 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster than Fast: Accelerating Oriented FAST Feature Detection on Low-end Embedded GPUs
Jun 08, 2025The visual-based SLAM (Simultaneous Localization and Mapping) is a technology widely used in applications such as robotic navigation and virtual reality, which primarily focuses on detecting feature points from visual images to construct an unknown environmental map and simultaneously determines its own location. It usually imposes stringent requirements on hardware power consumption, processing speed and accuracy. Currently, the ORB (Oriented FAST and Rotated BRIEF)-based SLAM systems have exhibited superior performance in terms of processing speed and robustness. However, they still fall short of meeting the demands for real-time processing on mobile platforms. This limitation is primarily due to the time-consuming Oriented FAST calculations accounting for approximately half of the entire SLAM system. This paper presents two methods to accelerate the Oriented FAST feature detection on low-end embedded GPUs. These methods optimize the most time-consuming steps in Oriented FAST feature detection: FAST feature point detection and Harris corner detection, which is achieved by implementing a binary-level encoding strategy to determine candidate points quickly and a separable Harris detection strategy with efficient low-level GPU hardware-specific instructions. Extensive experiments on a Jetson TX2 embedded GPU demonstrate an average speedup of over 7.3 times compared to widely used OpenCV with GPU support. This significant improvement highlights its effectiveness and potential for real-time applications in mobile and resource-constrained environments.
Point2Quad: Generating Quad Meshes from Point Clouds via Face Prediction
Apr 28, 2025Quad meshes are essential in geometric modeling and computational mechanics. Although learning-based methods for triangle mesh demonstrate considerable advancements, quad mesh generation remains less explored due to the challenge of ensuring coplanarity, convexity, and quad-only meshes. In this paper, we present Point2Quad, the first learning-based method for quad-only mesh generation from point clouds. The key idea is learning to identify quad mesh with fused pointwise and facewise features. Specifically, Point2Quad begins with a k-NN-based candidate generation considering the coplanarity and squareness. Then, two encoders are followed to extract geometric and topological features that address the challenge of quad-related constraints, especially by combining in-depth quadrilaterals-specific characteristics. Subsequently, the extracted features are fused to train the classifier with a designed compound loss. The final results are derived after the refinement by a quad-specific post-processing. Extensive experiments on both clear and noise data demonstrate the effectiveness and superiority of Point2Quad, compared to baseline methods under comprehensive metrics.
CoA: Towards Real Image Dehazing via Compression-and-Adaptation
Apr 08, 2025Learning-based image dehazing algorithms have shown remarkable success in synthetic domains. However, real image dehazing is still in suspense due to computational resource constraints and the diversity of real-world scenes. Therefore, there is an urgent need for an algorithm that excels in both efficiency and adaptability to address real image dehazing effectively. This work proposes a Compression-and-Adaptation (CoA) computational flow to tackle these challenges from a divide-and-conquer perspective. First, model compression is performed in the synthetic domain to develop a compact dehazing parameter space, satisfying efficiency demands. Then, a bilevel adaptation in the real domain is introduced to be fearless in unknown real environments by aggregating the synthetic dehazing capabilities during the learning process. Leveraging a succinct design free from additional constraints, our CoA exhibits domain-irrelevant stability and model-agnostic flexibility, effectively bridging the model chasm between synthetic and real domains to further improve its practical utility. Extensive evaluations and analyses underscore the approach's superiority and effectiveness. The code is publicly available at https://github.com/fyxnl/COA.
Unseen No More: Unlocking the Potential of CLIP for Generative Zero-shot HOI Detection
Aug 12, 2024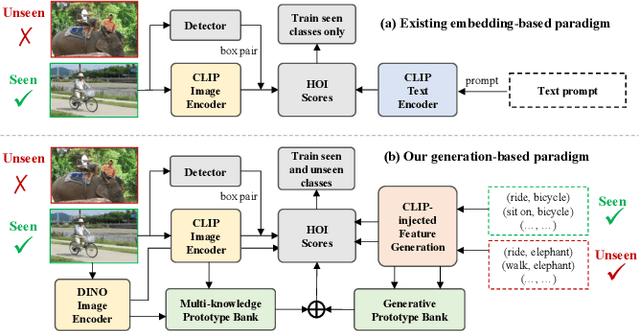
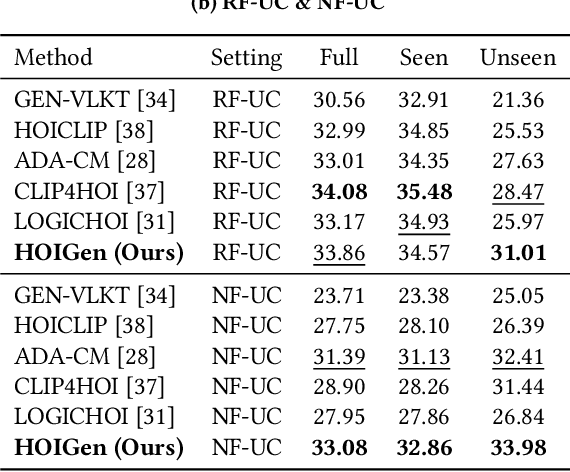
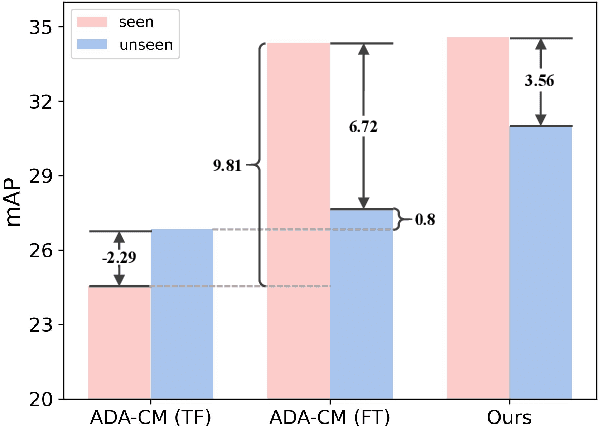
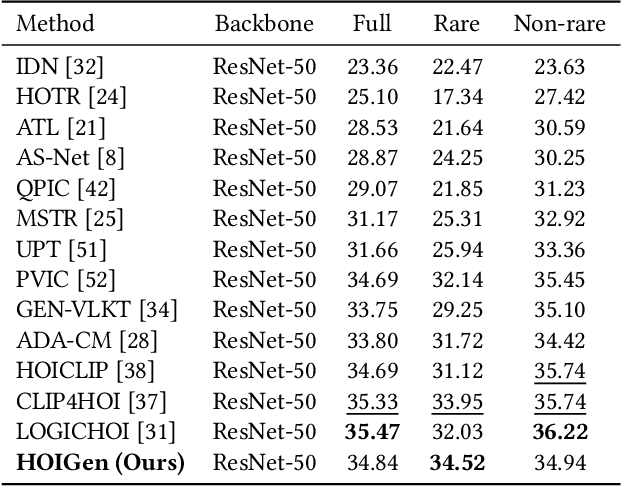
Zero-shot human-object interaction (HOI) detector is capable of generalizing to HOI categories even not encountered during training. Inspired by the impressive zero-shot capabilities offered by CLIP, latest methods strive to leverage CLIP embeddings for improving zero-shot HOI detection. However, these embedding-based methods train the classifier on seen classes only, inevitably resulting in seen-unseen confusion for the model during inference. Besides, we find that using prompt-tuning and adapters further increases the gap between seen and unseen accuracy. To tackle this challenge, we present the first generation-based model using CLIP for zero-shot HOI detection, coined HOIGen. It allows to unlock the potential of CLIP for feature generation instead of feature extraction only. To achieve it, we develop a CLIP-injected feature generator in accordance with the generation of human, object and union features. Then, we extract realistic features of seen samples and mix them with synthetic features together, allowing the model to train seen and unseen classes jointly. To enrich the HOI scores, we construct a generative prototype bank in a pairwise HOI recognition branch, and a multi-knowledge prototype bank in an image-wise HOI recognition branch, respectively. Extensive experiments on HICO-DET benchmark demonstrate our HOIGen achieves superior performance for both seen and unseen classes under various zero-shot settings, compared with other top-performing methods. Code is available at: https://github.com/soberguo/HOIGen
Research on Adverse Drug Reaction Prediction Model Combining Knowledge Graph Embedding and Deep Learning
Jul 27, 2024
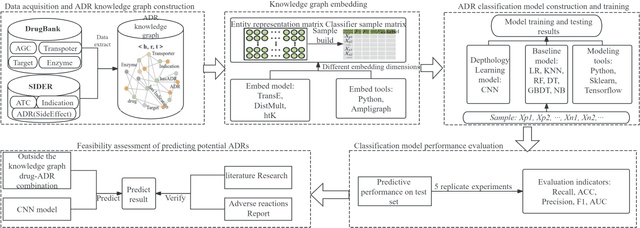
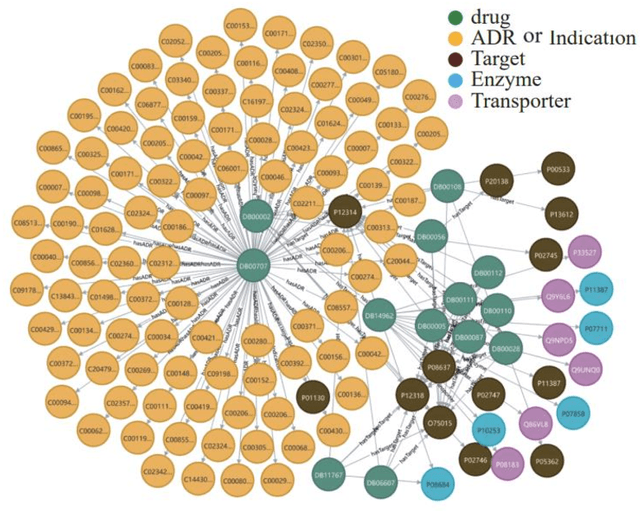

In clinical treatment, identifying potential adverse reactions of drugs can help assist doctors in making medication decisions. In response to the problems in previous studies that features are high-dimensional and sparse, independent prediction models need to be constructed for each adverse reaction of drugs, and the prediction accuracy is low, this paper develops an adverse drug reaction prediction model based on knowledge graph embedding and deep learning, which can predict experimental results. Unified prediction of adverse drug reactions covered. Knowledge graph embedding technology can fuse the associated information between drugs and alleviate the shortcomings of high-dimensional sparsity in feature matrices, and the efficient training capabilities of deep learning can improve the prediction accuracy of the model. This article builds an adverse drug reaction knowledge graph based on drug feature data; by analyzing the embedding effect of the knowledge graph under different embedding strategies, the best embedding strategy is selected to obtain sample vectors; and then a convolutional neural network model is constructed to predict adverse reactions. The results show that under the DistMult embedding model and 400-dimensional embedding strategy, the convolutional neural network model has the best prediction effect; the average accuracy, F_1 score, recall rate and area under the curve of repeated experiments are better than the methods reported in the literature. The obtained prediction model has good prediction accuracy and stability, and can provide an effective reference for later safe medication guidance.
HOTS3D: Hyper-Spherical Optimal Transport for Semantic Alignment of Text-to-3D Generation
Jul 19, 2024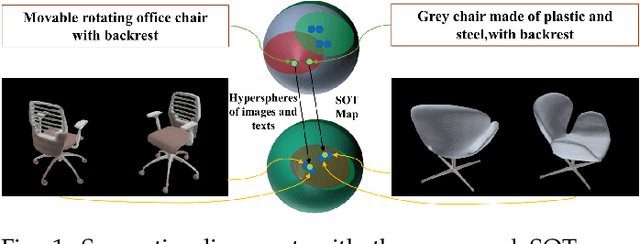
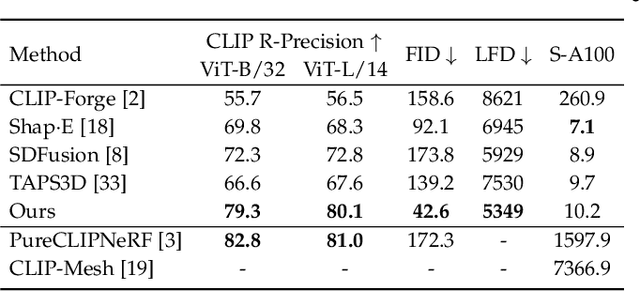
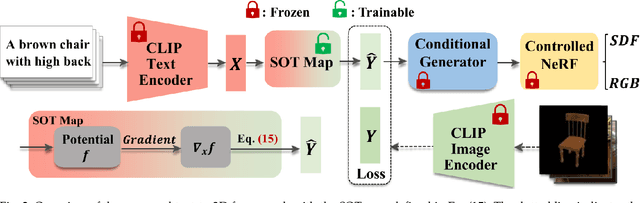
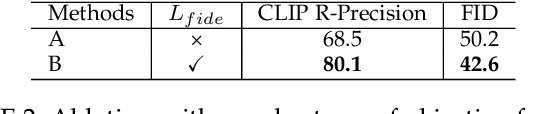
Recent CLIP-guided 3D generation methods have achieved promising results but struggle with generating faithful 3D shapes that conform with input text due to the gap between text and image embeddings. To this end, this paper proposes HOTS3D which makes the first attempt to effectively bridge this gap by aligning text features to the image features with spherical optimal transport (SOT). However, in high-dimensional situations, solving the SOT remains a challenge. To obtain the SOT map for high-dimensional features obtained from CLIP encoding of two modalities, we mathematically formulate and derive the solution based on Villani's theorem, which can directly align two hyper-sphere distributions without manifold exponential maps. Furthermore, we implement it by leveraging input convex neural networks (ICNNs) for the optimal Kantorovich potential. With the optimally mapped features, a diffusion-based generator and a Nerf-based decoder are subsequently utilized to transform them into 3D shapes. Extensive qualitative and qualitative comparisons with state-of-the-arts demonstrate the superiority of the proposed HOTS3D for 3D shape generation, especially on the consistency with text semantics.
MergeNet: Explicit Mesh Reconstruction from Sparse Point Clouds via Edge Prediction
Jul 16, 2024This paper introduces a novel method for reconstructing meshes from sparse point clouds by predicting edge connection. Existing implicit methods usually produce superior smooth and watertight meshes due to the isosurface extraction algorithms~(e.g., Marching Cubes). However, these methods become memory and computationally intensive with increasing resolution. Explicit methods are more efficient by directly forming the face from points. Nevertheless, the challenge of selecting appropriate faces from enormous candidates often leads to undesirable faces and holes. Moreover, the reconstruction performance of both approaches tends to degrade when the point cloud gets sparse. To this end, we propose MEsh Reconstruction via edGE~(MergeNet), which converts mesh reconstruction into local connectivity prediction problems. Specifically, MergeNet learns to extract the features of candidate edges and regress their distances to the underlying surface. Consequently, the predicted distance is utilized to filter out edges that lay on surfaces. Finally, the meshes are reconstructed by refining the triangulations formed by these edges. Extensive experiments on synthetic and real-scanned datasets demonstrate the superiority of MergeNet to SoTA explicit methods.
Novel Class Discovery for Ultra-Fine-Grained Visual Categorization
May 10, 2024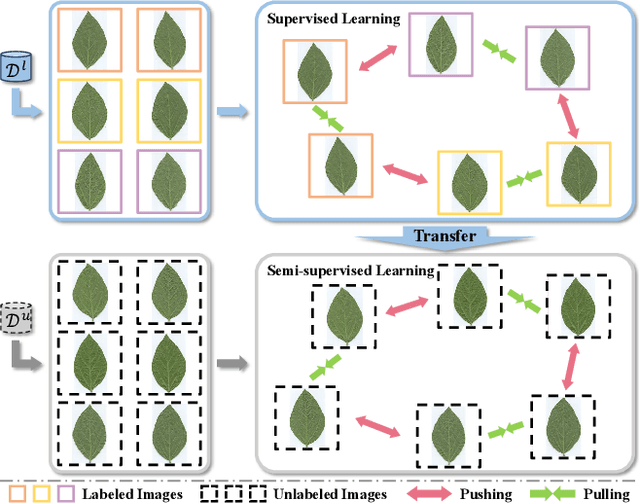
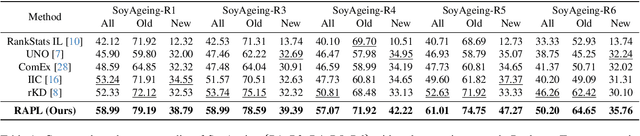
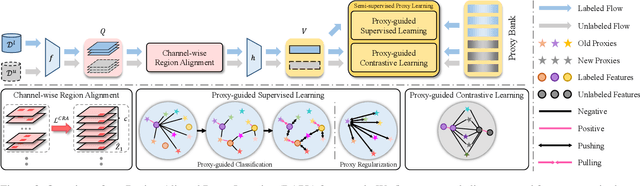
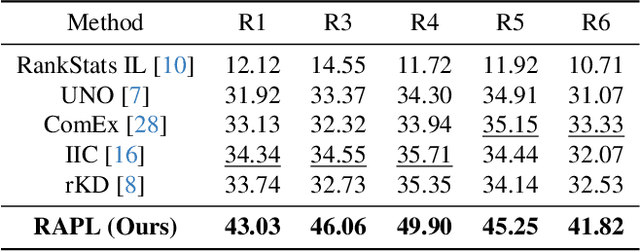
Ultra-fine-grained visual categorization (Ultra-FGVC) aims at distinguishing highly similar sub-categories within fine-grained objects, such as different soybean cultivars. Compared to traditional fine-grained visual categorization, Ultra-FGVC encounters more hurdles due to the small inter-class and large intra-class variation. Given these challenges, relying on human annotation for Ultra-FGVC is impractical. To this end, our work introduces a novel task termed Ultra-Fine-Grained Novel Class Discovery (UFG-NCD), which leverages partially annotated data to identify new categories of unlabeled images for Ultra-FGVC. To tackle this problem, we devise a Region-Aligned Proxy Learning (RAPL) framework, which comprises a Channel-wise Region Alignment (CRA) module and a Semi-Supervised Proxy Learning (SemiPL) strategy. The CRA module is designed to extract and utilize discriminative features from local regions, facilitating knowledge transfer from labeled to unlabeled classes. Furthermore, SemiPL strengthens representation learning and knowledge transfer with proxy-guided supervised learning and proxy-guided contrastive learning. Such techniques leverage class distribution information in the embedding space, improving the mining of subtle differences between labeled and unlabeled ultra-fine-grained classes. Extensive experiments demonstrate that RAPL significantly outperforms baselines across various datasets, indicating its effectiveness in handling the challenges of UFG-NCD. Code is available at https://github.com/SSDUT-Caiyq/UFG-NCD.
Breast Cancer Image Classification Method Based on Deep Transfer Learning
Apr 14, 2024



To address the issues of limited samples, time-consuming feature design, and low accuracy in detection and classification of breast cancer pathological images, a breast cancer image classification model algorithm combining deep learning and transfer learning is proposed. This algorithm is based on the DenseNet structure of deep neural networks, and constructs a network model by introducing attention mechanisms, and trains the enhanced dataset using multi-level transfer learning. Experimental results demonstrate that the algorithm achieves an efficiency of over 84.0\% in the test set, with a significantly improved classification accuracy compared to previous models, making it applicable to medical breast cancer detection tasks.
Convolutional neural network classification of cancer cytopathology images: taking breast cancer as an example
Apr 12, 2024



Breast cancer is a relatively common cancer among gynecological cancers. Its diagnosis often relies on the pathology of cells in the lesion. The pathological diagnosis of breast cancer not only requires professionals and time, but also sometimes involves subjective judgment. To address the challenges of dependence on pathologists expertise and the time-consuming nature of achieving accurate breast pathological image classification, this paper introduces an approach utilizing convolutional neural networks (CNNs) for the rapid categorization of pathological images, aiming to enhance the efficiency of breast pathological image detection. And the approach enables the rapid and automatic classification of pathological images into benign and malignant groups. The methodology involves utilizing a convolutional neural network (CNN) model leveraging the Inceptionv3 architecture and transfer learning algorithm for extracting features from pathological images. Utilizing a neural network with fully connected layers and employing the SoftMax function for image classification. Additionally, the concept of image partitioning is introduced to handle high-resolution images. To achieve the ultimate classification outcome, the classification probabilities of each image block are aggregated using three algorithms: summation, product, and maximum. Experimental validation was conducted on the BreaKHis public dataset, resulting in accuracy rates surpassing 0.92 across all four magnification coefficients (40X, 100X, 200X, and 400X). It demonstrates that the proposed method effectively enhances the accuracy in classifying pathological images of breast cancer.