 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistNav: Closing the Action Consistency Gap in Zero-Shot Object Navigation with Semantic Executive Control
May 11, 2026Zero-shot object navigation has advanced rapidly with open-vocabulary detectors, image--text models, and language-guided exploration. However, even after current methods detect a plausible target hypothesis, the agent may still oscillate between exploration and pursuit, or abandon the object near success. We identify this failure mode as an action consistency gap: semantic evidence is repeatedly reinterpreted at each step without persistent commitment across the episode. We introduce ConsistNav, a training-free zero-shot ObjectNav framework built around a semantic executive composed of three coordinated modules: Finite-State Executive Controller stages target pursuit through guarded semantic phases; Persistent Candidate Memory accumulates cross-frame target evidence into stable object hypotheses; and Stability-Aware Action Control suppresses rotational stagnation, ineffective pursuit, and unverified stopping. This design changes neither the detector nor the low-level planner; instead, it controls when semantic evidence should influence navigation and when it should be suppressed or revisited. We conduct extensive experiments on HM3D and MP3D, where ConsistNav achieves state-of-the-art results among compared zero-shot ObjectNav methods and improves SR by 11.4% and SPL by 7.9% over the controlled baseline on MP3D. Ablation studies and real-world deployment experiments further demonstrate the effectiveness and robustness of the proposed executive mechanism.
SAP: Segment Any 4K Panorama
Mar 13, 2026Promptable instance segmentation is widely adopted in embodied and AR systems, yet the performance of foundation models trained on perspective imagery often degrades on 360° panoramas. In this paper, we introduce Segment Any 4K Panorama (SAP), a foundation model for 4K high-resolution panoramic instance-level segmentation. We reformulate panoramic segmentation as fixed-trajectory perspective video segmentation, decomposing a panorama into overlapping perspective patches sampled along a continuous spherical traversal. This memory-aligned reformulation preserves native 4K resolution while restoring the smooth viewpoint transitions required for stable cross-view propagation. To enable large-scale supervision, we synthesize 183,440 4K-resolution panoramic images with instance segmentation labels using the InfiniGen engine. Trained under this trajectory-aligned paradigm, SAP generalizes effectively to real-world 360° images, achieving +17.2 zero-shot mIoU gain over vanilla SAM2 of different sizes on real-world 4K panorama benchmark.
EgoIntent: An Egocentric Step-level Benchmark for Understanding What, Why, and Next
Mar 12, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable video reasoning capabilities across diverse tasks. However, their ability to understand human intent at a fine-grained level in egocentric videos remains largely unexplored. Existing benchmarks focus primarily on episode-level intent reasoning, overlooking the finer granularity of step-level intent understanding. Yet applications such as intelligent assistants, robotic imitation learning, and augmented reality guidance require understanding not only what a person is doing at each step, but also why and what comes next, in order to provide timely and context-aware support. To this end, we introduce EgoIntent, a step-level intent understanding benchmark for egocentric videos. It comprises 3,014 steps spanning 15 diverse indoor and outdoor daily-life scenarios, and evaluates models on three complementary dimensions: local intent (What), global intent (Why), and next-step plan (Next). Crucially, each clip is truncated immediately before the key outcome of the queried step (e.g., contact or grasp) occurs and contains no frames from subsequent steps, preventing future-frame leakage and enabling a clean evaluation of anticipatory step understanding and next-step planning. We evaluate 15 MLLMs, including both state-of-the-art closed-source and open-source models. Even the best-performing model achieves an average score of only 33.31 across the three intent dimensions, underscoring that step-level intent understanding in egocentric videos remains a highly challenging problem that calls for further investigation.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
T-Rex-Omni: Integrating Negative Visual Prompt in Generic Object Detection
Nov 12, 2025Object detection methods have evolved from closed-set to open-set paradigms over the years. Current open-set object detectors, however, remain constrained by their exclusive reliance on positive indicators based on given prompts like text descriptions or visual exemplars. This positive-only paradigm experiences consistent vulnerability to visually similar but semantically different distractors. We propose T-Rex-Omni, a novel framework that addresses this limitation by incorporating negative visual prompts to negate hard negative distractors. Specifically, we first introduce a unified visual prompt encoder that jointly processes positive and negative visual prompts. Next, a training-free Negating Negative Computing (NNC) module is proposed to dynamically suppress negative responses during the probability computing stage. To further boost performance through fine-tuning, our Negating Negative Hinge (NNH) loss enforces discriminative margins between positive and negative embeddings. T-Rex-Omni supports flexible deployment in both positive-only and joint positive-negative inference modes, accommodating either user-specified or automatically generated negative examples. Extensive experiments demonstrate remarkable zero-shot detection performance, significantly narrowing the performance gap between visual-prompted and text-prompted methods while showing particular strength in long-tailed scenarios (51.2 AP_r on LVIS-minival). This work establishes negative prompts as a crucial new dimension for advancing open-set visual recognition systems.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.
Are We Using the Right Benchmark: An Evaluation Framework for Visual Token Compression Methods
Oct 08, 2025Recent endeavors to accelerate inference in Multimodal Large Language Models (MLLMs) have primarily focused on visual token compression. The effectiveness of these methods is typically assessed by measuring the accuracy drop on established benchmarks, comparing model performance before and after compression. However, these benchmarks are originally designed to assess the perception and reasoning capabilities of MLLMs, rather than to evaluate compression techniques. As a result, directly applying them to visual token compression introduces a task mismatch. Strikingly, our investigation reveals that simple image downsampling consistently outperforms many advanced compression methods across multiple widely used benchmarks. Through extensive experiments, we make the following observations: (i) Current benchmarks are noisy for the visual token compression task. (ii) Down-sampling is able to serve as a data filter to evaluate the difficulty of samples in the visual token compression task. Motivated by these findings, we introduce VTC-Bench, an evaluation framework that incorporates a data filtering mechanism to denoise existing benchmarks, thereby enabling fairer and more accurate assessment of visual token compression methods. All data and code are available at https://github.com/Chenfei-Liao/VTC-Bench.
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Sep 16, 2025Omnidirectional vision, using 360-degree vision to understand the environment, has become increasingly critical across domains like robotics, industrial inspection, and environmental monitoring. Compared to traditional pinhole vision, omnidirectional vision provides holistic environmental awareness, significantly enhancing the completeness of scene perception and the reliability of decision-making. However, foundational research in this area has historically lagged behind traditional pinhole vision. This talk presents an emerging trend in the embodied AI era: the rapid development of omnidirectional vision, driven by growing industrial demand and academic interest. We highlight recent breakthroughs in omnidirectional generation, omnidirectional perception, omnidirectional understanding, and related datasets. Drawing on insights from both academia and industry, we propose an ideal panoramic system architecture in the embodied AI era, PANORAMA, which consists of four key subsystems. Moreover, we offer in-depth opinions related to emerging trends and cross-community impacts at the intersection of panoramic vision and embodied AI, along with the future roadmap and open challenges. This overview synthesizes state-of-the-art advancements and outlines challenges and opportunities for future research in building robust, general-purpose omnidirectional AI systems in the embodied AI era.
MLLMs are Deeply Affected by Modality Bias
May 24, 2025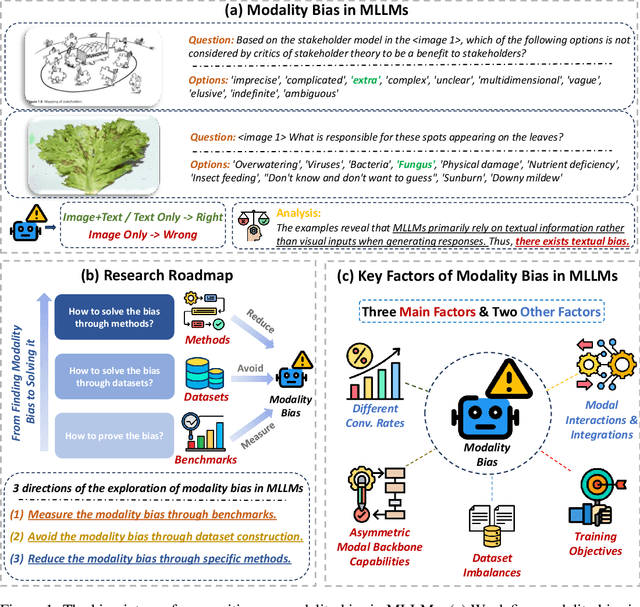
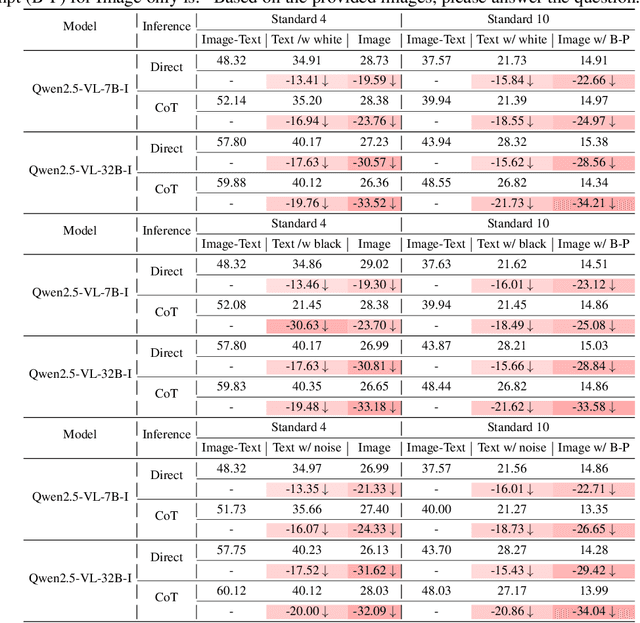
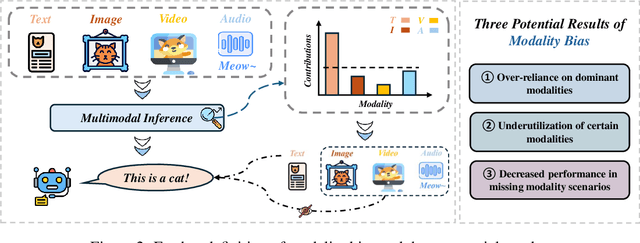
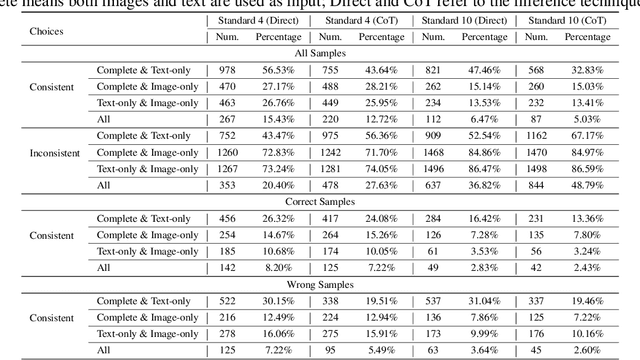
Recent advances in Multimodal Large Language Models (MLLMs) have shown promising results in integrating diverse modalities such as texts and images. MLLMs are heavily influenced by modality bias, often relying on language while under-utilizing other modalities like visual inputs. This position paper argues that MLLMs are deeply affected by modality bias. Firstly, we diagnose the current state of modality bias, highlighting its manifestations across various tasks. Secondly, we propose a systematic research road-map related to modality bias in MLLMs. Thirdly, we identify key factors of modality bias in MLLMs and offer actionable suggestions for future research to mitigate it. To substantiate these findings, we conduct experiments that demonstrate the influence of each factor: 1. Data Characteristics: Language data is compact and abstract, while visual data is redundant and complex, creating an inherent imbalance in learning dynamics. 2. Imbalanced Backbone Capabilities: The dominance of pretrained language models in MLLMs leads to overreliance on language and neglect of visual information. 3. Training Objectives: Current objectives often fail to promote balanced cross-modal alignment, resulting in shortcut learning biased toward language. These findings highlight the need for balanced training strategies and model architectures to better integrate multiple modalities in MLLMs. We call for interdisciplinary efforts to tackle these challenges and drive innovation in MLLM research. Our work provides a fresh perspective on modality bias in MLLMs and offers insights for developing more robust and generalizable multimodal systems-advancing progress toward Artificial General Intelligence.