 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Reflection: Transforming MLLMs from Passive Observers to Active Interrogators
Mar 31, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success, yet they remain prone to perception-related hallucinations in fine-grained tasks. This vulnerability arises from a fundamental limitation: their reasoning is largely restricted to the language domain, treating visual input as a static, reasoning-agnostic preamble rather than a dynamic participant. Consequently, current models act as passive observers, unable to re-examine visual details to ground their evolving reasoning states. To overcome this, we propose V-Reflection, a framework that transforms the MLLM into an active interrogator through a "think-then-look" visual reflection mechanism. During reasoning, latent states function as dynamic probes that actively interrogate the visual feature space, grounding each reasoning step for task-critical evidence. Our approach employs a two-stage distillation strategy. First, the Box-Guided Compression (BCM) module establishes stable pixel-to-latent targets through explicit spatial grounding. Next, a Dynamic Autoregressive Compression (DAC) module maps the model's hidden states into dynamic probes that interrogate the global visual feature map. By distilling the spatial expertise of the BCM teacher into the DAC student, V-Reflection internalizes the ability to localize task-critical evidence. During inference, both modules remain entirely inactive, maintaining a purely end-to-end autoregressive decoding in the latent space with optimal efficiency. Extensive experiments demonstrate the effectiveness of our V-Reflection across six perception-intensive benchmarks, significantly narrowing the fine-grained perception gap. Visualizations confirm that latent reasoning autonomously localizes task-critical visual evidence.
T-Rex-Omni: Integrating Negative Visual Prompt in Generic Object Detection
Nov 12, 2025Object detection methods have evolved from closed-set to open-set paradigms over the years. Current open-set object detectors, however, remain constrained by their exclusive reliance on positive indicators based on given prompts like text descriptions or visual exemplars. This positive-only paradigm experiences consistent vulnerability to visually similar but semantically different distractors. We propose T-Rex-Omni, a novel framework that addresses this limitation by incorporating negative visual prompts to negate hard negative distractors. Specifically, we first introduce a unified visual prompt encoder that jointly processes positive and negative visual prompts. Next, a training-free Negating Negative Computing (NNC) module is proposed to dynamically suppress negative responses during the probability computing stage. To further boost performance through fine-tuning, our Negating Negative Hinge (NNH) loss enforces discriminative margins between positive and negative embeddings. T-Rex-Omni supports flexible deployment in both positive-only and joint positive-negative inference modes, accommodating either user-specified or automatically generated negative examples. Extensive experiments demonstrate remarkable zero-shot detection performance, significantly narrowing the performance gap between visual-prompted and text-prompted methods while showing particular strength in long-tailed scenarios (51.2 AP_r on LVIS-minival). This work establishes negative prompts as a crucial new dimension for advancing open-set visual recognition systems.
MAGIC++: Efficient and Resilient Modality-Agnostic Semantic Segmentation via Hierarchical Modality Selection
Dec 22, 2024In this paper, we address the challenging modality-agnostic semantic segmentation (MaSS), aiming at centering the value of every modality at every feature granularity. Training with all available visual modalities and effectively fusing an arbitrary combination of them is essential for robust multi-modal fusion in semantic segmentation, especially in real-world scenarios, yet remains less explored to date. Existing approaches often place RGB at the center, treating other modalities as secondary, resulting in an asymmetric architecture. However, RGB alone can be limiting in scenarios like nighttime, where modalities such as event data excel. Therefore, a resilient fusion model must dynamically adapt to each modality's strengths while compensating for weaker inputs.To this end, we introduce the MAGIC++ framework, which comprises two key plug-and-play modules for effective multi-modal fusion and hierarchical modality selection that can be equipped with various backbone models. Firstly, we introduce a multi-modal interaction module to efficiently process features from the input multi-modal batches and extract complementary scene information with channel-wise and spatial-wise guidance. On top, a unified multi-scale arbitrary-modal selection module is proposed to utilize the aggregated features as the benchmark to rank the multi-modal features based on the similarity scores at hierarchical feature spaces. This way, our method can eliminate the dependence on RGB modality at every feature granularity and better overcome sensor failures and environmental noises while ensuring the segmentation performance. Under the common multi-modal setting, our method achieves state-of-the-art performance on both real-world and synthetic benchmarks. Moreover, our method is superior in the novel modality-agnostic setting, where it outperforms prior arts by a large margin.
Path-adaptive Spatio-Temporal State Space Model for Event-based Recognition with Arbitrary Duration
Sep 25, 2024Event cameras are bio-inspired sensors that capture the intensity changes asynchronously and output event streams with distinct advantages, such as high temporal resolution. To exploit event cameras for object/action recognition, existing methods predominantly sample and aggregate events in a second-level duration at every fixed temporal interval (or frequency). However, they often face difficulties in capturing the spatiotemporal relationships for longer, e.g., minute-level, events and generalizing across varying temporal frequencies. To fill the gap, we present a novel framework, dubbed PAST-SSM, exhibiting superior capacity in recognizing events with arbitrary duration (e.g., 0.1s to 4.5s) and generalizing to varying inference frequencies. Our key insight is to learn the spatiotemporal relationships from the encoded event features via the state space model (SSM) -- whose linear complexity makes it ideal for modeling high temporal resolution events with longer sequences. To achieve this goal, we first propose a Path-Adaptive Event Aggregation and Scan (PEAS) module to encode events of varying duration into features with fixed dimensions by adaptively scanning and selecting aggregated event frames. On top of PEAS, we introduce a novel Multi-faceted Selection Guiding (MSG) loss to minimize the randomness and redundancy of the encoded features. This subtly enhances the model generalization across different inference frequencies. Lastly, the SSM is employed to better learn the spatiotemporal properties from the encoded features. Moreover, we build a minute-level event-based recognition dataset, named ArDVS100, with arbitrary duration for the benefit of the community. Extensive experiments prove that our method outperforms prior arts by +3.45%, +0.38% and +8.31% on the DVS Action, SeAct and HARDVS datasets, respectively.
Centering the Value of Every Modality: Towards Efficient and Resilient Modality-agnostic Semantic Segmentation
Jul 16, 2024Fusing an arbitrary number of modalities is vital for achieving robust multi-modal fusion of semantic segmentation yet remains less explored to date. Recent endeavors regard RGB modality as the center and the others as the auxiliary, yielding an asymmetric architecture with two branches. However, the RGB modality may struggle in certain circumstances, e.g., nighttime, while others, e.g., event data, own their merits; thus, it is imperative for the fusion model to discern robust and fragile modalities, and incorporate the most robust and fragile ones to learn a resilient multi-modal framework. To this end, we propose a novel method, named MAGIC, that can be flexibly paired with various backbones, ranging from compact to high-performance models. Our method comprises two key plug-and-play modules. Firstly, we introduce a multi-modal aggregation module to efficiently process features from multi-modal batches and extract complementary scene information. On top, a unified arbitrary-modal selection module is proposed to utilize the aggregated features as the benchmark to rank the multi-modal features based on the similarity scores. This way, our method can eliminate the dependence on RGB modality and better overcome sensor failures while ensuring the segmentation performance. Under the commonly considered multi-modal setting, our method achieves state-of-the-art performance while reducing the model parameters by 60%. Moreover, our method is superior in the novel modality-agnostic setting, where it outperforms prior arts by a large margin of +19.41% mIoU
EIT-1M: One Million EEG-Image-Text Pairs for Human Visual-textual Recognition and More
Jul 02, 2024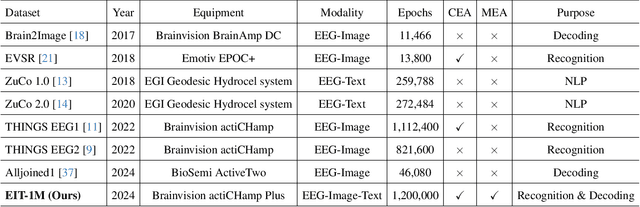
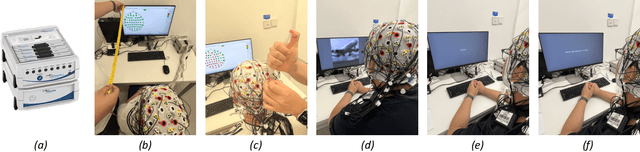
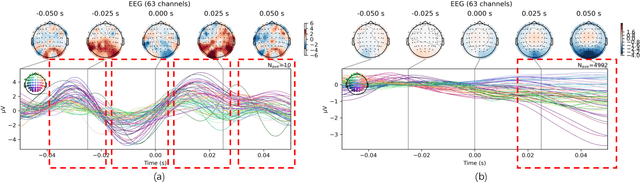
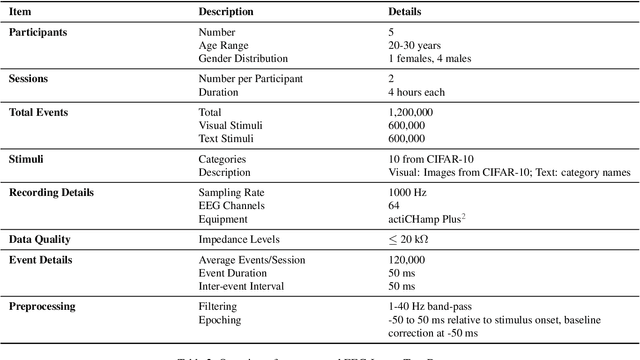
Recently, electroencephalography (EEG) signals have been actively incorporated to decode brain activity to visual or textual stimuli and achieve object recognition in multi-modal AI. Accordingly, endeavors have been focused on building EEG-based datasets from visual or textual single-modal stimuli. However, these datasets offer limited EEG epochs per category, and the complex semantics of stimuli presented to participants compromise their quality and fidelity in capturing precise brain activity. The study in neuroscience unveils that the relationship between visual and textual stimulus in EEG recordings provides valuable insights into the brain's ability to process and integrate multi-modal information simultaneously. Inspired by this, we propose a novel large-scale multi-modal dataset, named EIT-1M, with over 1 million EEG-image-text pairs. Our dataset is superior in its capacity of reflecting brain activities in simultaneously processing multi-modal information. To achieve this, we collected data pairs while participants viewed alternating sequences of visual-textual stimuli from 60K natural images and category-specific texts. Common semantic categories are also included to elicit better reactions from participants' brains. Meanwhile, response-based stimulus timing and repetition across blocks and sessions are included to ensure data diversity. To verify the effectiveness of EIT-1M, we provide an in-depth analysis of EEG data captured from multi-modal stimuli across different categories and participants, along with data quality scores for transparency. We demonstrate its validity on two tasks: 1) EEG recognition from visual or textual stimuli or both and 2) EEG-to-visual generation.
UniBind: LLM-Augmented Unified and Balanced Representation Space to Bind Them All
Mar 19, 2024We present UniBind, a flexible and efficient approach that learns a unified representation space for seven diverse modalities -- images, text, audio, point cloud, thermal, video, and event data. Existing works, eg., ImageBind, treat the image as the central modality and build an image-centered representation space; however, the space may be sub-optimal as it leads to an unbalanced representation space among all modalities. Moreover, the category names are directly used to extract text embeddings for the downstream tasks, making it hardly possible to represent the semantics of multi-modal data. The 'out-of-the-box' insight of our UniBind is to make the alignment center modality-agnostic and further learn a unified and balanced representation space, empowered by the large language models (LLMs). UniBind is superior in its flexible application to all CLIP-style models and delivers remarkable performance boosts. To make this possible, we 1) construct a knowledge base of text embeddings with the help of LLMs and multi-modal LLMs; 2) adaptively build LLM-augmented class-wise embedding center on top of the knowledge base and encoded visual embeddings; 3) align all the embeddings to the LLM-augmented embedding center via contrastive learning to achieve a unified and balanced representation space. UniBind shows strong zero-shot recognition performance gains over prior arts by an average of 6.36%. Finally, we achieve new state-of-the-art performance, eg., a 6.75% gain on ImageNet, on the multi-modal fine-tuning setting while reducing 90% of the learnable parameters.
ExACT: Language-guided Conceptual Reasoning and Uncertainty Estimation for Event-based Action Recognition and More
Mar 19, 2024Event cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior recognition accuracy of 94.83%(+2.23%), 90.10%(+37.47%) and 67.24% on PAF, HARDVS and our SeAct datasets respectively.
E-CLIP: Towards Label-efficient Event-based Open-world Understanding by CLIP
Aug 06, 2023Contrasting Language-image pertaining (CLIP) has recently shown promising open-world and few-shot performance on 2D image-based recognition tasks. However, the transferred capability of CLIP to the novel event camera data still remains under-explored. In particular, due to the modality gap with the image-text data and the lack of large-scale datasets, achieving this goal is non-trivial and thus requires significant research innovation. In this paper, we propose E-CLIP, a novel and effective framework that unleashes the potential of CLIP for event-based recognition to compensate for the lack of large-scale event-based datasets. Our work addresses two crucial challenges: 1) how to generalize CLIP's visual encoder to event data while fully leveraging events' unique properties, e.g., sparsity and high temporal resolution; 2) how to effectively align the multi-modal embeddings, i.e., image, text, and events. To this end, we first introduce a novel event encoder that subtly models the temporal information from events and meanwhile generates event prompts to promote the modality bridging. We then design a text encoder that generates content prompts and utilizes hybrid text prompts to enhance the E-CLIP's generalization ability across diverse datasets. With the proposed event encoder, text encoder, and original image encoder, a novel Hierarchical Triple Contrastive Alignment (HTCA) module is introduced to jointly optimize the correlation and enable efficient knowledge transfer among the three modalities. We conduct extensive experiments on two recognition benchmarks, and the results demonstrate that our E-CLIP outperforms existing methods by a large margin of +3.94% and +4.62% on the N-Caltech dataset, respectively, in both fine-tuning and few-shot settings. Moreover, our E-CLIP can be flexibly extended to the event retrieval task using both text or image queries, showing plausible performance.