 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Conflict-Oriented Reasoning for General Multimodal Manipulation Detection
Jun 02, 2026The rapid rise of generative AI has made multimodal fake news increasingly realistic and pervasive, posing severe threats to public trust and social stability. Existing detection methods rely heavily on manipulation-specific models and large-scale labeled data, resulting in poor generalization to emerging manipulation types. We observed that the essence of manipulated misinformation lies in its intrinsic conflicts, \textbf{i.e.,} semantic or physical inconsistencies either across modalities or with common world knowledge. Inspired by this observation, we propose \textbf{C}onflict-\textbf{O}riented \textbf{RE}asoning (\textbf{CORE}) framework, an effective paradigm that learns to endows multimodal large language models (MLLMs) with explicit conflict-capturing capability. To this end, CORE first constructs the Conflict Attribution Corpus (CAC) with fine-grained annotations of conflict factors and sources, providing essential data support for subsequent conflict perception training. By performing conflict-oriented representation enhancement and reasoning based on CAC, CORE achieves robust and generalizable conflict detection, effectively and rapidly adapting to unseen manipulation types with a few samples or in even zero-shot settings. Extensive experiments demonstrate that CORE surpasses state-of-the-art models. The dataset and code are publicly available at https://github.com/shen8424/CORE.
Plug-and-play Class-aware Knowledge Injection for Prompt Learning with Visual-Language Model
May 07, 2026Prompt learning has become an effective and widely used technique in enhancing vision-language models (VLMs) such as CLIP for various downstream tasks, particularly in zero-shot classification within specific domains. Existing methods typically focus on either learning class-shared prompts for a given domain or generating instance-specific prompts through conditional prompt learning. While these methods have achieved promising performance, they often overlook class-specific knowledge in prompt design, leading to suboptimal outcomes. The underlying reasons are: 1) class-specific prompts offer more fine-grained supervision compared to coarse class-shared prompts, which helps prevent misclassification of data from different classes into a single class; 2) compared to class-specific prompts, instance-specific prompts neglect the richer class-level information across multiple instances, potentially causing data from the same class to be divided into multiple classes. To effectively supplement the class-specific knowledge into existing methods, we propose a plug-and-play Class-Aware Knowledge Injection (CAKI) framework. CAKI comprises two key components, i.e., class-specific prompt generation and query-key prompt matching. The former encodes class-specific knowledge into prompts from few-shot samples that belong to the same class and stores the learned prompts in a class-level knowledge bank. The latter provides a plug-and-play mechanism for each test instance to retrieve relevant class-level knowledge from the knowledge bank and inject such knowledge to refine model predictions. Extensive experiments demonstrate that our CAKI effectively improves the performance of existing methods on base and novel classes. Code is publicly available at \href{https://github.com/yjh576/CAKI}{this https URL}.
OmniVL-Guard: Towards Unified Vision-Language Forgery Detection and Grounding via Balanced RL
Feb 12, 2026Existing forgery detection methods are often limited to uni-modal or bi-modal settings, failing to handle the interleaved text, images, and videos prevalent in real-world misinformation. To bridge this gap, this paper targets to develop a unified framework for omnibus vision-language forgery detection and grounding. In this unified setting, the {interplay} between diverse modalities and the dual requirements of simultaneous detection and localization pose a critical ``difficulty bias`` problem: the simpler veracity classification task tends to dominate the gradients, leading to suboptimal performance in fine-grained grounding during multi-task optimization. To address this challenge, we propose \textbf{OmniVL-Guard}, a balanced reinforcement learning framework for omnibus vision-language forgery detection and grounding. Particularly, OmniVL-Guard comprises two core designs: Self-Evolving CoT Generatio and Adaptive Reward Scaling Policy Optimization (ARSPO). {Self-Evolving CoT Generation} synthesizes high-quality reasoning paths, effectively overcoming the cold-start challenge. Building upon this, {Adaptive Reward Scaling Policy Optimization (ARSPO)} dynamically modulates reward scales and task weights, ensuring a balanced joint optimization. Extensive experiments demonstrate that OmniVL-Guard significantly outperforms state-of-the-art methods and exhibits zero-shot robust generalization across out-of-domain scenarios.
Multi-Scale Global-Instance Prompt Tuning for Continual Test-time Adaptation in Medical Image Segmentation
Feb 05, 2026Distribution shift is a common challenge in medical images obtained from different clinical centers, significantly hindering the deployment of pre-trained semantic segmentation models in real-world applications across multiple domains. Continual Test-Time Adaptation(CTTA) has emerged as a promising approach to address cross-domain shifts during continually evolving target domains. Most existing CTTA methods rely on incrementally updating model parameters, which inevitably suffer from error accumulation and catastrophic forgetting, especially in long-term adaptation. Recent prompt-tuning-based works have shown potential to mitigate the two issues above by updating only visual prompts. While these approaches have demonstrated promising performance, several limitations remain:1)lacking multi-scale prompt diversity, 2)inadequate incorporation of instance-specific knowledge, and 3)risk of privacy leakage. To overcome these limitations, we propose Multi-scale Global-Instance Prompt Tuning(MGIPT), to enhance scale diversity of prompts and capture both global- and instance-level knowledge for robust CTTA. Specifically, MGIPT consists of an Adaptive-scale Instance Prompt(AIP) and a Multi-scale Global-level Prompt(MGP). AIP dynamically learns lightweight and instance-specific prompts to mitigate error accumulation with adaptive optimal-scale selection mechanism. MGP captures domain-level knowledge across different scales to ensure robust adaptation with anti-forgetting capabilities. These complementary components are combined through a weighted ensemble approach, enabling effective dual-level adaptation that integrates both global and local information. Extensive experiments on medical image segmentation benchmarks demonstrate that our MGIPT outperforms state-of-the-art methods, achieving robust adaptation across continually changing target domains.
Open-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
Dec 14, 2025The proliferation of synthetic facial imagery has intensified the need for robust Open-World DeepFake Attribution (OW-DFA), which aims to attribute both known and unknown forgeries using labeled data for known types and unlabeled data containing a mixture of known and novel types. However, existing OW-DFA methods face two critical limitations: 1) A confidence skew that leads to unreliable pseudo-labels for novel forgeries, resulting in biased training. 2) An unrealistic assumption that the number of unknown forgery types is known *a priori*. To address these challenges, we propose a Confidence-Aware Asymmetric Learning (CAL) framework, which adaptively balances model confidence across known and novel forgery types. CAL mainly consists of two components: Confidence-Aware Consistency Regularization (CCR) and Asymmetric Confidence Reinforcement (ACR). CCR mitigates pseudo-label bias by dynamically scaling sample losses based on normalized confidence, gradually shifting the training focus from high- to low-confidence samples. ACR complements this by separately calibrating confidence for known and novel classes through selective learning on high-confidence samples, guided by their confidence gap. Together, CCR and ACR form a mutually reinforcing loop that significantly improves the model's OW-DFA performance. Moreover, we introduce a Dynamic Prototype Pruning (DPP) strategy that automatically estimates the number of novel forgery types in a coarse-to-fine manner, removing the need for unrealistic prior assumptions and enhancing the scalability of our methods to real-world OW-DFA scenarios. Extensive experiments on the standard OW-DFA benchmark and a newly extended benchmark incorporating advanced manipulations demonstrate that CAL consistently outperforms previous methods, achieving new state-of-the-art performance on both known and novel forgery attribution.
Beyond Artificial Misalignment: Detecting and Grounding Semantic-Coordinated Multimodal Manipulations
Sep 16, 2025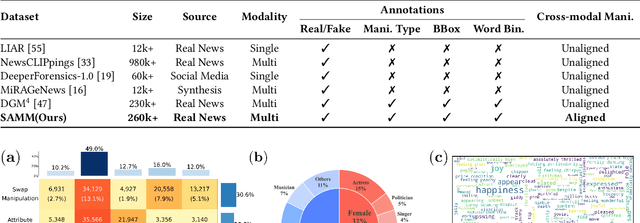
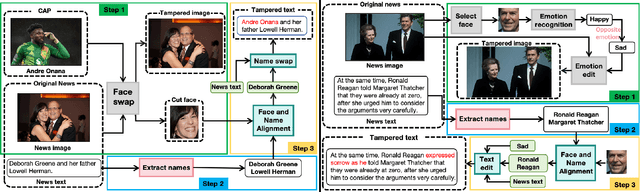
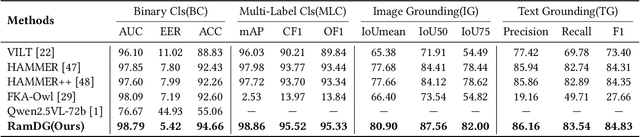
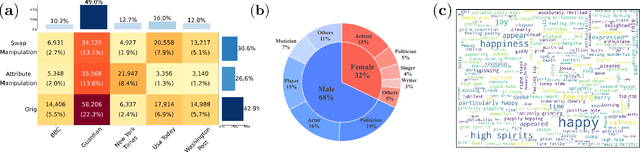
The detection and grounding of manipulated content in multimodal data has emerged as a critical challenge in media forensics. While existing benchmarks demonstrate technical progress, they suffer from misalignment artifacts that poorly reflect real-world manipulation patterns: practical attacks typically maintain semantic consistency across modalities, whereas current datasets artificially disrupt cross-modal alignment, creating easily detectable anomalies. To bridge this gap, we pioneer the detection of semantically-coordinated manipulations where visual edits are systematically paired with semantically consistent textual descriptions. Our approach begins with constructing the first Semantic-Aligned Multimodal Manipulation (SAMM) dataset, generated through a two-stage pipeline: 1) applying state-of-the-art image manipulations, followed by 2) generation of contextually-plausible textual narratives that reinforce the visual deception. Building on this foundation, we propose a Retrieval-Augmented Manipulation Detection and Grounding (RamDG) framework. RamDG commences by harnessing external knowledge repositories to retrieve contextual evidence, which serves as the auxiliary texts and encoded together with the inputs through our image forgery grounding and deep manipulation detection modules to trace all manipulations. Extensive experiments demonstrate our framework significantly outperforms existing methods, achieving 2.06\% higher detection accuracy on SAMM compared to state-of-the-art approaches. The dataset and code are publicly available at https://github.com/shen8424/SAMM-RamDG-CAP.
Prototypical Hash Encoding for On-the-Fly Fine-Grained Category Discovery
Oct 24, 2024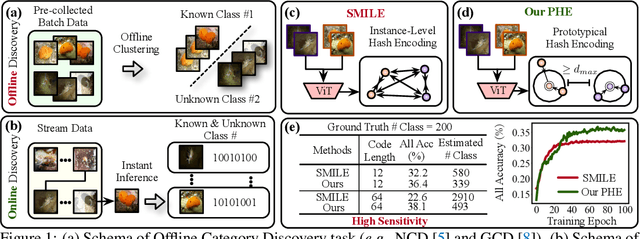

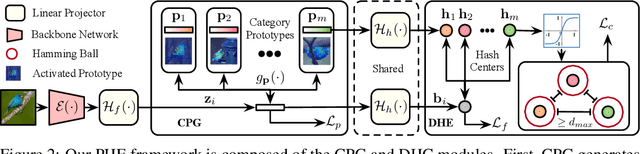
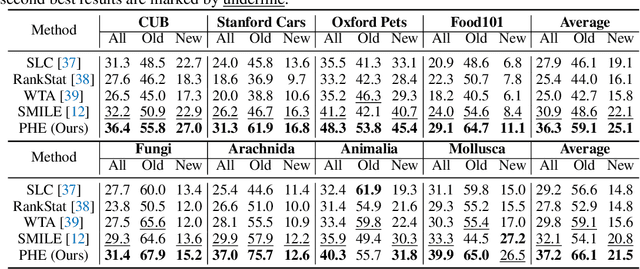
In this paper, we study a practical yet challenging task, On-the-fly Category Discovery (OCD), aiming to online discover the newly-coming stream data that belong to both known and unknown classes, by leveraging only known category knowledge contained in labeled data. Previous OCD methods employ the hash-based technique to represent old/new categories by hash codes for instance-wise inference. However, directly mapping features into low-dimensional hash space not only inevitably damages the ability to distinguish classes and but also causes "high sensitivity" issue, especially for fine-grained classes, leading to inferior performance. To address these issues, we propose a novel Prototypical Hash Encoding (PHE) framework consisting of Category-aware Prototype Generation (CPG) and Discriminative Category Encoding (DCE) to mitigate the sensitivity of hash code while preserving rich discriminative information contained in high-dimension feature space, in a two-stage projection fashion. CPG enables the model to fully capture the intra-category diversity by representing each category with multiple prototypes. DCE boosts the discrimination ability of hash code with the guidance of the generated category prototypes and the constraint of minimum separation distance. By jointly optimizing CPG and DCE, we demonstrate that these two components are mutually beneficial towards an effective OCD. Extensive experiments show the significant superiority of our PHE over previous methods, e.g., obtaining an improvement of +5.3% in ALL ACC averaged on all datasets. Moreover, due to the nature of the interpretable prototypes, we visually analyze the underlying mechanism of how PHE helps group certain samples into either known or unknown categories. Code is available at https://github.com/HaiyangZheng/PHE.
Fire and Smoke Detection with Burning Intensity Representation
Oct 22, 2024



An effective Fire and Smoke Detection (FSD) and analysis system is of paramount importance due to the destructive potential of fire disasters. However, many existing FSD methods directly employ generic object detection techniques without considering the transparency of fire and smoke, which leads to imprecise localization and reduces detection performance. To address this issue, a new Attentive Fire and Smoke Detection Model (a-FSDM) is proposed. This model not only retains the robust feature extraction and fusion capabilities of conventional detection algorithms but also redesigns the detection head specifically for transparent targets in FSD, termed the Attentive Transparency Detection Head (ATDH). In addition, Burning Intensity (BI) is introduced as a pivotal feature for fire-related downstream risk assessments in traditional FSD methodologies. Extensive experiments on multiple FSD datasets showcase the effectiveness and versatility of the proposed FSD model. The project is available at \href{https://xiaoyihan6.github.io/FSD/}{https://xiaoyihan6.github.io/FSD/}.
Benchmarking Multi-Scene Fire and Smoke Detection
Oct 22, 2024The current irregularities in existing public Fire and Smoke Detection (FSD) datasets have become a bottleneck in the advancement of FSD technology. Upon in-depth analysis, we identify the core issue as the lack of standardized dataset construction, uniform evaluation systems, and clear performance benchmarks. To address this issue and drive innovation in FSD technology, we systematically gather diverse resources from public sources to create a more comprehensive and refined FSD benchmark. Additionally, recognizing the inadequate coverage of existing dataset scenes, we strategically expand scenes, relabel, and standardize existing public FSD datasets to ensure accuracy and consistency. We aim to establish a standardized, realistic, unified, and efficient FSD research platform that mirrors real-life scenes closely. Through our efforts, we aim to provide robust support for the breakthrough and development of FSD technology. The project is available at \href{https://xiaoyihan6.github.io/FSD/}{https://xiaoyihan6.github.io/FSD/}.
Discriminative Anchor Learning for Efficient Multi-view Clustering
Sep 25, 2024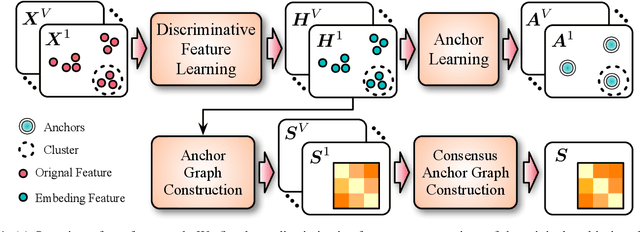
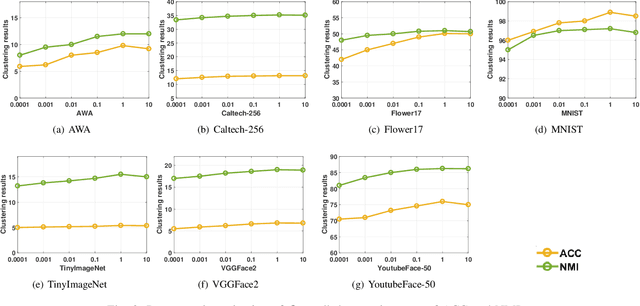
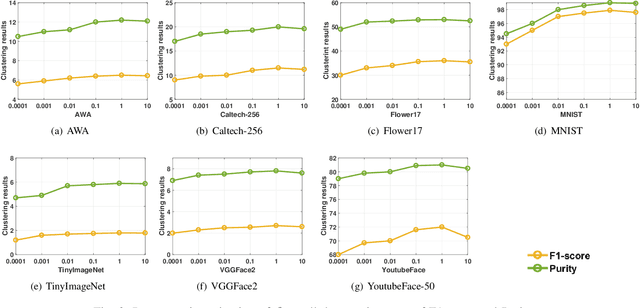
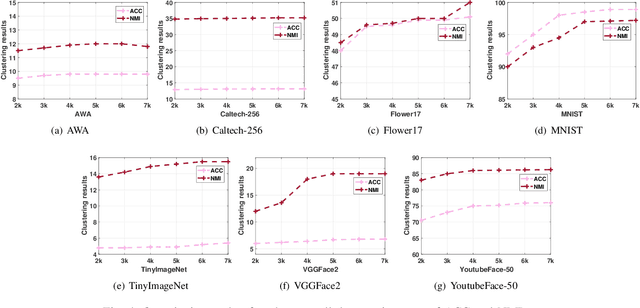
Multi-view clustering aims to study the complementary information across views and discover the underlying structure. For solving the relatively high computational cost for the existing approaches, works based on anchor have been presented recently. Even with acceptable clustering performance, these methods tend to map the original representation from multiple views into a fixed shared graph based on the original dataset. However, most studies ignore the discriminative property of the learned anchors, which ruin the representation capability of the built model. Moreover, the complementary information among anchors across views is neglected to be ensured by simply learning the shared anchor graph without considering the quality of view-specific anchors. In this paper, we propose discriminative anchor learning for multi-view clustering (DALMC) for handling the above issues. We learn discriminative view-specific feature representations according to the original dataset and build anchors from different views based on these representations, which increase the quality of the shared anchor graph. The discriminative feature learning and consensus anchor graph construction are integrated into a unified framework to improve each other for realizing the refinement. The optimal anchors from multiple views and the consensus anchor graph are learned with the orthogonal constraints. We give an iterative algorithm to deal with the formulated problem. Extensive experiments on different datasets show the effectiveness and efficiency of our method compared with other methods.