 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlux Attention: Context-Aware Hybrid Attention for Efficient LLMs Inference
Apr 08, 2026The quadratic computational complexity of standard attention mechanisms presents a severe scalability bottleneck for LLMs in long-context scenarios. While hybrid attention mechanisms combining Full Attention (FA) and Sparse Attention (SA) offer a potential solution, existing methods typically rely on static allocation ratios that fail to accommodate the variable retrieval demands of different tasks. Furthermore, head-level dynamic sparsity often introduces severe computational load imbalance and synchronization long-tails, which hinder hardware acceleration during autoregressive decoding. To bridge this gap, we introduce Flux Attention, a context-aware framework that dynamically optimizes attention computation at the layer level. By integrating a lightweight Layer Router into frozen pretrained LLMs, the proposed method adaptively routes each layer to FA or SA based on the input context. This layer-wise routing preserves high-fidelity information retrieval while ensuring contiguous memory access, translating theoretical computational reductions into practical wall-clock speedups. As a parameter-efficient approach, our framework requires only 12 hours of training on 8$\times$A800 GPUs. Extensive experiments across multiple long-context and mathematical reasoning benchmarks demonstrate that Flux Attention achieves a superior trade-off between performance and inference speed compared with baseline models, with speed improvements of up to $2.8\times$ and $2.0\times$ in the prefill and decode stages.
Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Jan 24, 2026The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for large language models (LLMs) in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
AdaptInfer: Adaptive Token Pruning for Vision-Language Model Inference with Dynamical Text Guidance
Aug 08, 2025Vision-language models (VLMs) have achieved impressive performance on multimodal reasoning tasks such as visual question answering (VQA), but their inference cost remains a significant challenge due to the large number of vision tokens processed during the prefill stage. Existing pruning methods often rely on directly using the attention patterns or static text prompt guidance, failing to exploit the dynamic internal signals generated during inference. To address these issues, we propose AdaptInfer, a plug-and-play framework for adaptive vision token pruning in VLMs. First, we introduce a fine-grained, dynamic text-guided pruning mechanism that reuses layer-wise text-to-text attention maps to construct soft priors over text-token importance, allowing more informed scoring of vision tokens at each stage. Second, we perform an offline analysis of cross-modal attention shifts and identify consistent inflection locations in inference, which inspire us to propose a more principled and efficient pruning schedule. Our method is lightweight and plug-and-play, also generalizable across multi-modal tasks. Experimental results have verified the effectiveness of the proposed method. For example, it reduces CUDA latency by 61.3\% while maintaining an average accuracy of 92.9\% on vanilla LLaVA-1.5-7B. Under the same token budget, AdaptInfer surpasses SOTA in accuracy.
SynSeg: Feature Synergy for Multi-Category Contrastive Learning in Open-Vocabulary Semantic Segmentation
Aug 08, 2025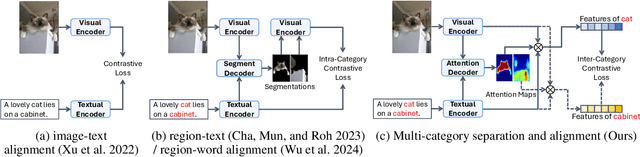
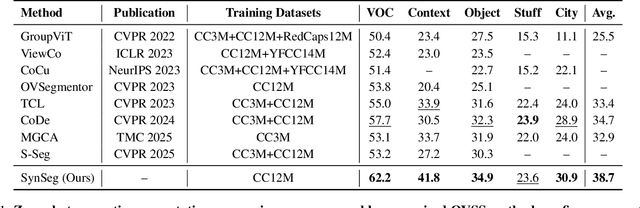
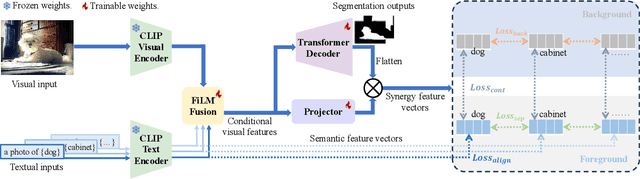
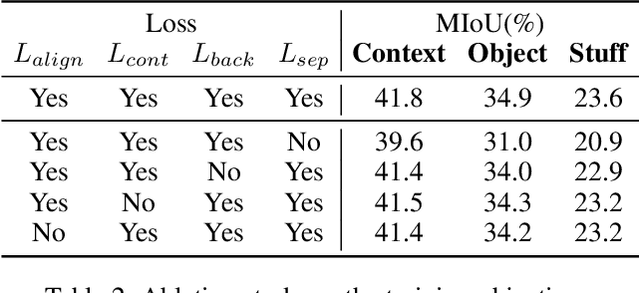
Semantic segmentation in open-vocabulary scenarios presents significant challenges due to the wide range and granularity of semantic categories. Existing weakly-supervised methods often rely on category-specific supervision and ill-suited feature construction methods for contrastive learning, leading to semantic misalignment and poor performance. In this work, we propose a novel weakly-supervised approach, SynSeg, to address the challenges. SynSeg performs Multi-Category Contrastive Learning (MCCL) as a stronger training signal with a new feature reconstruction framework named Feature Synergy Structure (FSS). Specifically, MCCL strategy robustly combines both intra- and inter-category alignment and separation in order to make the model learn the knowledge of correlations from different categories within the same image. Moreover, FSS reconstructs discriminative features for contrastive learning through prior fusion and semantic-activation-map enhancement, effectively avoiding the foreground bias introduced by the visual encoder. In general, SynSeg effectively improves the abilities in semantic localization and discrimination under weak supervision. Extensive experiments on benchmarks demonstrate that our method outperforms state-of-the-art (SOTA) performance. For instance, SynSeg achieves higher accuracy than SOTA baselines by 4.5\% on VOC, 8.9\% on Context, 2.6\% on Object and 2.0\% on City.
Phased Array Calibration based on Rotating-Element Harmonic Electric-Field Vector with Time Modulation
Apr 17, 2025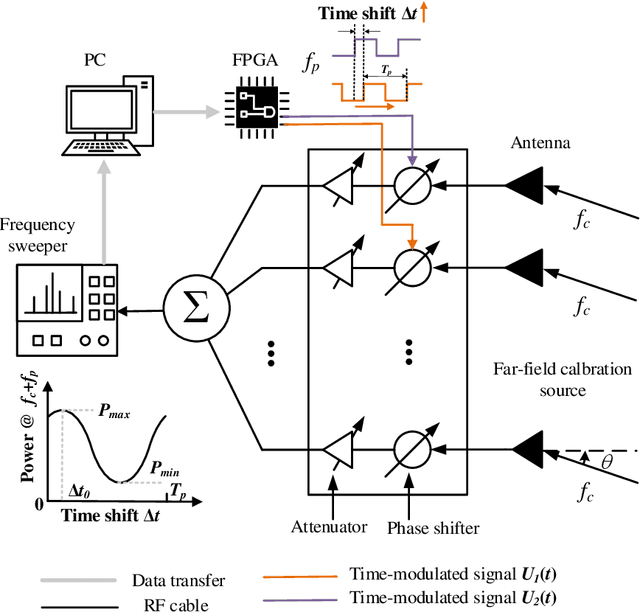
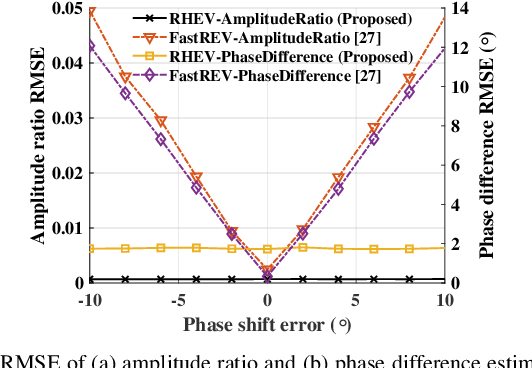
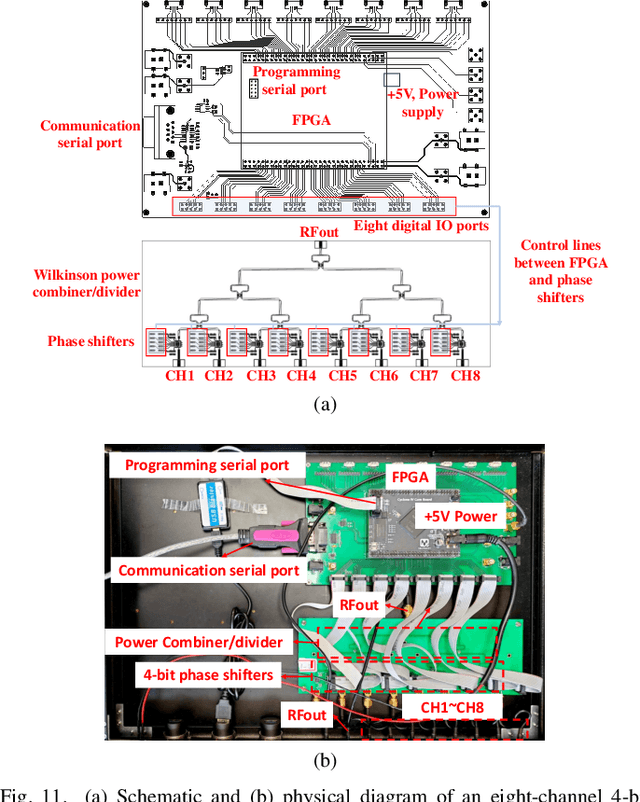
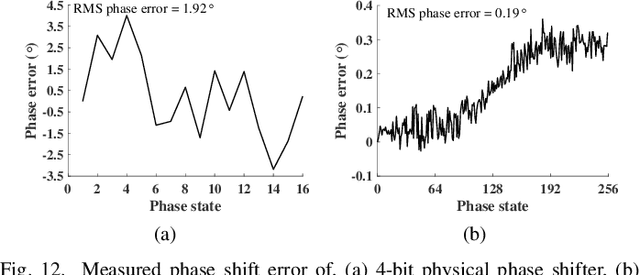
Calibration is crucial for ensuring the performance of phased array since amplitude-phase imbalance between elements results in significant performance degradation. While amplitude-only calibration methods offer advantages when phase measurements are impractical, conventional approaches face two key challenges: they typically require high-resolution phase shifters and remain susceptible to phase errors inherent in these components. To overcome these limitations, we propose a Rotating element Harmonic Electric-field Vector (RHEV) strategy, which enables precise calibration through time modulation principles. The proposed technique functions as follows. Two 1-bit phase shifters are periodically phase-switched at the same frequency, each generating corresponding harmonics. By adjusting the relative delay between their modulation timings, the phase difference between the $+1$st harmonics produced by the two elements can be precisely controlled, utilizing the time-shift property of the Fourier transform. Furthermore, the +1st harmonic generated by sequential modulation of individual elements exhibits a linear relationship with the amplitude of the modulated element, enabling amplitude ambiguity resolution. The proposed RHEV-based calibration method generates phase shifts through relative timing delays rather than physical phase shifter adjustments, rendering it less susceptible to phase shift errors. Additionally, since the calibration process exclusively utilizes the $+1$st harmonic, which is produced solely by the modulated unit, the method demonstrates consistent performance regardless of array size. Extensive numerical simulations, practical in-channel and over-the-air (OTA) calibration experiments demonstrate the effectiveness and distinct advantages of the proposed method.
Palantir: Towards Efficient Super Resolution for Ultra-high-definition Live Streaming
Aug 12, 2024Neural enhancement through super-resolution deep neural networks opens up new possibilities for ultra-high-definition live streaming over existing encoding and networking infrastructure. Yet, the heavy SR DNN inference overhead leads to severe deployment challenges. To reduce the overhead, existing systems propose to apply DNN-based SR only on selected anchor frames while upscaling non-anchor frames via the lightweight reusing-based SR approach. However, frame-level scheduling is coarse-grained and fails to deliver optimal efficiency. In this work, we propose Palantir, the first neural-enhanced UHD live streaming system with fine-grained patch-level scheduling. In the presented solutions, two novel techniques are incorporated to make good scheduling decisions for inference overhead optimization and reduce the scheduling latency. Firstly, under the guidance of our pioneering and theoretical analysis, Palantir constructs a directed acyclic graph (DAG) for lightweight yet accurate quality estimation under any possible anchor patch set. Secondly, to further optimize the scheduling latency, Palantir improves parallelizability by refactoring the computation subprocedure of the estimation process into a sparse matrix-matrix multiplication operation. The evaluation results suggest that Palantir incurs a negligible scheduling latency accounting for less than 5.7% of the end-to-end latency requirement. When compared to the state-of-the-art real-time frame-level scheduling strategy, Palantir reduces the energy overhead of SR-integrated mobile clients by 38.1% at most (and 22.4% on average) and the monetary costs of cloud-based SR by 80.1% at most (and 38.4% on average).
Learning Robust Correlation with Foundation Model for Weakly-Supervised Few-Shot Segmentation
May 30, 2024Existing few-shot segmentation (FSS) only considers learning support-query correlation and segmenting unseen categories under the precise pixel masks. However, the cost of a large number of pixel masks during training is expensive. This paper considers a more challenging scenario, weakly-supervised few-shot segmentation (WS-FSS), which only provides category ($i.e.$ image-level) labels. It requires the model to learn robust support-query information when the generated mask is inaccurate. In this work, we design a Correlation Enhancement Network (CORENet) with foundation model, which utilizes multi-information guidance to learn robust correlation. Specifically, correlation-guided transformer (CGT) utilizes self-supervised ViT tokens to learn robust correlation from both local and global perspectives. From the perspective of semantic categories, the class-guided module (CGM) guides the model to locate valuable correlations through the pre-trained CLIP. Finally, the embedding-guided module (EGM) implicitly guides the model to supplement the inevitable information loss during the correlation learning by the original appearance embedding and finally generates the query mask. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ have shown that CORENet exhibits excellent performance compared to existing methods.
Hard-aware Instance Adaptive Self-training for Unsupervised Cross-domain Semantic Segmentation
Feb 14, 2023

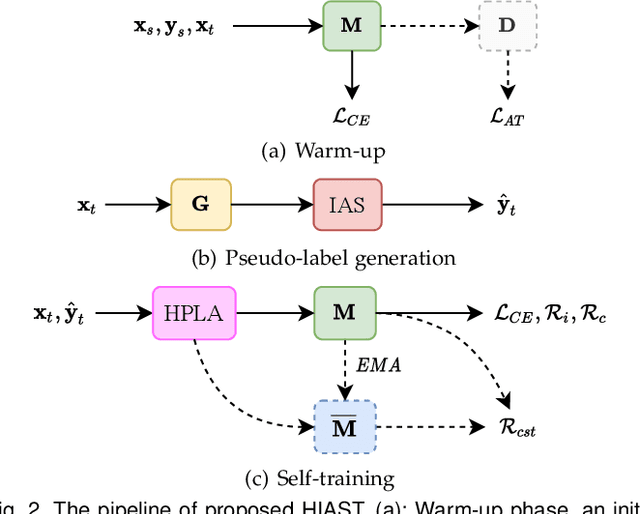
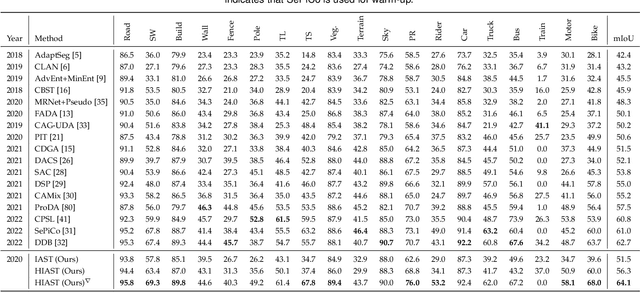
The divergence between labeled training data and unlabeled testing data is a significant challenge for recent deep learning models. Unsupervised domain adaptation (UDA) attempts to solve such problem. Recent works show that self-training is a powerful approach to UDA. However, existing methods have difficulty in balancing the scalability and performance. In this paper, we propose a hard-aware instance adaptive self-training framework for UDA on the task of semantic segmentation. To effectively improve the quality and diversity of pseudo-labels, we develop a novel pseudo-label generation strategy with an instance adaptive selector. We further enrich the hard class pseudo-labels with inter-image information through a skillfully designed hard-aware pseudo-label augmentation. Besides, we propose the region-adaptive regularization to smooth the pseudo-label region and sharpen the non-pseudo-label region. For the non-pseudo-label region, consistency constraint is also constructed to introduce stronger supervision signals during model optimization. Our method is so concise and efficient that it is easy to be generalized to other UDA methods. Experiments on GTA5 to Cityscapes, SYNTHIA to Cityscapes, and Cityscapes to Oxford RobotCar demonstrate the superior performance of our approach compared with the state-of-the-art methods.
Multiple Narrow-band signals Direction Finding with TMLA by Nonuniform Period Modulation
Mar 30, 2022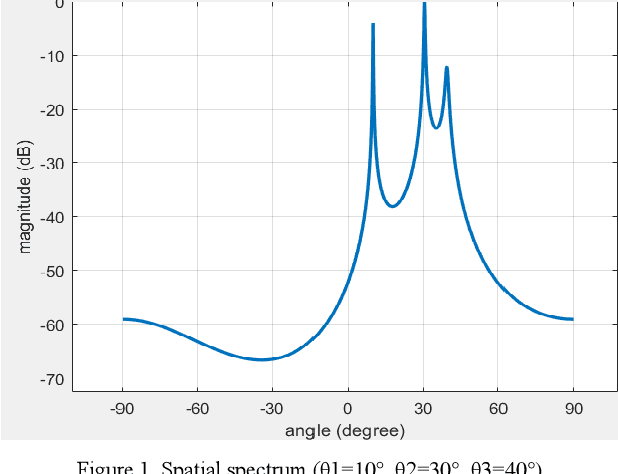

A new array signal reconstruction and signal-channel DOA estimation method based on TMLA by nonuniform period modulation are proposed. By using non-uniform period modulation, the harmonic component produced by different elements could be separated. Therefore, the conventional snapshot could be reconstructed by analyzing the spectrum of the combined signal. Then spatial spectrum estimation method is used to implement DOA estimation. Numerical simulations are provided to verify the feasibility and accuracy of the proposed method. Since the duration of the signal in the frequency domain analysis processed in a single time is very short, this method is also applicable to narrowband signals. Another highlight is that this method can simultaneously measure the number of the elements-1 angle of incident signals.