 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Constrained Sampling for Language Models Should Be Easy: An MCMC Perspective
Jun 06, 2025Constrained decoding enables Language Models (LMs) to produce samples that provably satisfy hard constraints. However, existing constrained-decoding approaches often distort the underlying model distribution, a limitation that is especially problematic in applications like program fuzzing, where one wants to generate diverse and valid program inputs for testing purposes. We propose a new constrained sampling framework based on Markov Chain Monte Carlo (MCMC) that simultaneously satisfies three core desiderata: constraint satisfying (every sample satisfies the constraint), monotonically converging (the sampling process converges to the true conditional distribution), and efficient (high-quality samples emerge in few steps). Our method constructs a proposal distribution over valid outputs and applies a Metropolis-Hastings acceptance criterion based on the LM's likelihood, ensuring principled and efficient exploration of the constrained space. Empirically, our sampler outperforms existing methods on both synthetic benchmarks and real-world program fuzzing tasks.
CMFN: Cross-Modal Fusion Network for Irregular Scene Text Recognition
Jan 18, 2024Scene text recognition, as a cross-modal task involving vision and text, is an important research topic in computer vision. Most existing methods use language models to extract semantic information for optimizing visual recognition. However, the guidance of visual cues is ignored in the process of semantic mining, which limits the performance of the algorithm in recognizing irregular scene text. To tackle this issue, we propose a novel cross-modal fusion network (CMFN) for irregular scene text recognition, which incorporates visual cues into the semantic mining process. Specifically, CMFN consists of a position self-enhanced encoder, a visual recognition branch and an iterative semantic recognition branch. The position self-enhanced encoder provides character sequence position encoding for both the visual recognition branch and the iterative semantic recognition branch. The visual recognition branch carries out visual recognition based on the visual features extracted by CNN and the position encoding information provided by the position self-enhanced encoder. The iterative semantic recognition branch, which consists of a language recognition module and a cross-modal fusion gate, simulates the way that human recognizes scene text and integrates cross-modal visual cues for text recognition. The experiments demonstrate that the proposed CMFN algorithm achieves comparable performance to state-of-the-art algorithms, indicating its effectiveness.
SDF-3DGAN: A 3D Object Generative Method Based on Implicit Signed Distance Function
Mar 13, 2023



In this paper, we develop a new method, termed SDF-3DGAN, for 3D object generation and 3D-Aware image synthesis tasks, which introduce implicit Signed Distance Function (SDF) as the 3D object representation method in the generative field. We apply SDF for higher quality representation of 3D object in space and design a new SDF neural renderer, which has higher efficiency and higher accuracy. To train only on 2D images, we first generate the objects, which are represented by SDF, from Gaussian distribution. Then we render them to 2D images and use them to apply GAN training method together with 2D images in the dataset. In the new rendering method, we relieve all the potential of SDF mathematical property to alleviate computation pressure in the previous SDF neural renderer. In specific, our new SDF neural renderer can solve the problem of sampling ambiguity when the number of sampling point is not enough, \ie use the less points to finish higher quality sampling task in the rendering pipeline. And in this rendering pipeline, we can locate the surface easily. Therefore, we apply normal loss on it to control the smoothness of generated object surface, which can make our method enjoy the much higher generation quality. Quantitative and qualitative experiments conducted on public benchmarks demonstrate favorable performance against the state-of-the-art methods in 3D object generation task and 3D-Aware image synthesis task. Our codes will be released at https://github.com/lutao2021/SDF-3DGAN.
PIDray: A Large-scale X-ray Benchmark for Real-World Prohibited Item Detection
Nov 19, 2022Automatic security inspection relying on computer vision technology is a challenging task in real-world scenarios due to many factors, such as intra-class variance, class imbalance, and occlusion. Most previous methods rarely touch the cases where the prohibited items are deliberately hidden in messy objects because of the scarcity of large-scale datasets, hindering their applications. To address this issue and facilitate related research, we present a large-scale dataset, named PIDray, which covers various cases in real-world scenarios for prohibited item detection, especially for deliberately hidden items. In specific, PIDray collects 124,486 X-ray images for $12$ categories of prohibited items, and each image is manually annotated with careful inspection, which makes it, to our best knowledge, to largest prohibited items detection dataset to date. Meanwhile, we propose a general divide-and-conquer pipeline to develop baseline algorithms on PIDray. Specifically, we adopt the tree-like structure to suppress the influence of the long-tailed issue in the PIDray dataset, where the first course-grained node is tasked with the binary classification to alleviate the influence of head category, while the subsequent fine-grained node is dedicated to the specific tasks of the tail categories. Based on this simple yet effective scheme, we offer strong task-specific baselines across object detection, instance segmentation, and multi-label classification tasks and verify the generalization ability on common datasets (e.g., COCO and PASCAL VOC). Extensive experiments on PIDray demonstrate that the proposed method performs favorably against current state-of-the-art methods, especially for deliberately hidden items. Our benchmark and codes will be released at https://github.com/lutao2021/PIDray.
Learning Semantic Neural Tree for Human Parsing
Dec 20, 2019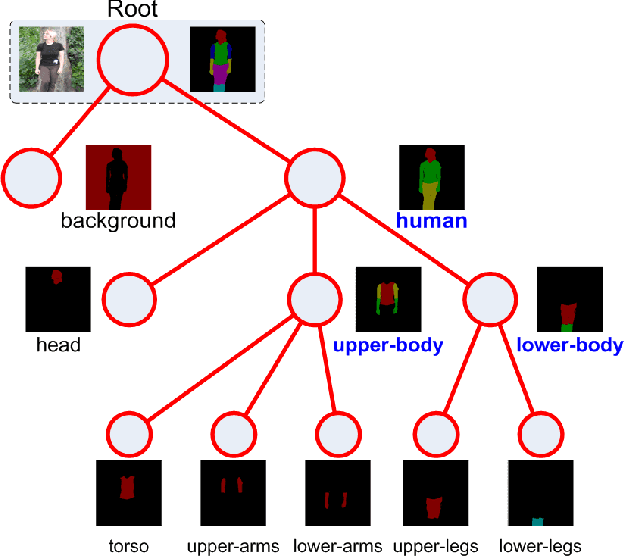

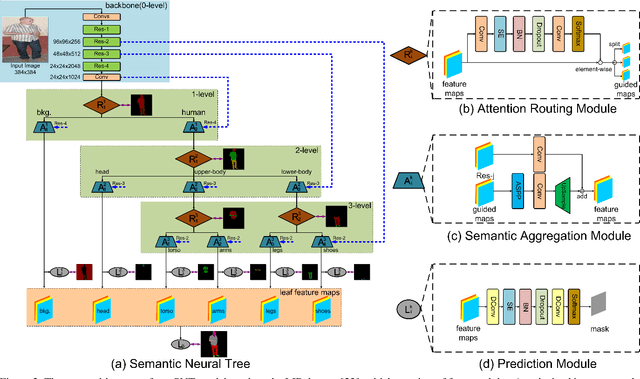

The majority of existing human parsing methods formulate the task as semantic segmentation, which regard each semantic category equally and fail to exploit the intrinsic physiological structure of human body, resulting in inaccurate results. In this paper, we design a novel semantic neural tree for human parsing, which uses a tree architecture to encode physiological structure of human body, and designs a coarse to fine process in a cascade manner to generate accurate results. Specifically, the semantic neural tree is designed to segment human regions into multiple semantic subregions (e.g., face, arms, and legs) in a hierarchical way using a new designed attention routing module. Meanwhile, we introduce the semantic aggregation module to combine multiple hierarchical features to exploit more context information for better performance. Our semantic neural tree can be trained in an end-to-end fashion by standard stochastic gradient descent (SGD) with back-propagation. Several experiments conducted on four challenging datasets for both single and multiple human parsing, i.e., LIP, PASCAL-Person-Part, CIHP and MHP-v2, demonstrate the effectiveness of the proposed method. Code can be found at https://isrc.iscas.ac.cn/gitlab/research/sematree.
Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization
Sep 25, 2019

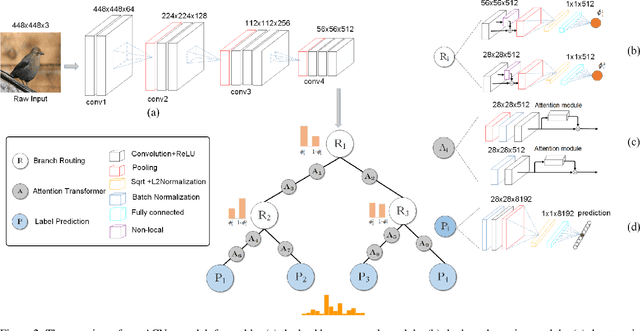

Fine-grained visual categorization (FGVC) is an important but challenging task due to high intra-class variances and low inter-class variances caused by deformation, occlusion, illumination, etc. An attention convolutional binary neural tree architecture is presented to address those problems for weakly supervised FGVC. Specifically, we incorporate convolutional operations along edges of the tree structure, and use the routing functions in each node to determine the root-to-leaf computational paths within the tree. The final decision is computed as the summation of the predictions from leaf nodes. The deep convolutional operations learn to capture the representations of objects, and the tree structure characterizes the coarse-to-fine hierarchical feature learning process. In addition, we use the attention transformer module to enforce the network to capture discriminative features. The negative log-likelihood loss is used to train the entire network in an end-to-end fashion by SGD with back-propagation. Several experiments on the CUB-200-2011, Stanford Cars and Aircraft datasets demonstrate that the proposed method performs favorably against the state-of-the-arts.
What Does a TextCNN Learn?
Jan 19, 2018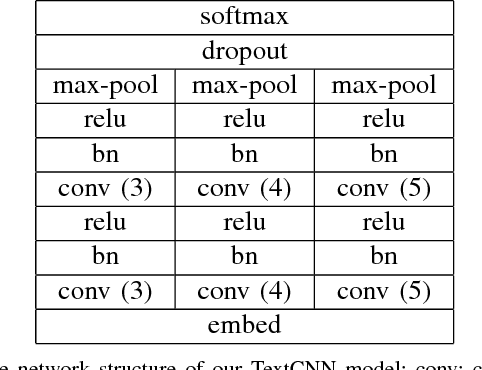
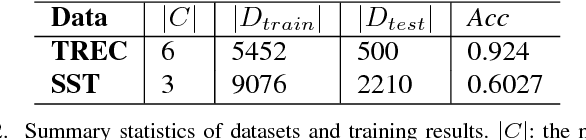
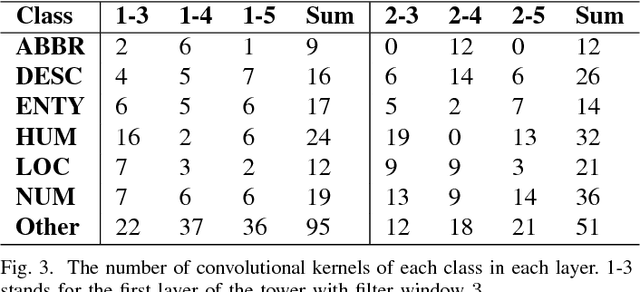

TextCNN, the convolutional neural network for text, is a useful deep learning algorithm for sentence classification tasks such as sentiment analysis and question classification. However, neural networks have long been known as black boxes because interpreting them is a challenging task. Researchers have developed several tools to understand a CNN for image classification by deep visualization, but research about deep TextCNNs is still insufficient. In this paper, we are trying to understand what a TextCNN learns on two classical NLP datasets. Our work focuses on functions of different convolutional kernels and correlations between convolutional kernels.