 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-VLM: Event-Augmented Vision-Language Model for Scene Understanding
May 21, 2026Conventional vision-language models (VLMs) struggle to interpret scenes captured under adverse conditions (e.g., low light, high dynamic range, or fast motion) because standard RGB images degrade in such environments. Event cameras provide a complementary modality: they asynchronously record per-pixel brightness changes with high temporal resolution and wide dynamic range, preserving motion cues where frames fail. We propose RE-VLM, the first dual-stream vision-language model that jointly leverages RGB images and event streams for robust scene understanding across both normal and challenging conditions. RE-VLM employs parallel RGB and event encoders together with a progressive training strategy that aligns heterogeneous visual features with language. To address the scarcity of RGB-Event-Text supervision, we further propose a graph-driven pipeline that converts synchronized RGB-Event streams into verifiable scene graphs, from which we synthesize captions and question-answer (QA) pairs. To develop and evaluate RE-VLM, we construct two datasets: PEOD-Chat, targeting illumination-challenged scenes, and RGBE-Chat, covering diverse scenarios. On captioning and VQA benchmarks, RE-VLM consistently outperforms state-of-the-art RGB-only and event-only models with comparable parameter counts, with particularly large gains under challenging conditions. These results demonstrate the effectiveness of event-augmented VLMs in achieving robust vision-language understanding across a wide range of real-world environments.
CAPT: Confusion-Aware Prompt Tuning for Reducing Vision-Language Misalignment
Mar 03, 2026Vision-language models like CLIP have achieved remarkable progress in cross-modal representation learning, yet suffer from systematic misclassifications among visually and semantically similar categories. We observe that such confusion patterns are not random but persistently occur between specific category pairs, revealing the model's intrinsic bias and limited fine-grained discriminative ability. To address this, we propose CAPT, a Confusion-Aware Prompt Tuning framework that enables models to learn from their own misalignment. Specifically, we construct a Confusion Bank to explicitly model stable confusion relationships across categories and misclassified samples. On this basis, we introduce a Semantic Confusion Miner (SEM) to capture global inter-class confusion through semantic difference and commonality prompts, and a Sample Confusion Miner (SAM) to retrieve representative misclassified instances from the bank and capture sample-level cues through a Diff-Manner Adapter that integrates global and local contexts. To further unify confusion information across different granularities, a Multi-Granularity Difference Expert (MGDE) module is designed to jointly leverage semantic- and sample-level experts for more robust confusion-aware reasoning. Extensive experiments on 11 benchmark datasets demonstrate that our method significantly reduces confusion-induced errors while enhancing the discriminability and generalization of both base and novel classes, successfully resolving 50.72 percent of confusable sample pairs. Code will be released at https://github.com/greatest-gourmet/CAPT.
PEOD: A Pixel-Aligned Event-RGB Benchmark for Object Detection under Challenging Conditions
Nov 11, 2025Robust object detection for challenging scenarios increasingly relies on event cameras, yet existing Event-RGB datasets remain constrained by sparse coverage of extreme conditions and low spatial resolution (<= 640 x 480), which prevents comprehensive evaluation of detectors under challenging scenarios. To address these limitations, we propose PEOD, the first large-scale, pixel-aligned and high-resolution (1280 x 720) Event-RGB dataset for object detection under challenge conditions. PEOD contains 130+ spatiotemporal-aligned sequences and 340k manual bounding boxes, with 57% of data captured under low-light, overexposure, and high-speed motion. Furthermore, we benchmark 14 methods across three input configurations (Event-based, RGB-based, and Event-RGB fusion) on PEOD. On the full test set and normal subset, fusion-based models achieve the excellent performance. However, in illumination challenge subset, the top event-based model outperforms all fusion models, while fusion models still outperform their RGB-based counterparts, indicating limits of existing fusion methods when the frame modality is severely degraded. PEOD establishes a realistic, high-quality benchmark for multimodal perception and facilitates future research.
Source-free Semantic Regularization Learning for Semi-supervised Domain Adaptation
Jan 02, 2025



Semi-supervised domain adaptation (SSDA) has been extensively researched due to its ability to improve classification performance and generalization ability of models by using a small amount of labeled data on the target domain. However, existing methods cannot effectively adapt to the target domain due to difficulty in fully learning rich and complex target semantic information and relationships. In this paper, we propose a novel SSDA learning framework called semantic regularization learning (SERL), which captures the target semantic information from multiple perspectives of regularization learning to achieve adaptive fine-tuning of the source pre-trained model on the target domain. SERL includes three robust semantic regularization techniques. Firstly, semantic probability contrastive regularization (SPCR) helps the model learn more discriminative feature representations from a probabilistic perspective, using semantic information on the target domain to understand the similarities and differences between samples. Additionally, adaptive weights in SPCR can help the model learn the semantic distribution correctly through the probabilities of different samples. To further comprehensively understand the target semantic distribution, we introduce hard-sample mixup regularization (HMR), which uses easy samples as guidance to mine the latent target knowledge contained in hard samples, thereby learning more complete and complex target semantic knowledge. Finally, target prediction regularization (TPR) regularizes the target predictions of the model by maximizing the correlation between the current prediction and the past learned objective, thereby mitigating the misleading of semantic information caused by erroneous pseudo-labels. Extensive experiments on three benchmark datasets demonstrate that our SERL method achieves state-of-the-art performance.
Learning from Different Samples: A Source-free Framework for Semi-supervised Domain Adaptation
Nov 11, 2024Semi-supervised domain adaptation (SSDA) has been widely studied due to its ability to utilize a few labeled target data to improve the generalization ability of the model. However, existing methods only consider designing certain strategies for target samples to adapt, ignoring the exploration of customized learning for different target samples. When the model encounters complex target distribution, existing methods will perform limited due to the inability to clearly and comprehensively learn the knowledge of multiple types of target samples. To fill this gap, this paper focuses on designing a framework to use different strategies for comprehensively mining different target samples. We propose a novel source-free framework (SOUF) to achieve semi-supervised fine-tuning of the source pre-trained model on the target domain. Different from existing SSDA methods, SOUF decouples SSDA from the perspectives of different target samples, specifically designing robust learning techniques for unlabeled, reliably labeled, and noisy pseudo-labeled target samples. For unlabeled target samples, probability-based weighted contrastive learning (PWC) helps the model learn more discriminative feature representations. To mine the latent knowledge of labeled target samples, reliability-based mixup contrastive learning (RMC) learns complex knowledge from the constructed reliable sample set. Finally, predictive regularization learning (PR) further mitigates the misleading effect of noisy pseudo-labeled samples on the model. Extensive experiments on benchmark datasets demonstrate the superiority of our framework over state-of-the-art methods.
Learning from Noisy Labels for Long-tailed Data via Optimal Transport
Aug 07, 2024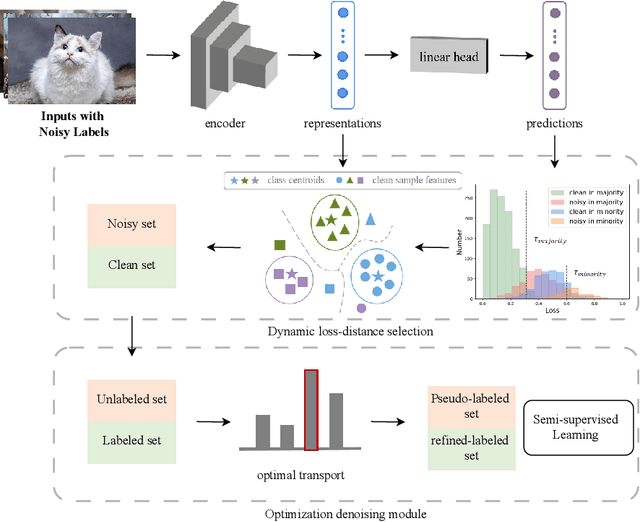
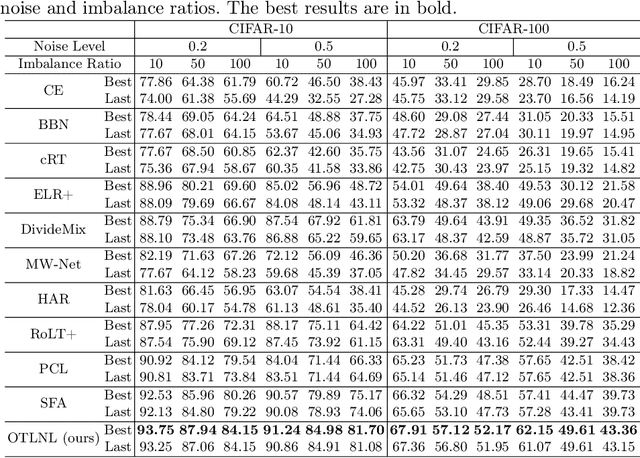
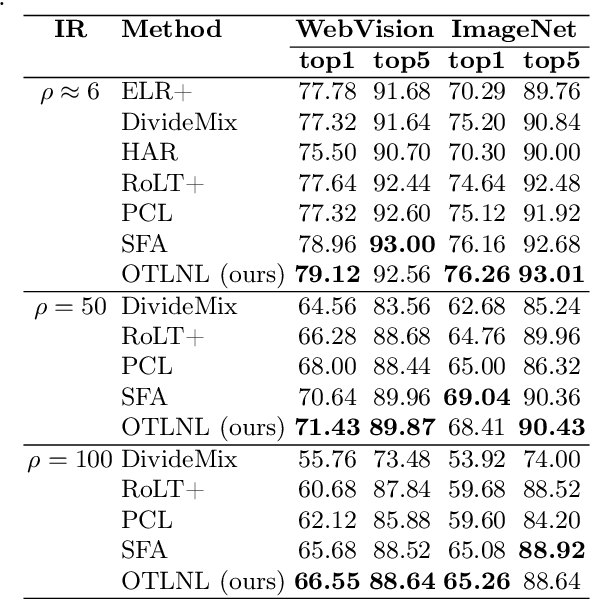
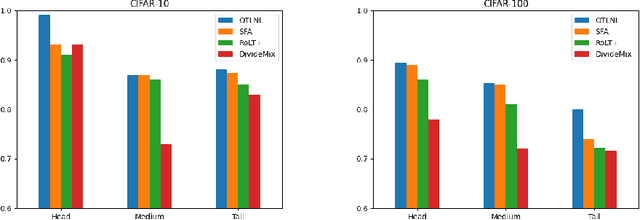
Noisy labels, which are common in real-world datasets, can significantly impair the training of deep learning models. However, recent adversarial noise-combating methods overlook the long-tailed distribution of real data, which can significantly harm the effect of denoising strategies. Meanwhile, the mismanagement of noisy labels further compromises the model's ability to handle long-tailed data. To tackle this issue, we propose a novel approach to manage data characterized by both long-tailed distributions and noisy labels. First, we introduce a loss-distance cross-selection module, which integrates class predictions and feature distributions to filter clean samples, effectively addressing uncertainties introduced by noisy labels and long-tailed distributions. Subsequently, we employ optimal transport strategies to generate pseudo-labels for the noise set in a semi-supervised training manner, enhancing pseudo-label quality while mitigating the effects of sample scarcity caused by the long-tailed distribution. We conduct experiments on both synthetic and real-world datasets, and the comprehensive experimental results demonstrate that our method surpasses current state-of-the-art methods. Our code will be available in the future.
SwinSF: Image Reconstruction from Spatial-Temporal Spike Streams
Jul 24, 2024The spike camera, with its high temporal resolution, low latency, and high dynamic range, addresses high-speed imaging challenges like motion blur. It captures photons at each pixel independently, creating binary spike streams rich in temporal information but challenging for image reconstruction. Current algorithms, both traditional and deep learning-based, still need to be improved in the utilization of the rich temporal detail and the restoration of the details of the reconstructed image. To overcome this, we introduce Swin Spikeformer (SwinSF), a novel model for dynamic scene reconstruction from spike streams. SwinSF is composed of Spike Feature Extraction, Spatial-Temporal Feature Extraction, and Final Reconstruction Module. It combines shifted window self-attention and proposed temporal spike attention, ensuring a comprehensive feature extraction that encapsulates both spatial and temporal dynamics, leading to a more robust and accurate reconstruction of spike streams. Furthermore, we build a new synthesized dataset for spike image reconstruction which matches the resolution of the latest spike camera, ensuring its relevance and applicability to the latest developments in spike camera imaging. Experimental results demonstrate that the proposed network SwinSF sets a new benchmark, achieving state-of-the-art performance across a series of datasets, including both real-world and synthesized data across various resolutions. Our codes and proposed dataset will be available soon.
Learning Robust Correlation with Foundation Model for Weakly-Supervised Few-Shot Segmentation
May 30, 2024Existing few-shot segmentation (FSS) only considers learning support-query correlation and segmenting unseen categories under the precise pixel masks. However, the cost of a large number of pixel masks during training is expensive. This paper considers a more challenging scenario, weakly-supervised few-shot segmentation (WS-FSS), which only provides category ($i.e.$ image-level) labels. It requires the model to learn robust support-query information when the generated mask is inaccurate. In this work, we design a Correlation Enhancement Network (CORENet) with foundation model, which utilizes multi-information guidance to learn robust correlation. Specifically, correlation-guided transformer (CGT) utilizes self-supervised ViT tokens to learn robust correlation from both local and global perspectives. From the perspective of semantic categories, the class-guided module (CGM) guides the model to locate valuable correlations through the pre-trained CLIP. Finally, the embedding-guided module (EGM) implicitly guides the model to supplement the inevitable information loss during the correlation learning by the original appearance embedding and finally generates the query mask. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ have shown that CORENet exhibits excellent performance compared to existing methods.
Noisy Label Processing for Classification: A Survey
Apr 05, 2024In recent years, deep neural networks (DNNs) have gained remarkable achievement in computer vision tasks, and the success of DNNs often depends greatly on the richness of data. However, the acquisition process of data and high-quality ground truth requires a lot of manpower and money. In the long, tedious process of data annotation, annotators are prone to make mistakes, resulting in incorrect labels of images, i.e., noisy labels. The emergence of noisy labels is inevitable. Moreover, since research shows that DNNs can easily fit noisy labels, the existence of noisy labels will cause significant damage to the model training process. Therefore, it is crucial to combat noisy labels for computer vision tasks, especially for classification tasks. In this survey, we first comprehensively review the evolution of different deep learning approaches for noisy label combating in the image classification task. In addition, we also review different noise patterns that have been proposed to design robust algorithms. Furthermore, we explore the inner pattern of real-world label noise and propose an algorithm to generate a synthetic label noise pattern guided by real-world data. We test the algorithm on the well-known real-world dataset CIFAR-10N to form a new real-world data-guided synthetic benchmark and evaluate some typical noise-robust methods on the benchmark.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023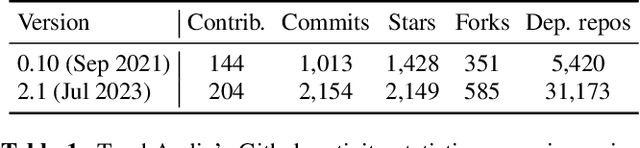


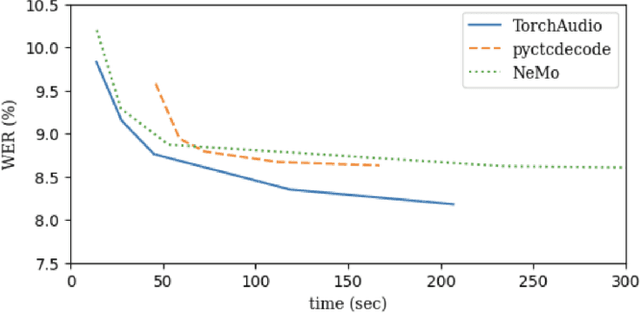
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.