 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLRS-Bench: A Vision-Language Reasoning Benchmark for Remote Sensing
Feb 04, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have enabled complex reasoning. However, existing remote sensing (RS) benchmarks remain heavily biased toward perception tasks, such as object recognition and scene classification. This limitation hinders the development of MLLMs for cognitively demanding RS applications. To address this, , we propose a Vision Language ReaSoning Benchmark (VLRS-Bench), which is the first benchmark exclusively dedicated to complex RS reasoning. Structured across the three core dimensions of Cognition, Decision, and Prediction, VLRS-Bench comprises 2,000 question-answer pairs with an average length of 71 words, spanning 14 tasks and up to eight temporal phases. VLRS-Bench is constructed via a specialized pipeline that integrates RS-specific priors and expert knowledge to ensure geospatial realism and reasoning complexity. Experimental results reveal significant bottlenecks in existing state-of-the-art MLLMs, providing critical insights for advancing multimodal reasoning within the remote sensing community.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
HCCM: Hierarchical Cross-Granularity Contrastive and Matching Learning for Natural Language-Guided Drones
Aug 29, 2025Natural Language-Guided Drones (NLGD) provide a novel paradigm for tasks such as target matching and navigation. However, the wide field of view and complex compositional semantics in drone scenarios pose challenges for vision-language understanding. Mainstream Vision-Language Models (VLMs) emphasize global alignment while lacking fine-grained semantics, and existing hierarchical methods depend on precise entity partitioning and strict containment, limiting effectiveness in dynamic environments. To address this, we propose the Hierarchical Cross-Granularity Contrastive and Matching learning (HCCM) framework with two components: (1) Region-Global Image-Text Contrastive Learning (RG-ITC), which avoids precise scene partitioning and captures hierarchical local-to-global semantics by contrasting local visual regions with global text and vice versa; (2) Region-Global Image-Text Matching (RG-ITM), which dispenses with rigid constraints and instead evaluates local semantic consistency within global cross-modal representations, enhancing compositional reasoning. Moreover, drone text descriptions are often incomplete or ambiguous, destabilizing alignment. HCCM introduces a Momentum Contrast and Distillation (MCD) mechanism to improve robustness. Experiments on GeoText-1652 show HCCM achieves state-of-the-art Recall@1 of 28.8% (image retrieval) and 14.7% (text retrieval). On the unseen ERA dataset, HCCM demonstrates strong zero-shot generalization with 39.93% mean recall (mR), outperforming fine-tuned baselines.
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts
Jun 18, 2025The advent of Large Vision Models (LVMs) offers new opportunities for few-shot medical image segmentation. However, existing training-free methods based on LVMs fail to effectively utilize negative prompts, leading to poor performance on low-contrast medical images. To address this issue, we propose SynPo, a training-free few-shot method based on LVMs (e.g., SAM), with the core insight: improving the quality of negative prompts. To select point prompts in a more reliable confidence map, we design a novel Confidence Map Synergy Module by combining the strengths of DINOv2 and SAM. Based on the confidence map, we select the top-k pixels as the positive points set and choose the negative points set using a Gaussian distribution, followed by independent K-means clustering for both sets. Then, these selected points are leveraged as high-quality prompts for SAM to get the segmentation results. Extensive experiments demonstrate that SynPo achieves performance comparable to state-of-the-art training-based few-shot methods.
ATM-Net: Anatomy-Aware Text-Guided Multi-Modal Fusion for Fine-Grained Lumbar Spine Segmentation
Apr 04, 2025Accurate lumbar spine segmentation is crucial for diagnosing spinal disorders. Existing methods typically use coarse-grained segmentation strategies that lack the fine detail needed for precise diagnosis. Additionally, their reliance on visual-only models hinders the capture of anatomical semantics, leading to misclassified categories and poor segmentation details. To address these limitations, we present ATM-Net, an innovative framework that employs an anatomy-aware, text-guided, multi-modal fusion mechanism for fine-grained segmentation of lumbar substructures, i.e., vertebrae (VBs), intervertebral discs (IDs), and spinal canal (SC). ATM-Net adopts the Anatomy-aware Text Prompt Generator (ATPG) to adaptively convert image annotations into anatomy-aware prompts in different views. These insights are further integrated with image features via the Holistic Anatomy-aware Semantic Fusion (HASF) module, building a comprehensive anatomical context. The Channel-wise Contrastive Anatomy-Aware Enhancement (CCAE) module further enhances class discrimination and refines segmentation through class-wise channel-level multi-modal contrastive learning. Extensive experiments on the MRSpineSeg and SPIDER datasets demonstrate that ATM-Net significantly outperforms state-of-the-art methods, with consistent improvements regarding class discrimination and segmentation details. For example, ATM-Net achieves Dice of 79.39% and HD95 of 9.91 pixels on SPIDER, outperforming the competitive SpineParseNet by 8.31% and 4.14 pixels, respectively.
Detect Changes like Humans: Incorporating Semantic Priors for Improved Change Detection
Dec 22, 2024



When given two similar images, humans identify their differences by comparing the appearance ({\it e.g., color, texture}) with the help of semantics ({\it e.g., objects, relations}). However, mainstream change detection models adopt a supervised training paradigm, where the annotated binary change map is the main constraint. Thus, these methods primarily emphasize the difference-aware features between bi-temporal images and neglect the semantic understanding of the changed landscapes, which undermines the accuracy in the presence of noise and illumination variations. To this end, this paper explores incorporating semantic priors to improve the ability to detect changes. Firstly, we propose a Semantic-Aware Change Detection network, namely SA-CDNet, which transfers the common knowledge of the visual foundation models ({\it i.e., FastSAM}) to change detection. Inspired by the human visual paradigm, a novel dual-stream feature decoder is derived to distinguish changes by combining semantic-aware features and difference-aware features. Secondly, we design a single-temporal semantic pre-training strategy to enhance the semantic understanding of landscapes, which brings further increments. Specifically, we construct pseudo-change detection data from public single-temporal remote sensing segmentation datasets for large-scale pre-training, where an extra branch is also introduced for the proxy semantic segmentation task. Experimental results on five challenging benchmarks demonstrate the superiority of our method over the existing state-of-the-art methods. The code is available at \href{https://github.com/thislzm/SA-CD}{SA-CD}.
Weakly Supervised Object Detection for Automatic Tooth-marked Tongue Recognition
Aug 29, 2024Tongue diagnosis in Traditional Chinese Medicine (TCM) is a crucial diagnostic method that can reflect an individual's health status. Traditional methods for identifying tooth-marked tongues are subjective and inconsistent because they rely on practitioner experience. We propose a novel fully automated Weakly Supervised method using Vision transformer and Multiple instance learning WSVM for tongue extraction and tooth-marked tongue recognition. Our approach first accurately detects and extracts the tongue region from clinical images, removing any irrelevant background information. Then, we implement an end-to-end weakly supervised object detection method. We utilize Vision Transformer (ViT) to process tongue images in patches and employ multiple instance loss to identify tooth-marked regions with only image-level annotations. WSVM achieves high accuracy in tooth-marked tongue classification, and visualization experiments demonstrate its effectiveness in pinpointing these regions. This automated approach enhances the objectivity and accuracy of tooth-marked tongue diagnosis. It provides significant clinical value by assisting TCM practitioners in making precise diagnoses and treatment recommendations. Code is available at https://github.com/yc-zh/WSVM.
Long-Tailed Out-of-Distribution Detection: Prioritizing Attention to Tail
Aug 13, 2024



Current out-of-distribution (OOD) detection methods typically assume balanced in-distribution (ID) data, while most real-world data follow a long-tailed distribution. Previous approaches to long-tailed OOD detection often involve balancing the ID data by reducing the semantics of head classes. However, this reduction can severely affect the classification accuracy of ID data. The main challenge of this task lies in the severe lack of features for tail classes, leading to confusion with OOD data. To tackle this issue, we introduce a novel Prioritizing Attention to Tail (PATT) method using augmentation instead of reduction. Our main intuition involves using a mixture of von Mises-Fisher (vMF) distributions to model the ID data and a temperature scaling module to boost the confidence of ID data. This enables us to generate infinite contrastive pairs, implicitly enhancing the semantics of ID classes while promoting differentiation between ID and OOD data. To further strengthen the detection of OOD data without compromising the classification performance of ID data, we propose feature calibration during the inference phase. By extracting an attention weight from the training set that prioritizes the tail classes and reduces the confidence in OOD data, we improve the OOD detection capability. Extensive experiments verified that our method outperforms the current state-of-the-art methods on various benchmarks.
Towards Adversarial Robustness via Debiased High-Confidence Logit Alignment
Aug 12, 2024



Despite the significant advances that deep neural networks (DNNs) have achieved in various visual tasks, they still exhibit vulnerability to adversarial examples, leading to serious security concerns. Recent adversarial training techniques have utilized inverse adversarial attacks to generate high-confidence examples, aiming to align the distributions of adversarial examples with the high-confidence regions of their corresponding classes. However, in this paper, our investigation reveals that high-confidence outputs under inverse adversarial attacks are correlated with biased feature activation. Specifically, training with inverse adversarial examples causes the model's attention to shift towards background features, introducing a spurious correlation bias. To address this bias, we propose Debiased High-Confidence Adversarial Training (DHAT), a novel approach that not only aligns the logits of adversarial examples with debiased high-confidence logits obtained from inverse adversarial examples, but also restores the model's attention to its normal state by enhancing foreground logit orthogonality. Extensive experiments demonstrate that DHAT achieves state-of-the-art performance and exhibits robust generalization capabilities across various vision datasets. Additionally, DHAT can seamlessly integrate with existing advanced adversarial training techniques for improving the performance.
Mitigating Low-Frequency Bias: Feature Recalibration and Frequency Attention Regularization for Adversarial Robustness
Jul 04, 2024


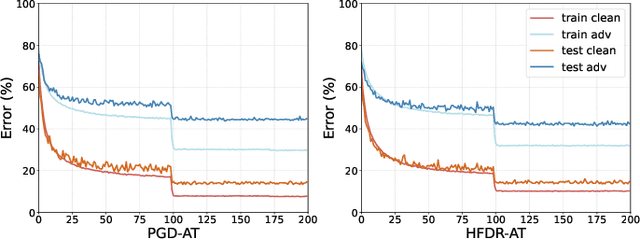
Ensuring the robustness of computer vision models against adversarial attacks is a significant and long-lasting objective. Motivated by adversarial attacks, researchers have devoted considerable efforts to enhancing model robustness by adversarial training (AT). However, we observe that while AT improves the models' robustness against adversarial perturbations, it fails to improve their ability to effectively extract features across all frequency components. Each frequency component contains distinct types of crucial information: low-frequency features provide fundamental structural insights, while high-frequency features capture intricate details and textures. In particular, AT tends to neglect the reliance on susceptible high-frequency features. This low-frequency bias impedes the model's ability to effectively leverage the potentially meaningful semantic information present in high-frequency features. This paper proposes a novel module called High-Frequency Feature Disentanglement and Recalibration (HFDR), which separates features into high-frequency and low-frequency components and recalibrates the high-frequency feature to capture latent useful semantics. Additionally, we introduce frequency attention regularization to magnitude the model's extraction of different frequency features and mitigate low-frequency bias during AT. Extensive experiments showcase the immense potential and superiority of our approach in resisting various white-box attacks, transfer attacks, and showcasing strong generalization capabilities.