 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMFN: Cross-Modal Fusion Network for Irregular Scene Text Recognition
Jan 18, 2024Scene text recognition, as a cross-modal task involving vision and text, is an important research topic in computer vision. Most existing methods use language models to extract semantic information for optimizing visual recognition. However, the guidance of visual cues is ignored in the process of semantic mining, which limits the performance of the algorithm in recognizing irregular scene text. To tackle this issue, we propose a novel cross-modal fusion network (CMFN) for irregular scene text recognition, which incorporates visual cues into the semantic mining process. Specifically, CMFN consists of a position self-enhanced encoder, a visual recognition branch and an iterative semantic recognition branch. The position self-enhanced encoder provides character sequence position encoding for both the visual recognition branch and the iterative semantic recognition branch. The visual recognition branch carries out visual recognition based on the visual features extracted by CNN and the position encoding information provided by the position self-enhanced encoder. The iterative semantic recognition branch, which consists of a language recognition module and a cross-modal fusion gate, simulates the way that human recognizes scene text and integrates cross-modal visual cues for text recognition. The experiments demonstrate that the proposed CMFN algorithm achieves comparable performance to state-of-the-art algorithms, indicating its effectiveness.
BPDO:Boundary Points Dynamic Optimization for Arbitrary Shape Scene Text Detection
Jan 18, 2024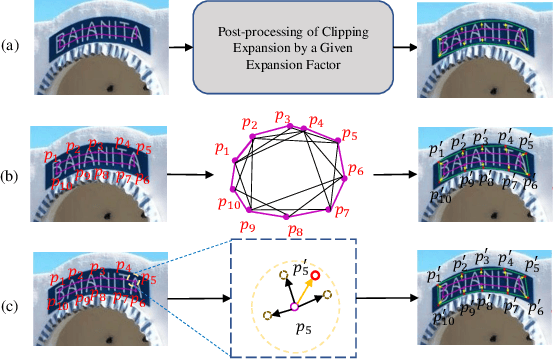
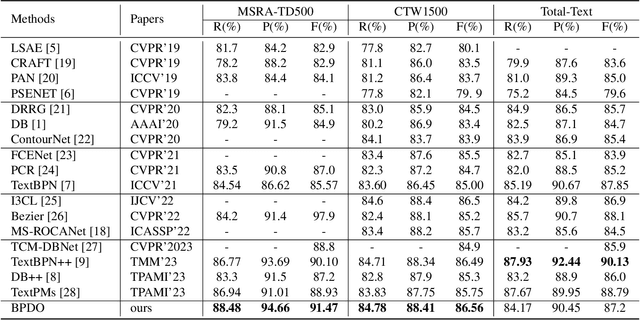
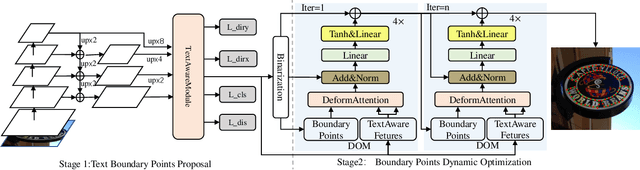

Arbitrary shape scene text detection is of great importance in scene understanding tasks. Due to the complexity and diversity of text in natural scenes, existing scene text algorithms have limited accuracy for detecting arbitrary shape text. In this paper, we propose a novel arbitrary shape scene text detector through boundary points dynamic optimization(BPDO). The proposed model is designed with a text aware module (TAM) and a boundary point dynamic optimization module (DOM). Specifically, the model designs a text aware module based on segmentation to obtain boundary points describing the central region of the text by extracting a priori information about the text region. Then, based on the idea of deformable attention, it proposes a dynamic optimization model for boundary points, which gradually optimizes the exact position of the boundary points based on the information of the adjacent region of each boundary point. Experiments on CTW-1500, Total-Text, and MSRA-TD500 datasets show that the model proposed in this paper achieves a performance that is better than or comparable to the state-of-the-art algorithm, proving the effectiveness of the model.
Text Region Multiple Information Perception Network for Scene Text Detection
Jan 18, 2024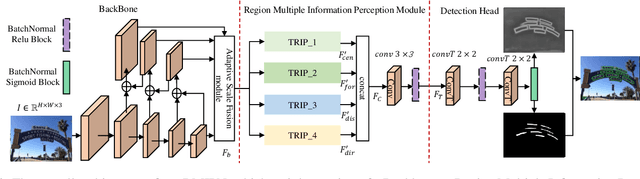

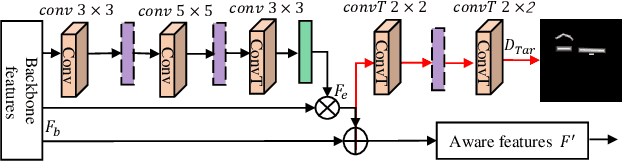
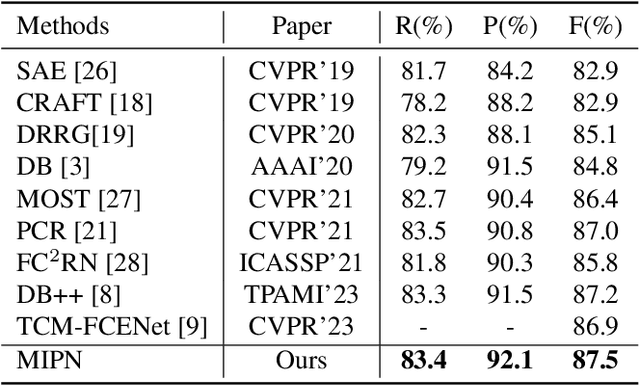
Segmentation-based scene text detection algorithms can handle arbitrary shape scene texts and have strong robustness and adaptability, so it has attracted wide attention. Existing segmentation-based scene text detection algorithms usually only segment the pixels in the center region of the text, while ignoring other information of the text region, such as edge information, distance information, etc., thus limiting the detection accuracy of the algorithm for scene text. This paper proposes a plug-and-play module called the Region Multiple Information Perception Module (RMIPM) to enhance the detection performance of segmentation-based algorithms. Specifically, we design an improved module that can perceive various types of information about scene text regions, such as text foreground classification maps, distance maps, direction maps, etc. Experiments on MSRA-TD500 and TotalText datasets show that our method achieves comparable performance with current state-of-the-art algorithms.