enhances the reasoning performance of CLQA algorithms without requiring additional manual modifications to their implementations. At the same time, it significantly reduces memory usage. Extensive experiments demonstrate that KGCompiler accelerates CLQA algorithms by factors ranging from 1.04x to 8.26x, with an average speedup of 3.71x. We also provide an interface to enable hands-on experience with KGCompiler.