 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA4-Agent: An Agentic Framework for Zero-Shot Affordance Reasoning
Dec 16, 2025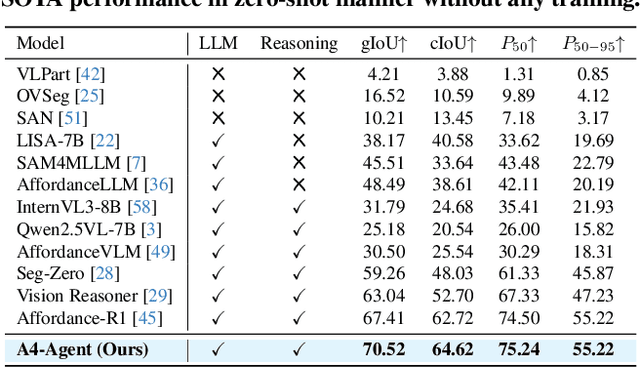
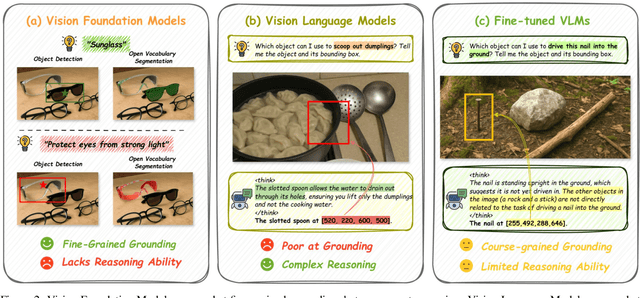
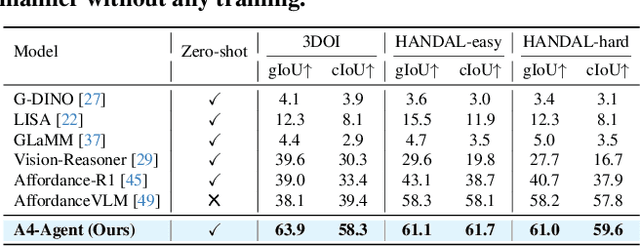
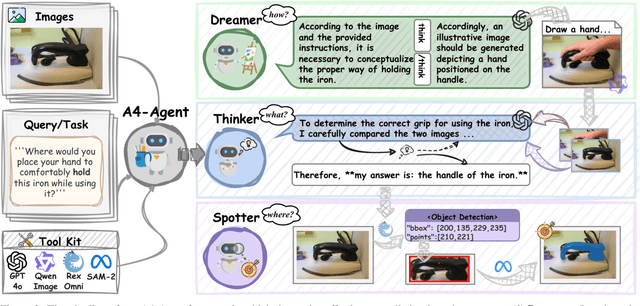
Affordance prediction, which identifies interaction regions on objects based on language instructions, is critical for embodied AI. Prevailing end-to-end models couple high-level reasoning and low-level grounding into a single monolithic pipeline and rely on training over annotated datasets, which leads to poor generalization on novel objects and unseen environments. In this paper, we move beyond this paradigm by proposing A4-Agent, a training-free agentic framework that decouples affordance prediction into a three-stage pipeline. Our framework coordinates specialized foundation models at test time: (1) a $\textbf{Dreamer}$ that employs generative models to visualize $\textit{how}$ an interaction would look; (2) a $\textbf{Thinker}$ that utilizes large vision-language models to decide $\textit{what}$ object part to interact with; and (3) a $\textbf{Spotter}$ that orchestrates vision foundation models to precisely locate $\textit{where}$ the interaction area is. By leveraging the complementary strengths of pre-trained models without any task-specific fine-tuning, our zero-shot framework significantly outperforms state-of-the-art supervised methods across multiple benchmarks and demonstrates robust generalization to real-world settings.
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
T-Rex-Omni: Integrating Negative Visual Prompt in Generic Object Detection
Nov 12, 2025Object detection methods have evolved from closed-set to open-set paradigms over the years. Current open-set object detectors, however, remain constrained by their exclusive reliance on positive indicators based on given prompts like text descriptions or visual exemplars. This positive-only paradigm experiences consistent vulnerability to visually similar but semantically different distractors. We propose T-Rex-Omni, a novel framework that addresses this limitation by incorporating negative visual prompts to negate hard negative distractors. Specifically, we first introduce a unified visual prompt encoder that jointly processes positive and negative visual prompts. Next, a training-free Negating Negative Computing (NNC) module is proposed to dynamically suppress negative responses during the probability computing stage. To further boost performance through fine-tuning, our Negating Negative Hinge (NNH) loss enforces discriminative margins between positive and negative embeddings. T-Rex-Omni supports flexible deployment in both positive-only and joint positive-negative inference modes, accommodating either user-specified or automatically generated negative examples. Extensive experiments demonstrate remarkable zero-shot detection performance, significantly narrowing the performance gap between visual-prompted and text-prompted methods while showing particular strength in long-tailed scenarios (51.2 AP_r on LVIS-minival). This work establishes negative prompts as a crucial new dimension for advancing open-set visual recognition systems.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.
Hierarchical Vision-Language Learning for Medical Out-of-Distribution Detection
Aug 25, 2025


In trustworthy medical diagnosis systems, integrating out-of-distribution (OOD) detection aims to identify unknown diseases in samples, thereby mitigating the risk of misdiagnosis. In this study, we propose a novel OOD detection framework based on vision-language models (VLMs), which integrates hierarchical visual information to cope with challenging unknown diseases that resemble known diseases. Specifically, a cross-scale visual fusion strategy is proposed to couple visual embeddings from multiple scales. This enriches the detailed representation of medical images and thus improves the discrimination of unknown diseases. Moreover, a cross-scale hard pseudo-OOD sample generation strategy is proposed to benefit OOD detection maximally. Experimental evaluations on three public medical datasets support that the proposed framework achieves superior OOD detection performance compared to existing methods. The source code is available at https://openi.pcl.ac.cn/OpenMedIA/HVL.
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025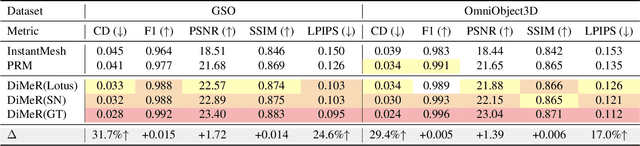

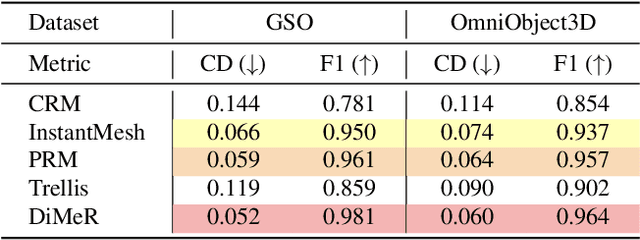
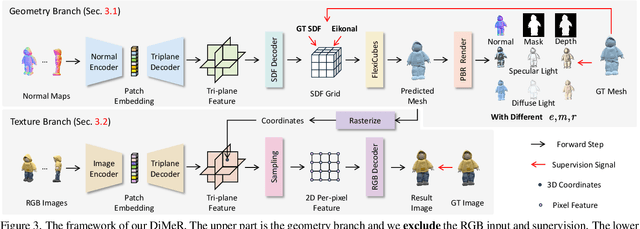
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.
Path-adaptive Spatio-Temporal State Space Model for Event-based Recognition with Arbitrary Duration
Sep 25, 2024Event cameras are bio-inspired sensors that capture the intensity changes asynchronously and output event streams with distinct advantages, such as high temporal resolution. To exploit event cameras for object/action recognition, existing methods predominantly sample and aggregate events in a second-level duration at every fixed temporal interval (or frequency). However, they often face difficulties in capturing the spatiotemporal relationships for longer, e.g., minute-level, events and generalizing across varying temporal frequencies. To fill the gap, we present a novel framework, dubbed PAST-SSM, exhibiting superior capacity in recognizing events with arbitrary duration (e.g., 0.1s to 4.5s) and generalizing to varying inference frequencies. Our key insight is to learn the spatiotemporal relationships from the encoded event features via the state space model (SSM) -- whose linear complexity makes it ideal for modeling high temporal resolution events with longer sequences. To achieve this goal, we first propose a Path-Adaptive Event Aggregation and Scan (PEAS) module to encode events of varying duration into features with fixed dimensions by adaptively scanning and selecting aggregated event frames. On top of PEAS, we introduce a novel Multi-faceted Selection Guiding (MSG) loss to minimize the randomness and redundancy of the encoded features. This subtly enhances the model generalization across different inference frequencies. Lastly, the SSM is employed to better learn the spatiotemporal properties from the encoded features. Moreover, we build a minute-level event-based recognition dataset, named ArDVS100, with arbitrary duration for the benefit of the community. Extensive experiments prove that our method outperforms prior arts by +3.45%, +0.38% and +8.31% on the DVS Action, SeAct and HARDVS datasets, respectively.
ExFMan: Rendering 3D Dynamic Humans with Hybrid Monocular Blurry Frames and Events
Sep 21, 2024Recent years have witnessed tremendous progress in the 3D reconstruction of dynamic humans from a monocular video with the advent of neural rendering techniques. This task has a wide range of applications, including the creation of virtual characters for virtual reality (VR) environments. However, it is still challenging to reconstruct clear humans when the monocular video is affected by motion blur, particularly caused by rapid human motion (e.g., running, dancing), as often occurs in the wild. This leads to distinct inconsistency of shape and appearance for the rendered 3D humans, especially in the blurry regions with rapid motion, e.g., hands and legs. In this paper, we propose ExFMan, the first neural rendering framework that unveils the possibility of rendering high-quality humans in rapid motion with a hybrid frame-based RGB and bio-inspired event camera. The ``out-of-the-box'' insight is to leverage the high temporal information of event data in a complementary manner and adaptively reweight the effect of losses for both RGB frames and events in the local regions, according to the velocity of the rendered human. This significantly mitigates the inconsistency associated with motion blur in the RGB frames. Specifically, we first formulate a velocity field of the 3D body in the canonical space and render it to image space to identify the body parts with motion blur. We then propose two novel losses, i.e., velocity-aware photometric loss and velocity-relative event loss, to optimize the neural human for both modalities under the guidance of the estimated velocity. In addition, we incorporate novel pose regularization and alpha losses to facilitate continuous pose and clear boundary. Extensive experiments on synthetic and real-world datasets demonstrate that ExFMan can reconstruct sharper and higher quality humans.
EvLight++: Low-Light Video Enhancement with an Event Camera: A Large-Scale Real-World Dataset, Novel Method, and More
Aug 29, 2024Event cameras offer significant advantages for low-light video enhancement, primarily due to their high dynamic range. Current research, however, is severely limited by the absence of large-scale, real-world, and spatio-temporally aligned event-video datasets. To address this, we introduce a large-scale dataset with over 30,000 pairs of frames and events captured under varying illumination. This dataset was curated using a robotic arm that traces a consistent non-linear trajectory, achieving spatial alignment precision under 0.03mm and temporal alignment with errors under 0.01s for 90% of the dataset. Based on the dataset, we propose \textbf{EvLight++}, a novel event-guided low-light video enhancement approach designed for robust performance in real-world scenarios. Firstly, we design a multi-scale holistic fusion branch to integrate structural and textural information from both images and events. To counteract variations in regional illumination and noise, we introduce Signal-to-Noise Ratio (SNR)-guided regional feature selection, enhancing features from high SNR regions and augmenting those from low SNR regions by extracting structural information from events. To incorporate temporal information and ensure temporal coherence, we further introduce a recurrent module and temporal loss in the whole pipeline. Extensive experiments on our and the synthetic SDSD dataset demonstrate that EvLight++ significantly outperforms both single image- and video-based methods by 1.37 dB and 3.71 dB, respectively. To further explore its potential in downstream tasks like semantic segmentation and monocular depth estimation, we extend our datasets by adding pseudo segmentation and depth labels via meticulous annotation efforts with foundation models. Experiments under diverse low-light scenes show that the enhanced results achieve a 15.97% improvement in mIoU for semantic segmentation.
LaSe-E2V: Towards Language-guided Semantic-Aware Event-to-Video Reconstruction
Jul 08, 2024



Event cameras harness advantages such as low latency, high temporal resolution, and high dynamic range (HDR), compared to standard cameras. Due to the distinct imaging paradigm shift, a dominant line of research focuses on event-to-video (E2V) reconstruction to bridge event-based and standard computer vision. However, this task remains challenging due to its inherently ill-posed nature: event cameras only detect the edge and motion information locally. Consequently, the reconstructed videos are often plagued by artifacts and regional blur, primarily caused by the ambiguous semantics of event data. In this paper, we find language naturally conveys abundant semantic information, rendering it stunningly superior in ensuring semantic consistency for E2V reconstruction. Accordingly, we propose a novel framework, called LaSe-E2V, that can achieve semantic-aware high-quality E2V reconstruction from a language-guided perspective, buttressed by the text-conditional diffusion models. However, due to diffusion models' inherent diversity and randomness, it is hardly possible to directly apply them to achieve spatial and temporal consistency for E2V reconstruction. Thus, we first propose an Event-guided Spatiotemporal Attention (ESA) module to condition the event data to the denoising pipeline effectively. We then introduce an event-aware mask loss to ensure temporal coherence and a noise initialization strategy to enhance spatial consistency. Given the absence of event-text-video paired data, we aggregate existing E2V datasets and generate textual descriptions using the tagging models for training and evaluation. Extensive experiments on three datasets covering diverse challenging scenarios (e.g., fast motion, low light) demonstrate the superiority of our method. Dataset and code will be available upon acceptance.