 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
Dec 14, 2025The proliferation of synthetic facial imagery has intensified the need for robust Open-World DeepFake Attribution (OW-DFA), which aims to attribute both known and unknown forgeries using labeled data for known types and unlabeled data containing a mixture of known and novel types. However, existing OW-DFA methods face two critical limitations: 1) A confidence skew that leads to unreliable pseudo-labels for novel forgeries, resulting in biased training. 2) An unrealistic assumption that the number of unknown forgery types is known *a priori*. To address these challenges, we propose a Confidence-Aware Asymmetric Learning (CAL) framework, which adaptively balances model confidence across known and novel forgery types. CAL mainly consists of two components: Confidence-Aware Consistency Regularization (CCR) and Asymmetric Confidence Reinforcement (ACR). CCR mitigates pseudo-label bias by dynamically scaling sample losses based on normalized confidence, gradually shifting the training focus from high- to low-confidence samples. ACR complements this by separately calibrating confidence for known and novel classes through selective learning on high-confidence samples, guided by their confidence gap. Together, CCR and ACR form a mutually reinforcing loop that significantly improves the model's OW-DFA performance. Moreover, we introduce a Dynamic Prototype Pruning (DPP) strategy that automatically estimates the number of novel forgery types in a coarse-to-fine manner, removing the need for unrealistic prior assumptions and enhancing the scalability of our methods to real-world OW-DFA scenarios. Extensive experiments on the standard OW-DFA benchmark and a newly extended benchmark incorporating advanced manipulations demonstrate that CAL consistently outperforms previous methods, achieving new state-of-the-art performance on both known and novel forgery attribution.
Prototypical Hash Encoding for On-the-Fly Fine-Grained Category Discovery
Oct 24, 2024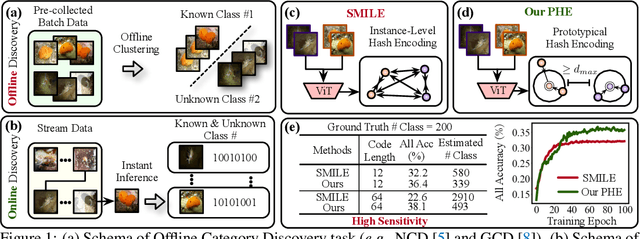

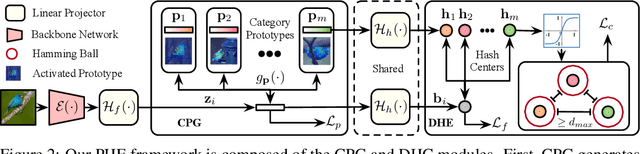
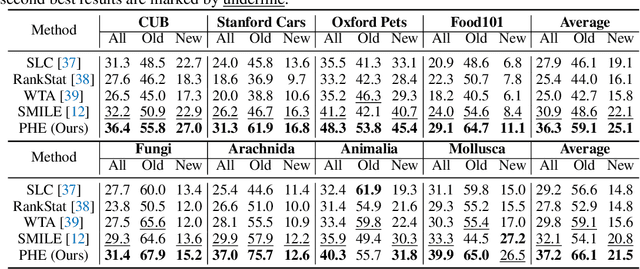
In this paper, we study a practical yet challenging task, On-the-fly Category Discovery (OCD), aiming to online discover the newly-coming stream data that belong to both known and unknown classes, by leveraging only known category knowledge contained in labeled data. Previous OCD methods employ the hash-based technique to represent old/new categories by hash codes for instance-wise inference. However, directly mapping features into low-dimensional hash space not only inevitably damages the ability to distinguish classes and but also causes "high sensitivity" issue, especially for fine-grained classes, leading to inferior performance. To address these issues, we propose a novel Prototypical Hash Encoding (PHE) framework consisting of Category-aware Prototype Generation (CPG) and Discriminative Category Encoding (DCE) to mitigate the sensitivity of hash code while preserving rich discriminative information contained in high-dimension feature space, in a two-stage projection fashion. CPG enables the model to fully capture the intra-category diversity by representing each category with multiple prototypes. DCE boosts the discrimination ability of hash code with the guidance of the generated category prototypes and the constraint of minimum separation distance. By jointly optimizing CPG and DCE, we demonstrate that these two components are mutually beneficial towards an effective OCD. Extensive experiments show the significant superiority of our PHE over previous methods, e.g., obtaining an improvement of +5.3% in ALL ACC averaged on all datasets. Moreover, due to the nature of the interpretable prototypes, we visually analyze the underlying mechanism of how PHE helps group certain samples into either known or unknown categories. Code is available at https://github.com/HaiyangZheng/PHE.
Textual Knowledge Matters: Cross-Modality Co-Teaching for Generalized Visual Class Discovery
Mar 12, 2024In this paper, we study the problem of Generalized Category Discovery (GCD), which aims to cluster unlabeled data from both known and unknown categories using the knowledge of labeled data from known categories. Current GCD methods rely on only visual cues, which however neglect the multi-modality perceptive nature of human cognitive processes in discovering novel visual categories. To address this, we propose a two-phase TextGCD framework to accomplish multi-modality GCD by exploiting powerful Visual-Language Models. TextGCD mainly includes a retrieval-based text generation (RTG) phase and a cross-modality co-teaching (CCT) phase. First, RTG constructs a visual lexicon using category tags from diverse datasets and attributes from Large Language Models, generating descriptive texts for images in a retrieval manner. Second, CCT leverages disparities between textual and visual modalities to foster mutual learning, thereby enhancing visual GCD. In addition, we design an adaptive class aligning strategy to ensure the alignment of category perceptions between modalities as well as a soft-voting mechanism to integrate multi-modality cues. Experiments on eight datasets show the large superiority of our approach over state-of-the-art methods. Notably, our approach outperforms the best competitor, by 7.7% and 10.8% in All accuracy on ImageNet-1k and CUB, respectively.