 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Path Planning for Urban Geometry and Texture Co-Capture
Sep 26, 2025Recent advances in image acquisition and scene reconstruction have enabled the generation of high-quality structural urban scene geometry, given sufficient site information. However, current capture techniques often overlook the crucial importance of texture quality, resulting in noticeable visual artifacts in the textured models. In this work, we introduce the urban geometry and texture co-capture problem under limited prior knowledge before a site visit. The only inputs are a 2D building contour map of the target area and a safe flying altitude above the buildings. We propose an innovative aerial path planning framework designed to co-capture images for reconstructing both structured geometry and high-fidelity textures. To evaluate and guide view planning, we introduce a comprehensive texture quality assessment system, including two novel metrics tailored for building facades. Firstly, our method generates high-quality vertical dipping views and horizontal planar views to effectively capture both geometric and textural details. A multi-objective optimization strategy is then proposed to jointly maximize texture fidelity, improve geometric accuracy, and minimize the cost associated with aerial views. Furthermore, we present a sequential path planning algorithm that accounts for texture consistency during image capture. Extensive experiments on large-scale synthetic and real-world urban datasets demonstrate that our approach effectively produces image sets suitable for concurrent geometric and texture reconstruction, enabling the creation of realistic, textured scene proxies at low operational cost.
Aerial Path Online Planning for Urban Scene Updation
May 02, 2025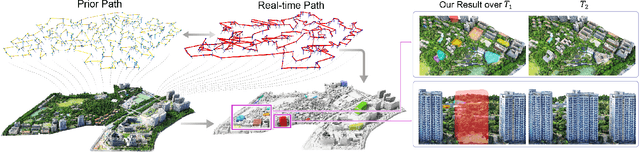



We present the first scene-update aerial path planning algorithm specifically designed for detecting and updating change areas in urban environments. While existing methods for large-scale 3D urban scene reconstruction focus on achieving high accuracy and completeness, they are inefficient for scenarios requiring periodic updates, as they often re-explore and reconstruct entire scenes, wasting significant time and resources on unchanged areas. To address this limitation, our method leverages prior reconstructions and change probability statistics to guide UAVs in detecting and focusing on areas likely to have changed. Our approach introduces a novel changeability heuristic to evaluate the likelihood of changes, driving the planning of two flight paths: a prior path informed by static priors and a dynamic real-time path that adapts to newly detected changes. The framework integrates surface sampling and candidate view generation strategies, ensuring efficient coverage of change areas with minimal redundancy. Extensive experiments on real-world urban datasets demonstrate that our method significantly reduces flight time and computational overhead, while maintaining high-quality updates comparable to full-scene re-exploration and reconstruction. These contributions pave the way for efficient, scalable, and adaptive UAV-based scene updates in complex urban environments.
UrbanBIS: a Large-scale Benchmark for Fine-grained Urban Building Instance Segmentation
May 04, 2023



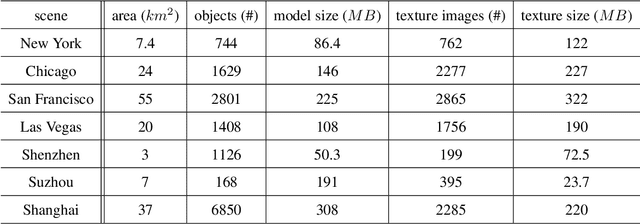
We present the UrbanBIS benchmark for large-scale 3D urban understanding, supporting practical urban-level semantic and building-level instance segmentation. UrbanBIS comprises six real urban scenes, with 2.5 billion points, covering a vast area of 10.78 square kilometers and 3,370 buildings, captured by 113,346 views of aerial photogrammetry. Particularly, UrbanBIS provides not only semantic-level annotations on a rich set of urban objects, including buildings, vehicles, vegetation, roads, and bridges, but also instance-level annotations on the buildings. Further, UrbanBIS is the first 3D dataset that introduces fine-grained building sub-categories, considering a wide variety of shapes for different building types. Besides, we propose B-Seg, a building instance segmentation method to establish UrbanBIS. B-Seg adopts an end-to-end framework with a simple yet effective strategy for handling large-scale point clouds. Compared with mainstream methods, B-Seg achieves better accuracy with faster inference speed on UrbanBIS. In addition to the carefully-annotated point clouds, UrbanBIS provides high-resolution aerial-acquisition photos and high-quality large-scale 3D reconstruction models, which shall facilitate a wide range of studies such as multi-view stereo, urban LOD generation, aerial path planning, autonomous navigation, road network extraction, and so on, thus serving as an important platform for many intelligent city applications.
Learning Reconstructability for Drone Aerial Path Planning
Sep 21, 2022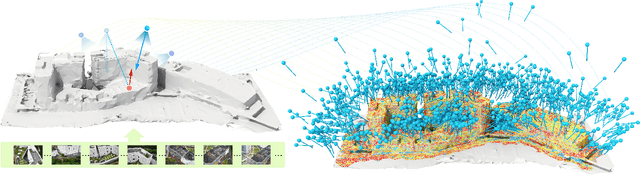
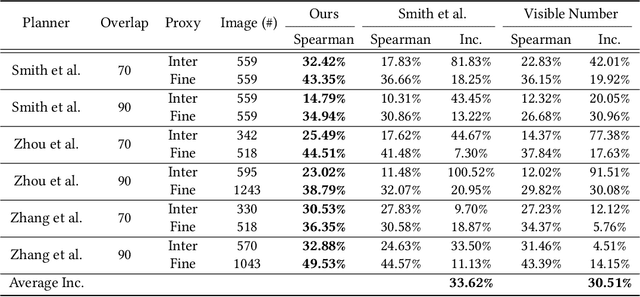
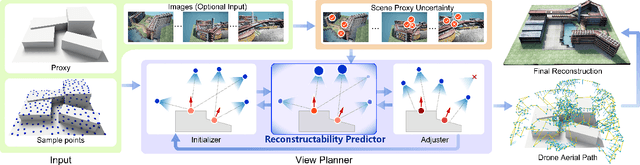
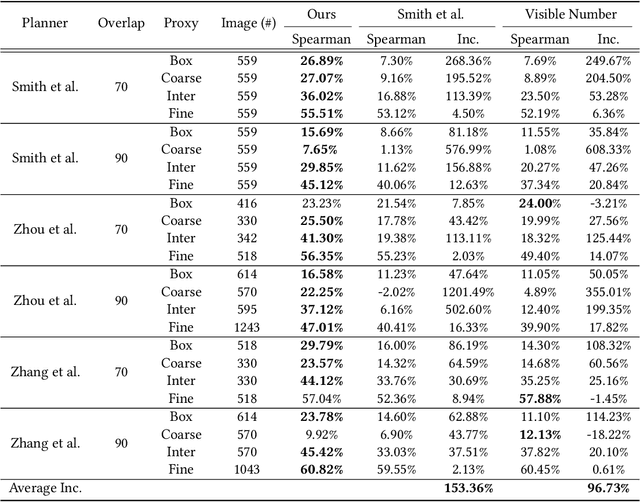
We introduce the first learning-based reconstructability predictor to improve view and path planning for large-scale 3D urban scene acquisition using unmanned drones. In contrast to previous heuristic approaches, our method learns a model that explicitly predicts how well a 3D urban scene will be reconstructed from a set of viewpoints. To make such a model trainable and simultaneously applicable to drone path planning, we simulate the proxy-based 3D scene reconstruction during training to set up the prediction. Specifically, the neural network we design is trained to predict the scene reconstructability as a function of the proxy geometry, a set of viewpoints, and optionally a series of scene images acquired in flight. To reconstruct a new urban scene, we first build the 3D scene proxy, then rely on the predicted reconstruction quality and uncertainty measures by our network, based off of the proxy geometry, to guide the drone path planning. We demonstrate that our data-driven reconstructability predictions are more closely correlated to the true reconstruction quality than prior heuristic measures. Further, our learned predictor can be easily integrated into existing path planners to yield improvements. Finally, we devise a new iterative view planning framework, based on the learned reconstructability, and show superior performance of the new planner when reconstructing both synthetic and real scenes.
VGF-Net: Visual-Geometric Fusion Learning for Simultaneous Drone Navigation and Height Mapping
Apr 07, 2021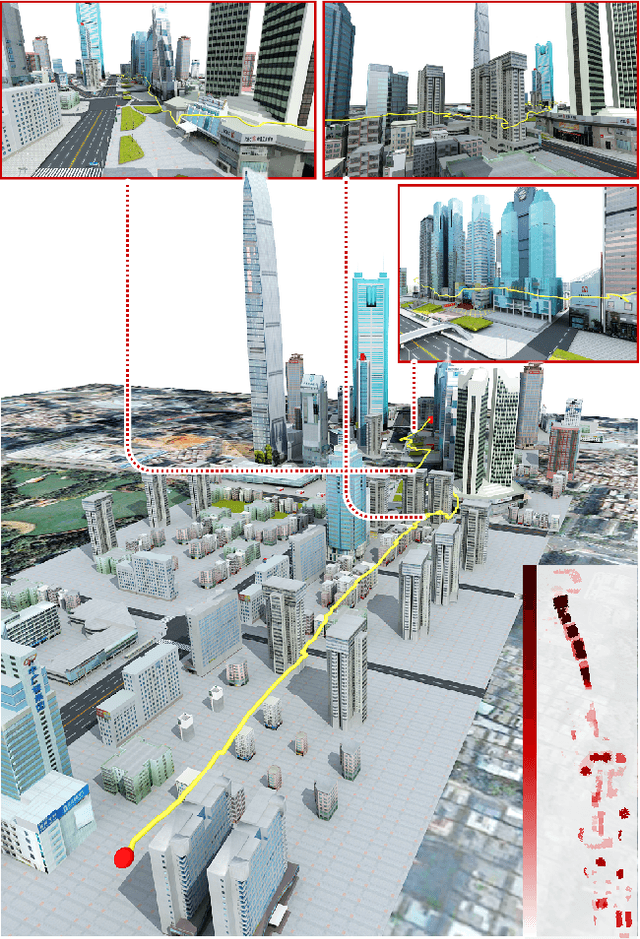
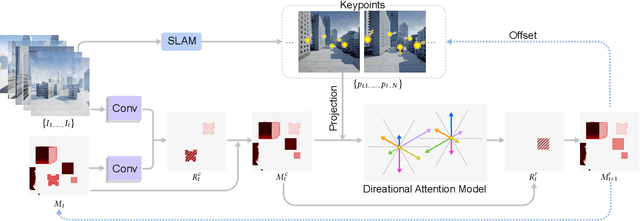

The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a Visual-Geometric Fusion Network(VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified Visual-Geometric Representation. This representation is fed to a new Directional Attention Model(DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes. The dataset can be found in http://vcc.szu.edu.cn/research/2021/VGFNet.
* Accepted by CVM 2021