 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Global-Instance Prompt Tuning for Continual Test-time Adaptation in Medical Image Segmentation
Feb 05, 2026Distribution shift is a common challenge in medical images obtained from different clinical centers, significantly hindering the deployment of pre-trained semantic segmentation models in real-world applications across multiple domains. Continual Test-Time Adaptation(CTTA) has emerged as a promising approach to address cross-domain shifts during continually evolving target domains. Most existing CTTA methods rely on incrementally updating model parameters, which inevitably suffer from error accumulation and catastrophic forgetting, especially in long-term adaptation. Recent prompt-tuning-based works have shown potential to mitigate the two issues above by updating only visual prompts. While these approaches have demonstrated promising performance, several limitations remain:1)lacking multi-scale prompt diversity, 2)inadequate incorporation of instance-specific knowledge, and 3)risk of privacy leakage. To overcome these limitations, we propose Multi-scale Global-Instance Prompt Tuning(MGIPT), to enhance scale diversity of prompts and capture both global- and instance-level knowledge for robust CTTA. Specifically, MGIPT consists of an Adaptive-scale Instance Prompt(AIP) and a Multi-scale Global-level Prompt(MGP). AIP dynamically learns lightweight and instance-specific prompts to mitigate error accumulation with adaptive optimal-scale selection mechanism. MGP captures domain-level knowledge across different scales to ensure robust adaptation with anti-forgetting capabilities. These complementary components are combined through a weighted ensemble approach, enabling effective dual-level adaptation that integrates both global and local information. Extensive experiments on medical image segmentation benchmarks demonstrate that our MGIPT outperforms state-of-the-art methods, achieving robust adaptation across continually changing target domains.
In defense of the two-stage framework for open-set domain adaptive semantic segmentation
Jan 04, 2026Open-Set Domain Adaptation for Semantic Segmentation (OSDA-SS) presents a significant challenge, as it requires both domain adaptation for known classes and the distinction of unknowns. Existing methods attempt to address both tasks within a single unified stage. We question this design, as the annotation imbalance between known and unknown classes often leads to negative transfer of known classes and underfitting for unknowns. To overcome these issues, we propose SATS, a Separating-then-Adapting Training Strategy, which addresses OSDA-SS through two sequential steps: known/unknown separation and unknown-aware domain adaptation. By providing the model with more accurate and well-aligned unknown classes, our method ensures a balanced learning of discriminative features for both known and unknown classes, steering the model toward discovering truly unknown objects. Additionally, we present hard unknown exploration, an innovative data augmentation method that exposes the model to more challenging unknowns, strengthening its ability to capture more comprehensive understanding of target unknowns. We evaluate our method on public OSDA-SS benchmarks. Experimental results demonstrate that our method achieves a substantial advancement, with a +3.85% H-Score improvement for GTA5-to-Cityscapes and +18.64% for SYNTHIA-to-Cityscapes, outperforming previous state-of-the-art methods.
Open-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
Dec 14, 2025The proliferation of synthetic facial imagery has intensified the need for robust Open-World DeepFake Attribution (OW-DFA), which aims to attribute both known and unknown forgeries using labeled data for known types and unlabeled data containing a mixture of known and novel types. However, existing OW-DFA methods face two critical limitations: 1) A confidence skew that leads to unreliable pseudo-labels for novel forgeries, resulting in biased training. 2) An unrealistic assumption that the number of unknown forgery types is known *a priori*. To address these challenges, we propose a Confidence-Aware Asymmetric Learning (CAL) framework, which adaptively balances model confidence across known and novel forgery types. CAL mainly consists of two components: Confidence-Aware Consistency Regularization (CCR) and Asymmetric Confidence Reinforcement (ACR). CCR mitigates pseudo-label bias by dynamically scaling sample losses based on normalized confidence, gradually shifting the training focus from high- to low-confidence samples. ACR complements this by separately calibrating confidence for known and novel classes through selective learning on high-confidence samples, guided by their confidence gap. Together, CCR and ACR form a mutually reinforcing loop that significantly improves the model's OW-DFA performance. Moreover, we introduce a Dynamic Prototype Pruning (DPP) strategy that automatically estimates the number of novel forgery types in a coarse-to-fine manner, removing the need for unrealistic prior assumptions and enhancing the scalability of our methods to real-world OW-DFA scenarios. Extensive experiments on the standard OW-DFA benchmark and a newly extended benchmark incorporating advanced manipulations demonstrate that CAL consistently outperforms previous methods, achieving new state-of-the-art performance on both known and novel forgery attribution.
TDEdit: A Unified Diffusion Framework for Text-Drag Guided Image Manipulation
Sep 26, 2025This paper explores image editing under the joint control of text and drag interactions. While recent advances in text-driven and drag-driven editing have achieved remarkable progress, they suffer from complementary limitations: text-driven methods excel in texture manipulation but lack precise spatial control, whereas drag-driven approaches primarily modify shape and structure without fine-grained texture guidance. To address these limitations, we propose a unified diffusion-based framework for joint drag-text image editing, integrating the strengths of both paradigms. Our framework introduces two key innovations: (1) Point-Cloud Deterministic Drag, which enhances latent-space layout control through 3D feature mapping, and (2) Drag-Text Guided Denoising, dynamically balancing the influence of drag and text conditions during denoising. Notably, our model supports flexible editing modes - operating with text-only, drag-only, or combined conditions - while maintaining strong performance in each setting. Extensive quantitative and qualitative experiments demonstrate that our method not only achieves high-fidelity joint editing but also matches or surpasses the performance of specialized text-only or drag-only approaches, establishing a versatile and generalizable solution for controllable image manipulation. Code will be made publicly available to reproduce all results presented in this work.
Beyond Artificial Misalignment: Detecting and Grounding Semantic-Coordinated Multimodal Manipulations
Sep 16, 2025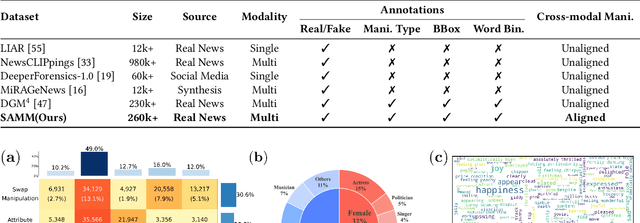
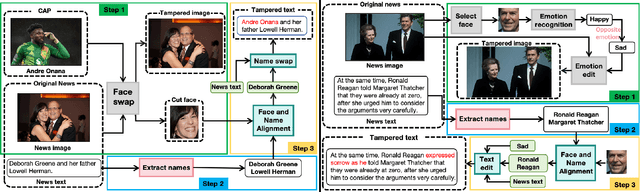
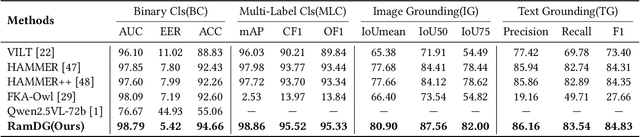
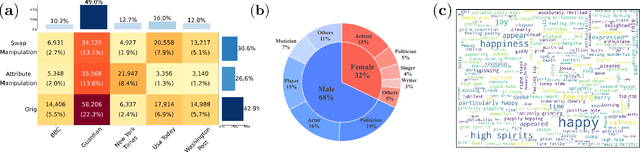
The detection and grounding of manipulated content in multimodal data has emerged as a critical challenge in media forensics. While existing benchmarks demonstrate technical progress, they suffer from misalignment artifacts that poorly reflect real-world manipulation patterns: practical attacks typically maintain semantic consistency across modalities, whereas current datasets artificially disrupt cross-modal alignment, creating easily detectable anomalies. To bridge this gap, we pioneer the detection of semantically-coordinated manipulations where visual edits are systematically paired with semantically consistent textual descriptions. Our approach begins with constructing the first Semantic-Aligned Multimodal Manipulation (SAMM) dataset, generated through a two-stage pipeline: 1) applying state-of-the-art image manipulations, followed by 2) generation of contextually-plausible textual narratives that reinforce the visual deception. Building on this foundation, we propose a Retrieval-Augmented Manipulation Detection and Grounding (RamDG) framework. RamDG commences by harnessing external knowledge repositories to retrieve contextual evidence, which serves as the auxiliary texts and encoded together with the inputs through our image forgery grounding and deep manipulation detection modules to trace all manipulations. Extensive experiments demonstrate our framework significantly outperforms existing methods, achieving 2.06\% higher detection accuracy on SAMM compared to state-of-the-art approaches. The dataset and code are publicly available at https://github.com/shen8424/SAMM-RamDG-CAP.
Towards Fine-Grained Emotion Understanding via Skeleton-Based Micro-Gesture Recognition
Jun 15, 2025We present our solution to the MiGA Challenge at IJCAI 2025, which aims to recognize micro-gestures (MGs) from skeleton sequences for the purpose of hidden emotion understanding. MGs are characterized by their subtlety, short duration, and low motion amplitude, making them particularly challenging to model and classify. We adopt PoseC3D as the baseline framework and introduce three key enhancements: (1) a topology-aware skeleton representation specifically designed for the iMiGUE dataset to better capture fine-grained motion patterns; (2) an improved temporal processing strategy that facilitates smoother and more temporally consistent motion modeling; and (3) the incorporation of semantic label embeddings as auxiliary supervision to improve the model generalization. Our method achieves a Top-1 accuracy of 67.01\% on the iMiGUE test set. As a result of these contributions, our approach ranks third on the official MiGA Challenge leaderboard. The source code is available at \href{https://github.com/EGO-False-Sleep/Miga25_track1}{https://github.com/EGO-False-Sleep/Miga25\_track1}.
Towards Micro-Action Recognition with Limited Annotations: An Asynchronous Pseudo Labeling and Training Approach
Apr 10, 2025Micro-Action Recognition (MAR) aims to classify subtle human actions in video. However, annotating MAR datasets is particularly challenging due to the subtlety of actions. To this end, we introduce the setting of Semi-Supervised MAR (SSMAR), where only a part of samples are labeled. We first evaluate traditional Semi-Supervised Learning (SSL) methods to SSMAR and find that these methods tend to overfit on inaccurate pseudo-labels, leading to error accumulation and degraded performance. This issue primarily arises from the common practice of directly using the predictions of classifier as pseudo-labels to train the model. To solve this issue, we propose a novel framework, called Asynchronous Pseudo Labeling and Training (APLT), which explicitly separates the pseudo-labeling process from model training. Specifically, we introduce a semi-supervised clustering method during the offline pseudo-labeling phase to generate more accurate pseudo-labels. Moreover, a self-adaptive thresholding strategy is proposed to dynamically filter noisy labels of different classes. We then build a memory-based prototype classifier based on the filtered pseudo-labels, which is fixed and used to guide the subsequent model training phase. By alternating the two pseudo-labeling and model training phases in an asynchronous manner, the model can not only be learned with more accurate pseudo-labels but also avoid the overfitting issue. Experiments on three MAR datasets show that our APLT largely outperforms state-of-the-art SSL methods. For instance, APLT improves accuracy by 14.5\% over FixMatch on the MA-12 dataset when using only 50\% labeled data. Code will be publicly available.
ATM-Net: Anatomy-Aware Text-Guided Multi-Modal Fusion for Fine-Grained Lumbar Spine Segmentation
Apr 04, 2025Accurate lumbar spine segmentation is crucial for diagnosing spinal disorders. Existing methods typically use coarse-grained segmentation strategies that lack the fine detail needed for precise diagnosis. Additionally, their reliance on visual-only models hinders the capture of anatomical semantics, leading to misclassified categories and poor segmentation details. To address these limitations, we present ATM-Net, an innovative framework that employs an anatomy-aware, text-guided, multi-modal fusion mechanism for fine-grained segmentation of lumbar substructures, i.e., vertebrae (VBs), intervertebral discs (IDs), and spinal canal (SC). ATM-Net adopts the Anatomy-aware Text Prompt Generator (ATPG) to adaptively convert image annotations into anatomy-aware prompts in different views. These insights are further integrated with image features via the Holistic Anatomy-aware Semantic Fusion (HASF) module, building a comprehensive anatomical context. The Channel-wise Contrastive Anatomy-Aware Enhancement (CCAE) module further enhances class discrimination and refines segmentation through class-wise channel-level multi-modal contrastive learning. Extensive experiments on the MRSpineSeg and SPIDER datasets demonstrate that ATM-Net significantly outperforms state-of-the-art methods, with consistent improvements regarding class discrimination and segmentation details. For example, ATM-Net achieves Dice of 79.39% and HD95 of 9.91 pixels on SPIDER, outperforming the competitive SpineParseNet by 8.31% and 4.14 pixels, respectively.
Noisy Test-Time Adaptation in Vision-Language Models
Feb 20, 2025
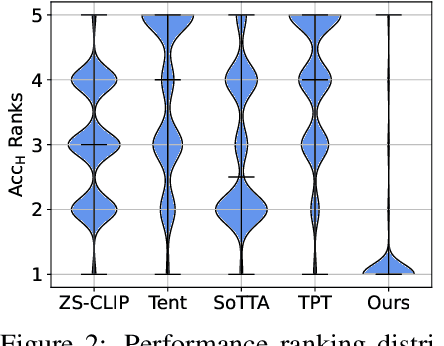
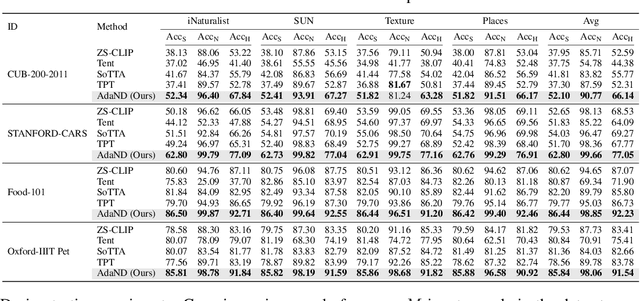
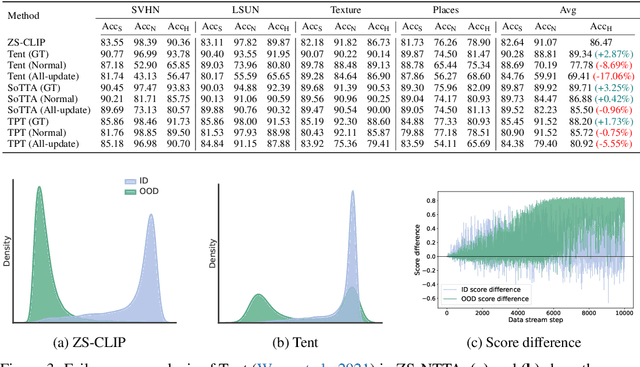
Test-time adaptation (TTA) aims to address distribution shifts between source and target data by relying solely on target data during testing. In open-world scenarios, models often encounter noisy samples, i.e., samples outside the in-distribution (ID) label space. Leveraging the zero-shot capability of pre-trained vision-language models (VLMs), this paper introduces Zero-Shot Noisy TTA (ZS-NTTA), focusing on adapting the model to target data with noisy samples during test-time in a zero-shot manner. We find existing TTA methods underperform under ZS-NTTA, often lagging behind even the frozen model. We conduct comprehensive experiments to analyze this phenomenon, revealing that the negative impact of unfiltered noisy data outweighs the benefits of clean data during model updating. Also, adapting a classifier for ID classification and noise detection hampers both sub-tasks. Built on this, we propose a framework that decouples the classifier and detector, focusing on developing an individual detector while keeping the classifier frozen. Technically, we introduce the Adaptive Noise Detector (AdaND), which utilizes the frozen model's outputs as pseudo-labels to train a noise detector. To handle clean data streams, we further inject Gaussian noise during adaptation, preventing the detector from misclassifying clean samples as noisy. Beyond the ZS-NTTA, AdaND can also improve the zero-shot out-of-distribution (ZS-OOD) detection ability of VLMs. Experiments show that AdaND outperforms in both ZS-NTTA and ZS-OOD detection. On ImageNet, AdaND achieves a notable improvement of $8.32\%$ in harmonic mean accuracy ($\text{Acc}_\text{H}$) for ZS-NTTA and $9.40\%$ in FPR95 for ZS-OOD detection, compared to SOTA methods. Importantly, AdaND is computationally efficient and comparable to the model-frozen method. The code is publicly available at: https://github.com/tmlr-group/ZS-NTTA.
Prior-Constrained Association Learning for Fine-Grained Generalized Category Discovery
Feb 13, 2025



This paper addresses generalized category discovery (GCD), the task of clustering unlabeled data from potentially known or unknown categories with the help of labeled instances from each known category. Compared to traditional semi-supervised learning, GCD is more challenging because unlabeled data could be from novel categories not appearing in labeled data. Current state-of-the-art methods typically learn a parametric classifier assisted by self-distillation. While being effective, these methods do not make use of cross-instance similarity to discover class-specific semantics which are essential for representation learning and category discovery. In this paper, we revisit the association-based paradigm and propose a Prior-constrained Association Learning method to capture and learn the semantic relations within data. In particular, the labeled data from known categories provides a unique prior for the association of unlabeled data. Unlike previous methods that only adopts the prior as a pre or post-clustering refinement, we fully incorporate the prior into the association process, and let it constrain the association towards a reliable grouping outcome. The estimated semantic groups are utilized through non-parametric prototypical contrast to enhance the representation learning. A further combination of both parametric and non-parametric classification complements each other and leads to a model that outperforms existing methods by a significant margin. On multiple GCD benchmarks, we perform extensive experiments and validate the effectiveness of our proposed method.