 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATM-Net: Anatomy-Aware Text-Guided Multi-Modal Fusion for Fine-Grained Lumbar Spine Segmentation
Apr 04, 2025Accurate lumbar spine segmentation is crucial for diagnosing spinal disorders. Existing methods typically use coarse-grained segmentation strategies that lack the fine detail needed for precise diagnosis. Additionally, their reliance on visual-only models hinders the capture of anatomical semantics, leading to misclassified categories and poor segmentation details. To address these limitations, we present ATM-Net, an innovative framework that employs an anatomy-aware, text-guided, multi-modal fusion mechanism for fine-grained segmentation of lumbar substructures, i.e., vertebrae (VBs), intervertebral discs (IDs), and spinal canal (SC). ATM-Net adopts the Anatomy-aware Text Prompt Generator (ATPG) to adaptively convert image annotations into anatomy-aware prompts in different views. These insights are further integrated with image features via the Holistic Anatomy-aware Semantic Fusion (HASF) module, building a comprehensive anatomical context. The Channel-wise Contrastive Anatomy-Aware Enhancement (CCAE) module further enhances class discrimination and refines segmentation through class-wise channel-level multi-modal contrastive learning. Extensive experiments on the MRSpineSeg and SPIDER datasets demonstrate that ATM-Net significantly outperforms state-of-the-art methods, with consistent improvements regarding class discrimination and segmentation details. For example, ATM-Net achieves Dice of 79.39% and HD95 of 9.91 pixels on SPIDER, outperforming the competitive SpineParseNet by 8.31% and 4.14 pixels, respectively.
AnomalyControl: Learning Cross-modal Semantic Features for Controllable Anomaly Synthesis
Dec 10, 2024



Anomaly synthesis is a crucial approach to augment abnormal data for advancing anomaly inspection. Based on the knowledge from the large-scale pre-training, existing text-to-image anomaly synthesis methods predominantly focus on textual information or coarse-aligned visual features to guide the entire generation process. However, these methods often lack sufficient descriptors to capture the complicated characteristics of realistic anomalies (e.g., the fine-grained visual pattern of anomalies), limiting the realism and generalization of the generation process. To this end, we propose a novel anomaly synthesis framework called AnomalyControl to learn cross-modal semantic features as guidance signals, which could encode the generalized anomaly cues from text-image reference prompts and improve the realism of synthesized abnormal samples. Specifically, AnomalyControl adopts a flexible and non-matching prompt pair (i.e., a text-image reference prompt and a targeted text prompt), where a Cross-modal Semantic Modeling (CSM) module is designed to extract cross-modal semantic features from the textual and visual descriptors. Then, an Anomaly-Semantic Enhanced Attention (ASEA) mechanism is formulated to allow CSM to focus on the specific visual patterns of the anomaly, thus enhancing the realism and contextual relevance of the generated anomaly features. Treating cross-modal semantic features as the prior, a Semantic Guided Adapter (SGA) is designed to encode effective guidance signals for the adequate and controllable synthesis process. Extensive experiments indicate that AnomalyControl can achieve state-of-the-art results in anomaly synthesis compared with existing methods while exhibiting superior performance for downstream tasks.
VidMan: Exploiting Implicit Dynamics from Video Diffusion Model for Effective Robot Manipulation
Nov 14, 2024Recent advancements utilizing large-scale video data for learning video generation models demonstrate significant potential in understanding complex physical dynamics. It suggests the feasibility of leveraging diverse robot trajectory data to develop a unified, dynamics-aware model to enhance robot manipulation. However, given the relatively small amount of available robot data, directly fitting data without considering the relationship between visual observations and actions could lead to suboptimal data utilization. To this end, we propose VidMan (Video Diffusion for Robot Manipulation), a novel framework that employs a two-stage training mechanism inspired by dual-process theory from neuroscience to enhance stability and improve data utilization efficiency. Specifically, in the first stage, VidMan is pre-trained on the Open X-Embodiment dataset (OXE) for predicting future visual trajectories in a video denoising diffusion manner, enabling the model to develop a long horizontal awareness of the environment's dynamics. In the second stage, a flexible yet effective layer-wise self-attention adapter is introduced to transform VidMan into an efficient inverse dynamics model that predicts action modulated by the implicit dynamics knowledge via parameter sharing. Our VidMan framework outperforms state-of-the-art baseline model GR-1 on the CALVIN benchmark, achieving a 11.7% relative improvement, and demonstrates over 9% precision gains on the OXE small-scale dataset. These results provide compelling evidence that world models can significantly enhance the precision of robot action prediction. Codes and models will be public.
Whole Heart Perfusion with High-Multiband Simultaneous Multislice Imaging via Linear Phase Modulated Extended Field of View (SMILE)
Sep 06, 2024Purpose: To develop a simultaneous multislice (SMS) first-pass perfusion technique that can achieve whole heart coverage with high multi-band factors, while avoiding the issue of slice leakage. Methods: The proposed Simultaneous Multislice Imaging via Linear phase modulated Extended field of view (SMILE) treats the SMS acquisition and reconstruction within an extended field of view framework, allowing arbitrarily under-sampling of phase encoding lines of the extended k-space matrix and enabling the direct application of 2D parallel imaging reconstruction techniques. We presented a theoretical framework that offers insights into the performance of SMILE. We performed retrospective comparison on 28 subjects and prospective perfusion experiments on 49 patients undergoing routine clinical CMR studies with SMILE at multiband (MB) factors of 3-5, with a total acceleration factor ($R$) of 8 and 10 respectively, and compared SMILE to conventional SMS techniques using standard FOV 2D CAIPI acquisition and standard 2D slice separation techniques including split-slice GRAPPA and ROCK-SPIRiT. Results: Retrospective studies demonstrated 5.2 to 8.0 dB improvement in signal to error ratio (SER) of SMILE over CAIPI perfusion. Prospective studies showed good image quality with grades of 4.5 $\pm$ 0.5 for MB=3, $R$=8 and 3.6 $\pm$ 0.8 for MB=5, $R$=10. (5-point Likert Scale) Conclusion: The theoretical derivation and experimental results validate the SMILE's improved performance at high acceleration and MB factors as compared to the existing 2D CAIPI SMS acquisition and reconstruction techniques for first-pass myocardial perfusion imaging.
A Population-to-individual Tuning Framework for Adapting Pretrained LM to On-device User Intent Prediction
Aug 19, 2024
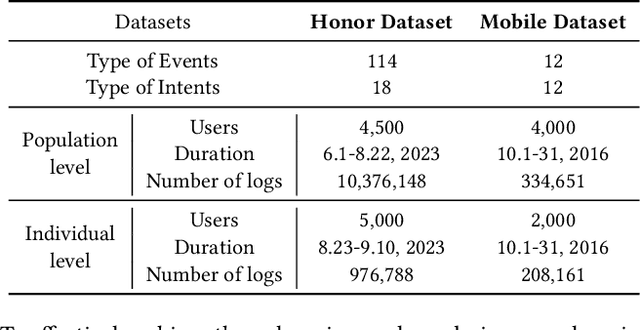


Mobile devices, especially smartphones, can support rich functions and have developed into indispensable tools in daily life. With the rise of generative AI services, smartphones can potentially transform into personalized assistants, anticipating user needs and scheduling services accordingly. Predicting user intents on smartphones, and reflecting anticipated activities based on past interactions and context, remains a pivotal step towards this vision. Existing research predominantly focuses on specific domains, neglecting the challenge of modeling diverse event sequences across dynamic contexts. Leveraging pre-trained language models (PLMs) offers a promising avenue, yet adapting PLMs to on-device user intent prediction presents significant challenges. To address these challenges, we propose PITuning, a Population-to-Individual Tuning framework. PITuning enhances common pattern extraction through dynamic event-to-intent transition modeling and addresses long-tailed preferences via adaptive unlearning strategies. Experimental results on real-world datasets demonstrate PITuning's superior intent prediction performance, highlighting its ability to capture long-tailed preferences and its practicality for on-device prediction scenarios.
Predicting Genetic Mutation from Whole Slide Images via Biomedical-Linguistic Knowledge Enhanced Multi-label Classification
Jun 05, 2024Predicting genetic mutations from whole slide images is indispensable for cancer diagnosis. However, existing work training multiple binary classification models faces two challenges: (a) Training multiple binary classifiers is inefficient and would inevitably lead to a class imbalance problem. (b) The biological relationships among genes are overlooked, which limits the prediction performance. To tackle these challenges, we innovatively design a Biological-knowledge enhanced PathGenomic multi-label Transformer to improve genetic mutation prediction performances. BPGT first establishes a novel gene encoder that constructs gene priors by two carefully designed modules: (a) A gene graph whose node features are the genes' linguistic descriptions and the cancer phenotype, with edges modeled by genes' pathway associations and mutation consistencies. (b) A knowledge association module that fuses linguistic and biomedical knowledge into gene priors by transformer-based graph representation learning, capturing the intrinsic relationships between different genes' mutations. BPGT then designs a label decoder that finally performs genetic mutation prediction by two tailored modules: (a) A modality fusion module that firstly fuses the gene priors with critical regions in WSIs and obtains gene-wise mutation logits. (b) A comparative multi-label loss that emphasizes the inherent comparisons among mutation status to enhance the discrimination capabilities. Sufficient experiments on The Cancer Genome Atlas benchmark demonstrate that BPGT outperforms the state-of-the-art.
VG4D: Vision-Language Model Goes 4D Video Recognition
Apr 17, 2024Understanding the real world through point cloud video is a crucial aspect of robotics and autonomous driving systems. However, prevailing methods for 4D point cloud recognition have limitations due to sensor resolution, which leads to a lack of detailed information. Recent advances have shown that Vision-Language Models (VLM) pre-trained on web-scale text-image datasets can learn fine-grained visual concepts that can be transferred to various downstream tasks. However, effectively integrating VLM into the domain of 4D point clouds remains an unresolved problem. In this work, we propose the Vision-Language Models Goes 4D (VG4D) framework to transfer VLM knowledge from visual-text pre-trained models to a 4D point cloud network. Our approach involves aligning the 4D encoder's representation with a VLM to learn a shared visual and text space from training on large-scale image-text pairs. By transferring the knowledge of the VLM to the 4D encoder and combining the VLM, our VG4D achieves improved recognition performance. To enhance the 4D encoder, we modernize the classic dynamic point cloud backbone and propose an improved version of PSTNet, im-PSTNet, which can efficiently model point cloud videos. Experiments demonstrate that our method achieves state-of-the-art performance for action recognition on both the NTU RGB+D 60 dataset and the NTU RGB+D 120 dataset. Code is available at \url{https://github.com/Shark0-0/VG4D}.
ModelNet-O: A Large-Scale Synthetic Dataset for Occlusion-Aware Point Cloud Classification
Jan 16, 2024



Recently, 3D point cloud classification has made significant progress with the help of many datasets. However, these datasets do not reflect the incomplete nature of real-world point clouds caused by occlusion, which limits the practical application of current methods. To bridge this gap, we propose ModelNet-O, a large-scale synthetic dataset of 123,041 samples that emulate real-world point clouds with self-occlusion caused by scanning from monocular cameras. ModelNet-O is 10 times larger than existing datasets and offers more challenging cases to evaluate the robustness of existing methods. Our observation on ModelNet-O reveals that well-designed sparse structures can preserve structural information of point clouds under occlusion, motivating us to propose a robust point cloud processing method that leverages a critical point sampling (CPS) strategy in a multi-level manner. We term our method PointMLS. Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets, and it is robust and effective. More experiments also demonstrate the robustness and effectiveness of PointMLS.
Explore Human Parsing Modality for Action Recognition
Jan 04, 2024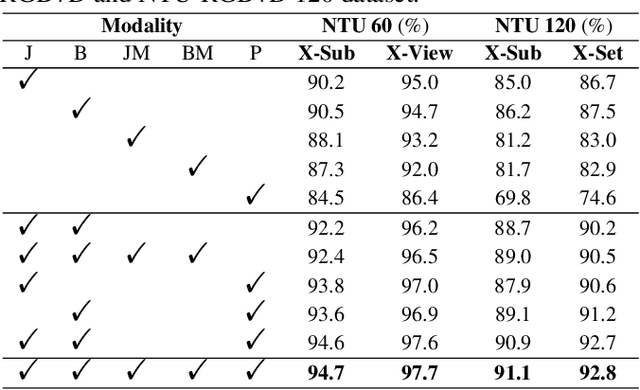

Multimodal-based action recognition methods have achieved high success using pose and RGB modality. However, skeletons sequences lack appearance depiction and RGB images suffer irrelevant noise due to modality limitations. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain effective semantic features of the body parts, while filtering out most irrelevant noise. We propose a new dual-branch framework called Ensemble Human Parsing and Pose Network (EPP-Net), which is the first to leverage both skeletons and human parsing modalities for action recognition. The first human pose branch feeds robust skeletons in graph convolutional network to model pose features, while the second human parsing branch also leverages depictive parsing feature maps to model parsing festures via convolutional backbones. The two high-level features will be effectively combined through a late fusion strategy for better action recognition. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of our proposed EPP-Net, which outperforms the existing action recognition methods. Our code is available at: https://github.com/liujf69/EPP-Net-Action.
How to Efficiently Annotate Images for Best-Performing Deep Learning Based Segmentation Models: An Empirical Study with Weak and Noisy Annotations and Segment Anything Model
Dec 20, 2023Deep neural networks (DNNs) have been deployed for many image segmentation tasks and achieved outstanding performance. However, preparing a dataset for training segmentation DNNs is laborious and costly since typically pixel-level annotations are provided for each object of interest. To alleviate this issue, one can provide only weak labels such as bounding boxes or scribbles, or less accurate (noisy) annotations of the objects. These are significantly faster to generate and thus result in more annotated images given the same time budget. However, the reduction in quality might negatively affect the segmentation performance of the resulting model. In this study, we perform a thorough cost-effectiveness evaluation of several weak and noisy labels. We considered 11 variants of annotation strategies and 4 datasets. We conclude that the common practice of accurately outlining the objects of interest is virtually never the optimal approach when the annotation time is limited, even if notable annotation time is available (10s of hours). Annotation approaches that stood out in such scenarios were (1) contour-based annotation with rough continuous traces, (2) polygon-based annotation with few vertices, and (3) box annotations combined with the Segment Anything Model (SAM). In situations where unlimited annotation time was available, precise annotations still lead to the highest segmentation model performance.