 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiEvLight: Bi-level Learning of Task-Aware Event Refinement for Low-Light Image Enhancement
Mar 05, 2026Event cameras, with their high dynamic range, show great promise for Low-light Image Enhancement (LLIE). Existing works primarily focus on designing effective modal fusion strategies. However, a key challenge is the dual degradation from intrinsic background activity (BA) noise in events and low signal-to-noise ratio (SNR) in images, which causes severe noise coupling during modal fusion, creating a critical performance bottleneck. We therefore posit that precise event denoising is the prerequisite to unlocking the full potential of event-based fusion. To this end, we propose BiEvLight, a hierarchical and task-aware framework that collaboratively optimizes enhancement and denoising by exploiting their intrinsic interdependence. Specifically, BiEvLight exploits the strong gradient correlation between images and events to build a gradient-guided event denoising prior that alleviates insufficient denoising in heavily noisy regions. Moreover, instead of treating event denoising as a static pre-processing stage-which inevitably incurs a trade-off between over- and under-denoising and cannot adapt to the requirements of a specific enhancement objective-we recast it as a bilevel optimization problem constrained by the enhancement task. Through cross-task interaction, the upper-level denoising problem learns event representations tailored to the lower-level enhancement objective, thereby substantially improving overall enhancement quality. Extensive experiments on the Real-world noise Dataset SDE demonstrate that our method significantly outperforms state-of-the-art (SOTA) approaches, with average improvements of 1.30dB in PSNR, 2.03dB in PSNR* and 0.047 in SSIM, respectively. The code will be publicly available at https://github.com/iijjlk/BiEvlight.
Wavelet-Guided Dual-Frequency Encoding for Remote Sensing Change Detection
Aug 07, 2025Change detection in remote sensing imagery plays a vital role in various engineering applications, such as natural disaster monitoring, urban expansion tracking, and infrastructure management. Despite the remarkable progress of deep learning in recent years, most existing methods still rely on spatial-domain modeling, where the limited diversity of feature representations hinders the detection of subtle change regions. We observe that frequency-domain feature modeling particularly in the wavelet domain an amplify fine-grained differences in frequency components, enhancing the perception of edge changes that are challenging to capture in the spatial domain. Thus, we propose a method called Wavelet-Guided Dual-Frequency Encoding (WGDF). Specifically, we first apply Discrete Wavelet Transform (DWT) to decompose the input images into high-frequency and low-frequency components, which are used to model local details and global structures, respectively. In the high-frequency branch, we design a Dual-Frequency Feature Enhancement (DFFE) module to strengthen edge detail representation and introduce a Frequency-Domain Interactive Difference (FDID) module to enhance the modeling of fine-grained changes. In the low-frequency branch, we exploit Transformers to capture global semantic relationships and employ a Progressive Contextual Difference Module (PCDM) to progressively refine change regions, enabling precise structural semantic characterization. Finally, the high- and low-frequency features are synergistically fused to unify local sensitivity with global discriminability. Extensive experiments on multiple remote sensing datasets demonstrate that WGDF significantly alleviates edge ambiguity and achieves superior detection accuracy and robustness compared to state-of-the-art methods. The code will be available at https://github.com/boshizhang123/WGDF.
CoA: Towards Real Image Dehazing via Compression-and-Adaptation
Apr 08, 2025Learning-based image dehazing algorithms have shown remarkable success in synthetic domains. However, real image dehazing is still in suspense due to computational resource constraints and the diversity of real-world scenes. Therefore, there is an urgent need for an algorithm that excels in both efficiency and adaptability to address real image dehazing effectively. This work proposes a Compression-and-Adaptation (CoA) computational flow to tackle these challenges from a divide-and-conquer perspective. First, model compression is performed in the synthetic domain to develop a compact dehazing parameter space, satisfying efficiency demands. Then, a bilevel adaptation in the real domain is introduced to be fearless in unknown real environments by aggregating the synthetic dehazing capabilities during the learning process. Leveraging a succinct design free from additional constraints, our CoA exhibits domain-irrelevant stability and model-agnostic flexibility, effectively bridging the model chasm between synthetic and real domains to further improve its practical utility. Extensive evaluations and analyses underscore the approach's superiority and effectiveness. The code is publicly available at https://github.com/fyxnl/COA.
ATM-Net: Anatomy-Aware Text-Guided Multi-Modal Fusion for Fine-Grained Lumbar Spine Segmentation
Apr 04, 2025Accurate lumbar spine segmentation is crucial for diagnosing spinal disorders. Existing methods typically use coarse-grained segmentation strategies that lack the fine detail needed for precise diagnosis. Additionally, their reliance on visual-only models hinders the capture of anatomical semantics, leading to misclassified categories and poor segmentation details. To address these limitations, we present ATM-Net, an innovative framework that employs an anatomy-aware, text-guided, multi-modal fusion mechanism for fine-grained segmentation of lumbar substructures, i.e., vertebrae (VBs), intervertebral discs (IDs), and spinal canal (SC). ATM-Net adopts the Anatomy-aware Text Prompt Generator (ATPG) to adaptively convert image annotations into anatomy-aware prompts in different views. These insights are further integrated with image features via the Holistic Anatomy-aware Semantic Fusion (HASF) module, building a comprehensive anatomical context. The Channel-wise Contrastive Anatomy-Aware Enhancement (CCAE) module further enhances class discrimination and refines segmentation through class-wise channel-level multi-modal contrastive learning. Extensive experiments on the MRSpineSeg and SPIDER datasets demonstrate that ATM-Net significantly outperforms state-of-the-art methods, with consistent improvements regarding class discrimination and segmentation details. For example, ATM-Net achieves Dice of 79.39% and HD95 of 9.91 pixels on SPIDER, outperforming the competitive SpineParseNet by 8.31% and 4.14 pixels, respectively.
High-Similarity-Pass Attention for Single Image Super-Resolution
May 25, 2023



Recent developments in the field of non-local attention (NLA) have led to a renewed interest in self-similarity-based single image super-resolution (SISR). Researchers usually used the NLA to explore non-local self-similarity (NSS) in SISR and achieve satisfactory reconstruction results. However, a surprising phenomenon that the reconstruction performance of the standard NLA is similar to the NLA with randomly selected regions stimulated our interest to revisit NLA. In this paper, we first analyzed the attention map of the standard NLA from different perspectives and discovered that the resulting probability distribution always has full support for every local feature, which implies a statistical waste of assigning values to irrelevant non-local features, especially for SISR which needs to model long-range dependence with a large number of redundant non-local features. Based on these findings, we introduced a concise yet effective soft thresholding operation to obtain high-similarity-pass attention (HSPA), which is beneficial for generating a more compact and interpretable distribution. Furthermore, we derived some key properties of the soft thresholding operation that enable training our HSPA in an end-to-end manner. The HSPA can be integrated into existing deep SISR models as an efficient general building block. In addition, to demonstrate the effectiveness of the HSPA, we constructed a deep high-similarity-pass attention network (HSPAN) by integrating a few HSPAs in a simple backbone. Extensive experimental results demonstrate that HSPAN outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Properties and Potential Applications of Random Functional-Linked Types of Neural Networks
Apr 03, 2023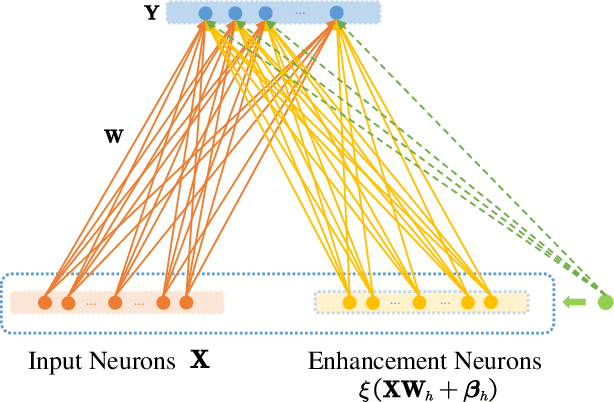
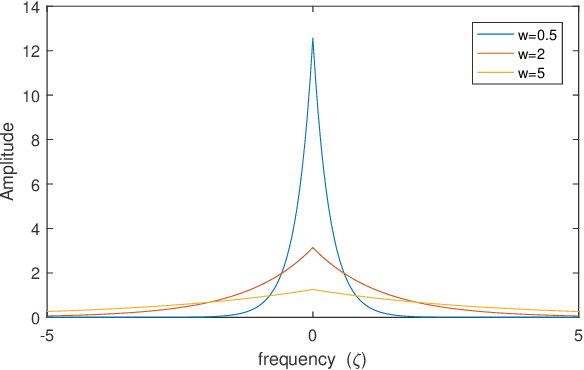
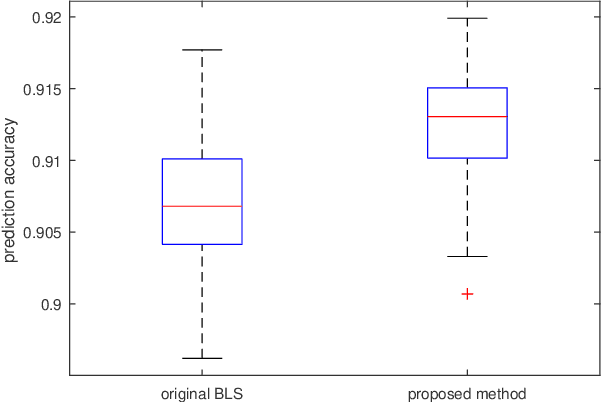
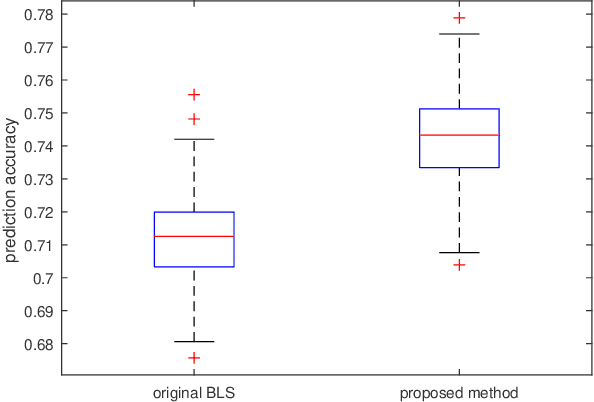
Random functional-linked types of neural networks (RFLNNs), e.g., the extreme learning machine (ELM) and broad learning system (BLS), which avoid suffering from a time-consuming training process, offer an alternative way of learning in deep structure. The RFLNNs have achieved excellent performance in various classification and regression tasks, however, the properties and explanations of these networks are ignored in previous research. This paper gives some insights into the properties of RFLNNs from the viewpoints of frequency domain, and discovers the presence of frequency principle in these networks, that is, they preferentially capture low-frequencies quickly and then fit the high frequency components during the training process. These findings are valuable for understanding the RFLNNs and expanding their applications. Guided by the frequency principle, we propose a method to generate a BLS network with better performance, and design an efficient algorithm for solving Poison's equation in view of the different frequency principle presenting in the Jacobi iterative method and BLS network.
Global Learnable Attention for Single Image Super-Resolution
Dec 02, 2022Self-similarity is valuable to the exploration of non-local textures in single image super-resolution (SISR). Researchers usually assume that the importance of non-local textures is positively related to their similarity scores. In this paper, we surprisingly found that when repairing severely damaged query textures, some non-local textures with low-similarity which are closer to the target can provide more accurate and richer details than the high-similarity ones. In these cases, low-similarity does not mean inferior but is usually caused by different scales or orientations. Utilizing this finding, we proposed a Global Learnable Attention (GLA) to adaptively modify similarity scores of non-local textures during training instead of only using a fixed similarity scoring function such as the dot product. The proposed GLA can explore non-local textures with low-similarity but more accurate details to repair severely damaged textures. Furthermore, we propose to adopt Super-Bit Locality-Sensitive Hashing (SB-LSH) as a preprocessing method for our GLA. With the SB-LSH, the computational complexity of our GLA is reduced from quadratic to asymptotic linear with respect to the image size. In addition, the proposed GLA can be integrated into existing deep SISR models as an efficient general building block. Based on the GLA, we constructed a Deep Learnable Similarity Network (DLSN), which achieves state-of-the-art performance for SISR tasks of different degradation types (e.g. blur and noise). Our code and a pre-trained DLSN have been uploaded to GitHub{\dag} for validation.