 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt PointFormer: 3D Point Cloud Analysis via Adapting 2D Visual Transformers
Jul 18, 2024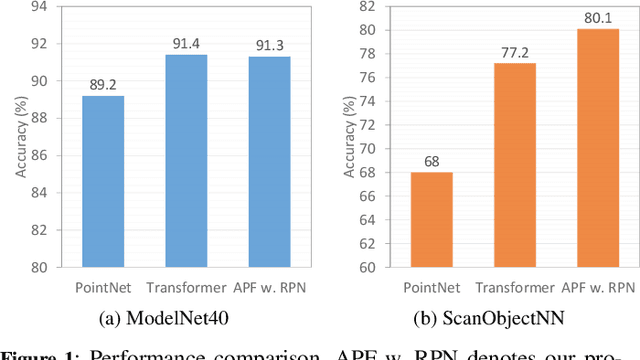
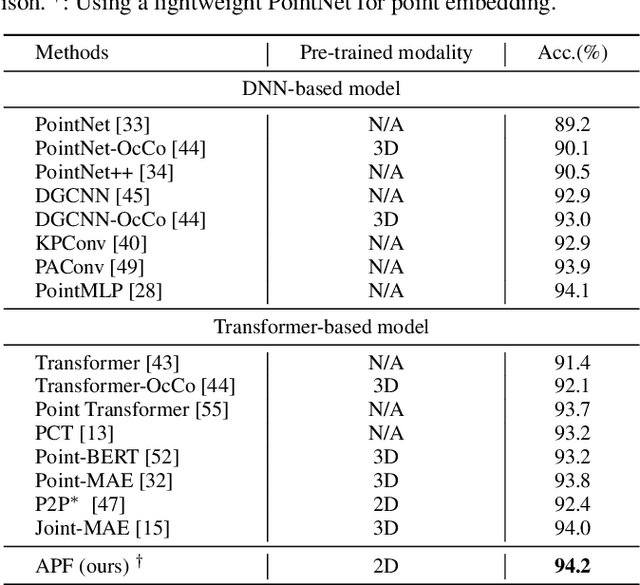
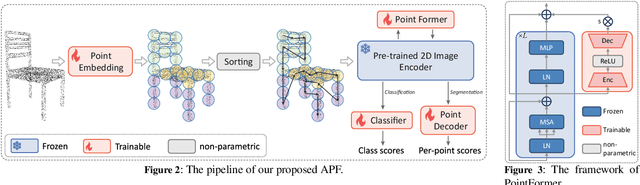
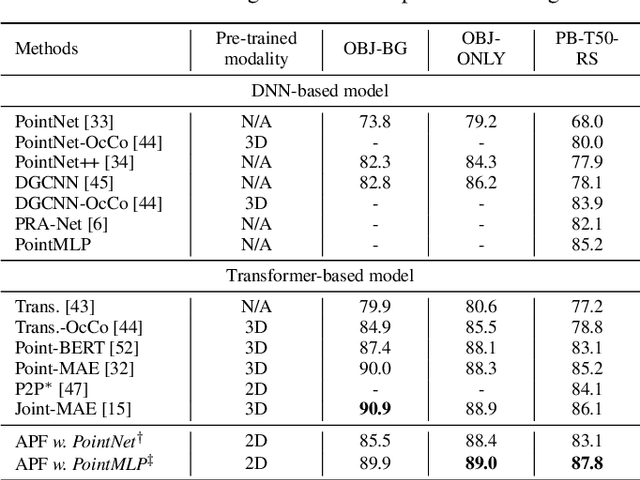
Pre-trained large-scale models have exhibited remarkable efficacy in computer vision, particularly for 2D image analysis. However, when it comes to 3D point clouds, the constrained accessibility of data, in contrast to the vast repositories of images, poses a challenge for the development of 3D pre-trained models. This paper therefore attempts to directly leverage pre-trained models with 2D prior knowledge to accomplish the tasks for 3D point cloud analysis. Accordingly, we propose the Adaptive PointFormer (APF), which fine-tunes pre-trained 2D models with only a modest number of parameters to directly process point clouds, obviating the need for mapping to images. Specifically, we convert raw point clouds into point embeddings for aligning dimensions with image tokens. Given the inherent disorder in point clouds, in contrast to the structured nature of images, we then sequence the point embeddings to optimize the utilization of 2D attention priors. To calibrate attention across 3D and 2D domains and reduce computational overhead, a trainable PointFormer with a limited number of parameters is subsequently concatenated to a frozen pre-trained image model. Extensive experiments on various benchmarks demonstrate the effectiveness of the proposed APF. The source code and more details are available at https://vcc.tech/research/2024/PointFormer.
Harmonizing Feature Maps: A Graph Convolutional Approach for Enhancing Adversarial Robustness
Jun 17, 2024



The vulnerability of Deep Neural Networks to adversarial perturbations presents significant security concerns, as the imperceptible perturbations can contaminate the feature space and lead to incorrect predictions. Recent studies have attempted to calibrate contaminated features by either suppressing or over-activating particular channels. Despite these efforts, we claim that adversarial attacks exhibit varying disruption levels across individual channels. Furthermore, we argue that harmonizing feature maps via graph and employing graph convolution can calibrate contaminated features. To this end, we introduce an innovative plug-and-play module called Feature Map-based Reconstructed Graph Convolution (FMR-GC). FMR-GC harmonizes feature maps in the channel dimension to reconstruct the graph, then employs graph convolution to capture neighborhood information, effectively calibrating contaminated features. Extensive experiments have demonstrated the superior performance and scalability of FMR-GC. Moreover, our model can be combined with advanced adversarial training methods to considerably enhance robustness without compromising the model's clean accuracy.
A Multilevel Guidance-Exploration Network and Behavior-Scene Matching Method for Human Behavior Anomaly Detection
Dec 07, 2023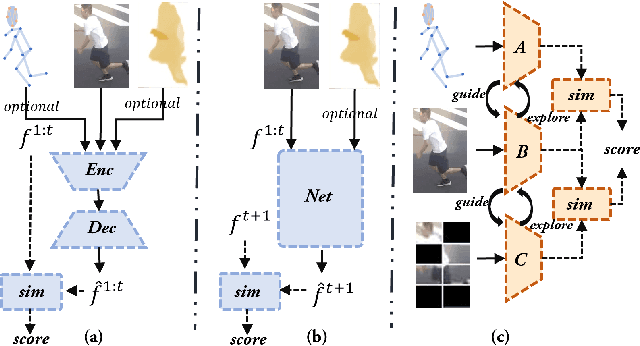
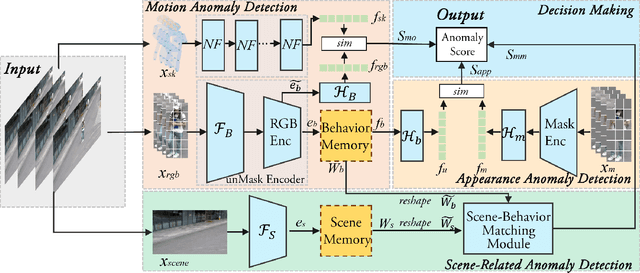
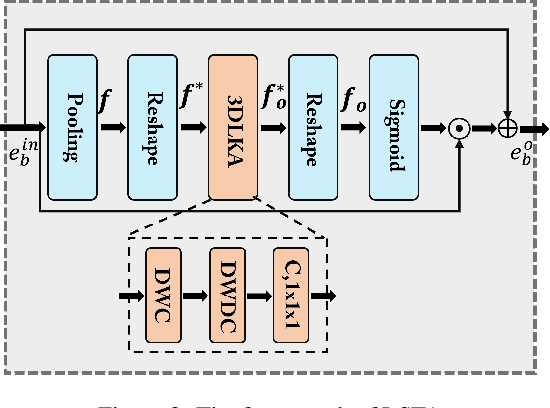
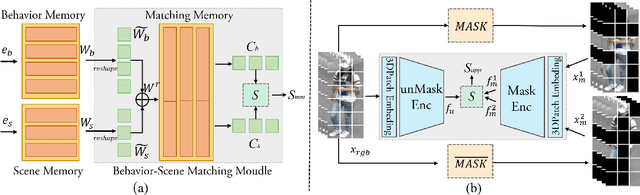
Human behavior anomaly detection aims to identify unusual human actions, playing a crucial role in intelligent surveillance and other areas. The current mainstream methods still adopt reconstruction or future frame prediction techniques. However, reconstructing or predicting low-level pixel features easily enables the network to achieve overly strong generalization ability, allowing anomalies to be reconstructed or predicted as effectively as normal data. Different from their methods, inspired by the Student-Teacher Network, we propose a novel framework called the Multilevel Guidance-Exploration Network(MGENet), which detects anomalies through the difference in high-level representation between the Guidance and Exploration network. Specifically, we first utilize the pre-trained Normalizing Flow that takes skeletal keypoints as input to guide an RGB encoder, which takes unmasked RGB frames as input, to explore motion latent features. Then, the RGB encoder guides the mask encoder, which takes masked RGB frames as input, to explore the latent appearance feature. Additionally, we design a Behavior-Scene Matching Module(BSMM) to detect scene-related behavioral anomalies. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on ShanghaiTech and UBnormal datasets, with AUC of 86.9 % and 73.5 %, respectively. The code will be available on https://github.com/molu-ggg/GENet.
A Self-Training Framework Based on Multi-Scale Attention Fusion for Weakly Supervised Semantic Segmentation
May 10, 2023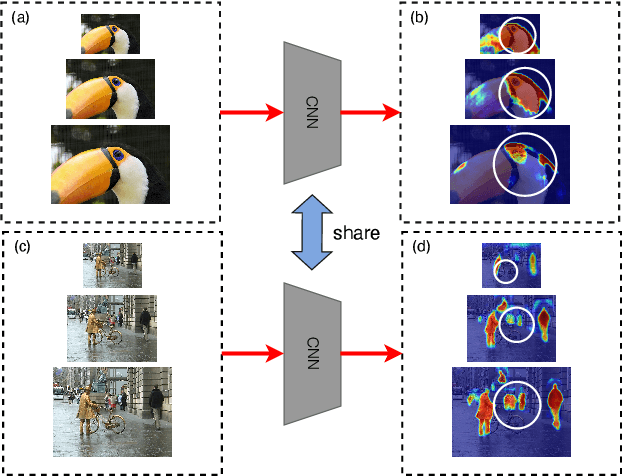
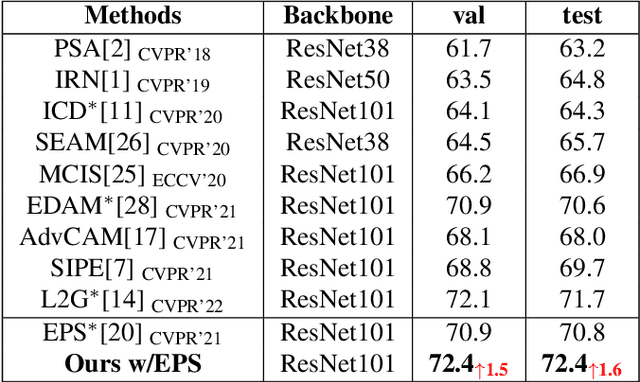
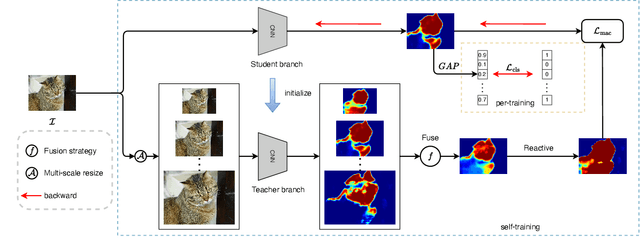
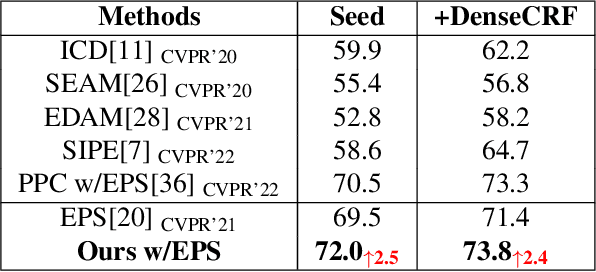
Weakly supervised semantic segmentation (WSSS) based on image-level labels is challenging since it is hard to obtain complete semantic regions. To address this issue, we propose a self-training method that utilizes fused multi-scale class-aware attention maps. Our observation is that attention maps of different scales contain rich complementary information, especially for large and small objects. Therefore, we collect information from attention maps of different scales and obtain multi-scale attention maps. We then apply denoising and reactivation strategies to enhance the potential regions and reduce noisy areas. Finally, we use the refined attention maps to retrain the network. Experiments showthat our method enables the model to extract rich semantic information from multi-scale images and achieves 72.4% mIou scores on both the PASCAL VOC 2012 validation and test sets. The code is available at https://bupt-ai-cz.github.io/SMAF.
UrbanBIS: a Large-scale Benchmark for Fine-grained Urban Building Instance Segmentation
May 04, 2023



We present the UrbanBIS benchmark for large-scale 3D urban understanding, supporting practical urban-level semantic and building-level instance segmentation. UrbanBIS comprises six real urban scenes, with 2.5 billion points, covering a vast area of 10.78 square kilometers and 3,370 buildings, captured by 113,346 views of aerial photogrammetry. Particularly, UrbanBIS provides not only semantic-level annotations on a rich set of urban objects, including buildings, vehicles, vegetation, roads, and bridges, but also instance-level annotations on the buildings. Further, UrbanBIS is the first 3D dataset that introduces fine-grained building sub-categories, considering a wide variety of shapes for different building types. Besides, we propose B-Seg, a building instance segmentation method to establish UrbanBIS. B-Seg adopts an end-to-end framework with a simple yet effective strategy for handling large-scale point clouds. Compared with mainstream methods, B-Seg achieves better accuracy with faster inference speed on UrbanBIS. In addition to the carefully-annotated point clouds, UrbanBIS provides high-resolution aerial-acquisition photos and high-quality large-scale 3D reconstruction models, which shall facilitate a wide range of studies such as multi-view stereo, urban LOD generation, aerial path planning, autonomous navigation, road network extraction, and so on, thus serving as an important platform for many intelligent city applications.
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022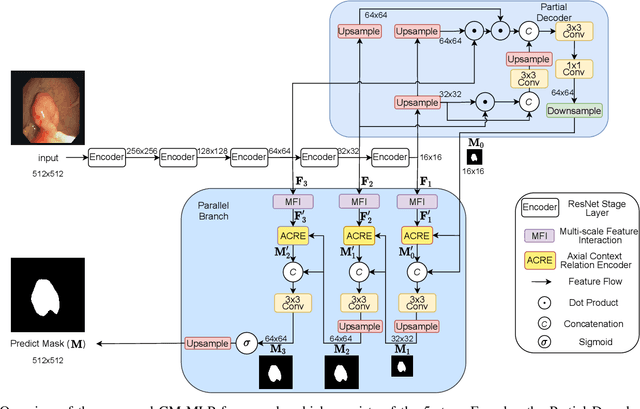
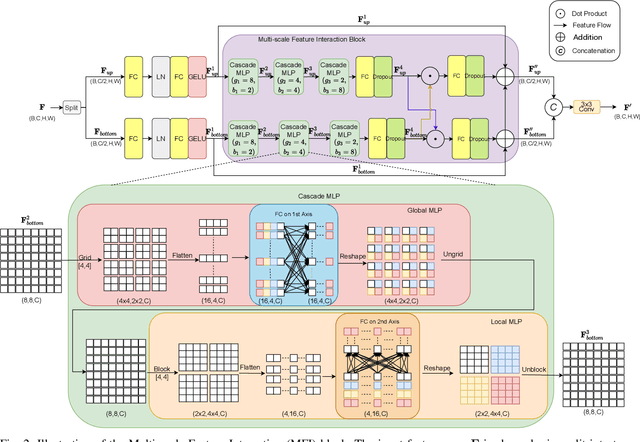
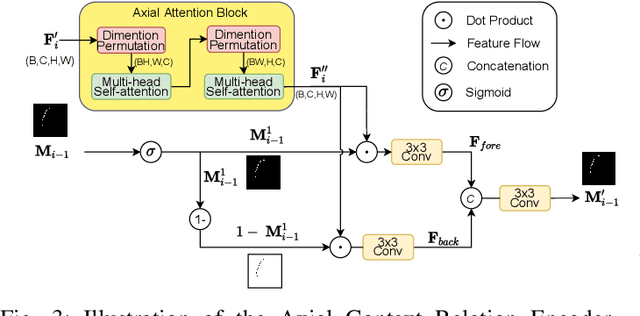
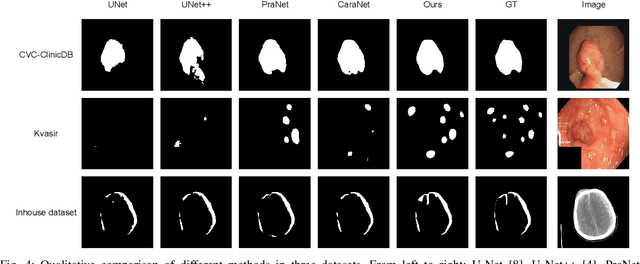
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.
PBRnet: Pyramidal Bounding Box Refinement to Improve Object Localization Accuracy
Mar 10, 2020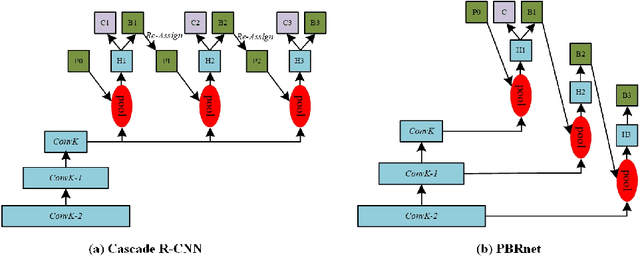

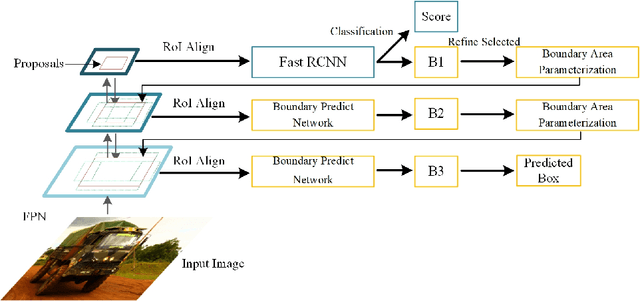

Many recently developed object detectors focused on coarse-to-fine framework which contains several stages that classify and regress proposals from coarse-grain to fine-grain, and obtains more accurate detection gradually. Multi-resolution models such as Feature Pyramid Network(FPN) integrate information of different levels of resolution and effectively improve the performance. Previous researches also have revealed that localization can be further improved by: 1) using fine-grained information which is more translational variant; 2) refining local areas which is more focused on local boundary information. Based on these principles, we designed a novel boundary refinement architecture to improve localization accuracy by combining coarse-to-fine framework with feature pyramid structure, named as Pyramidal Bounding Box Refinement network(PBRnet), which parameterizes gradually focused boundary areas of objects and leverages lower-level feature maps to extract finer local information when refining the predicted bounding boxes. Extensive experiments are performed on the MS-COCO dataset. The PBRnet brings a significant performance gains by roughly 3 point of $mAP$ when added to FPN or Libra R-CNN. Moreover, by treating Cascade R-CNN as a coarse-to-fine detector and replacing its localization branch by the regressor of PBRnet, it leads an extra performance improvement by 1.5 $mAP$, yielding a total performance boosting by as high as 5 point of $mAP$.