 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Labels for Long-tailed Data via Optimal Transport
Paper and Code
Aug 07, 2024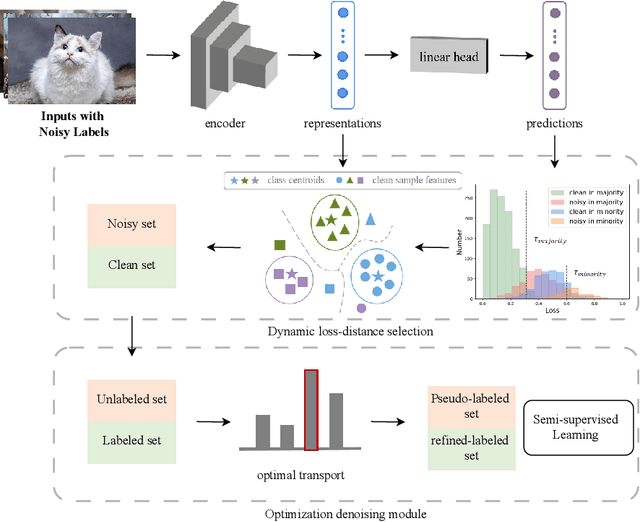
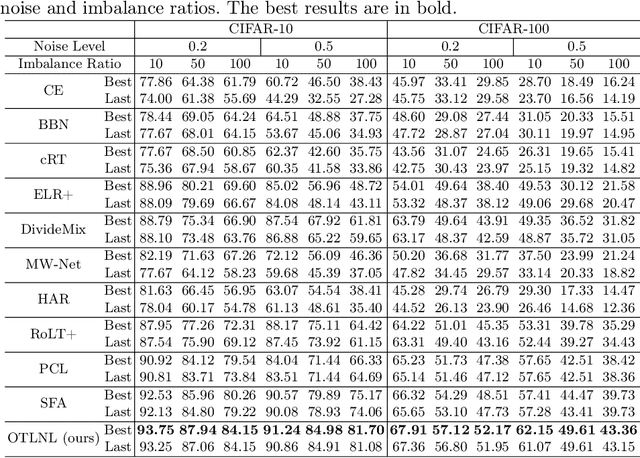
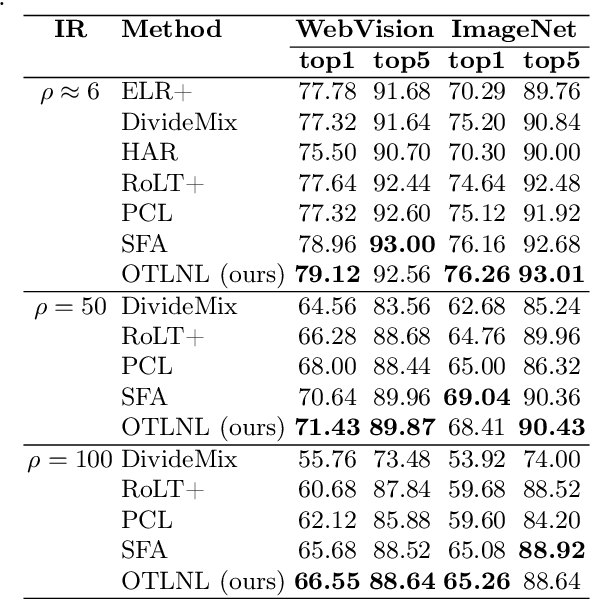
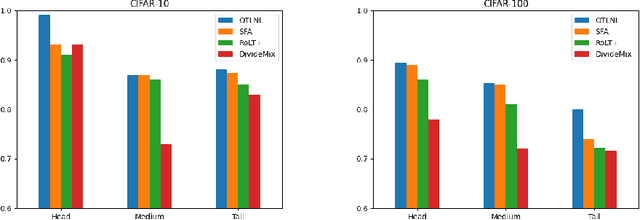
Noisy labels, which are common in real-world datasets, can significantly impair the training of deep learning models. However, recent adversarial noise-combating methods overlook the long-tailed distribution of real data, which can significantly harm the effect of denoising strategies. Meanwhile, the mismanagement of noisy labels further compromises the model's ability to handle long-tailed data. To tackle this issue, we propose a novel approach to manage data characterized by both long-tailed distributions and noisy labels. First, we introduce a loss-distance cross-selection module, which integrates class predictions and feature distributions to filter clean samples, effectively addressing uncertainties introduced by noisy labels and long-tailed distributions. Subsequently, we employ optimal transport strategies to generate pseudo-labels for the noise set in a semi-supervised training manner, enhancing pseudo-label quality while mitigating the effects of sample scarcity caused by the long-tailed distribution. We conduct experiments on both synthetic and real-world datasets, and the comprehensive experimental results demonstrate that our method surpasses current state-of-the-art methods. Our code will be available in the future.