 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard-aware Instance Adaptive Self-training for Unsupervised Cross-domain Semantic Segmentation
Feb 14, 2023

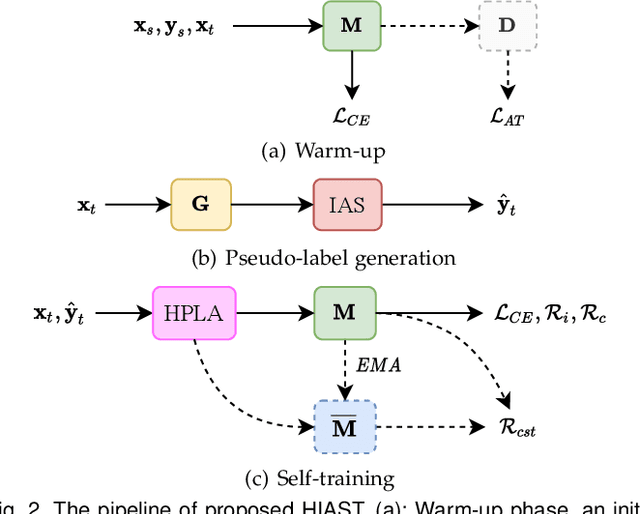
The divergence between labeled training data and unlabeled testing data is a significant challenge for recent deep learning models. Unsupervised domain adaptation (UDA) attempts to solve such problem. Recent works show that self-training is a powerful approach to UDA. However, existing methods have difficulty in balancing the scalability and performance. In this paper, we propose a hard-aware instance adaptive self-training framework for UDA on the task of semantic segmentation. To effectively improve the quality and diversity of pseudo-labels, we develop a novel pseudo-label generation strategy with an instance adaptive selector. We further enrich the hard class pseudo-labels with inter-image information through a skillfully designed hard-aware pseudo-label augmentation. Besides, we propose the region-adaptive regularization to smooth the pseudo-label region and sharpen the non-pseudo-label region. For the non-pseudo-label region, consistency constraint is also constructed to introduce stronger supervision signals during model optimization. Our method is so concise and efficient that it is easy to be generalized to other UDA methods. Experiments on GTA5 to Cityscapes, SYNTHIA to Cityscapes, and Cityscapes to Oxford RobotCar demonstrate the superior performance of our approach compared with the state-of-the-art methods.
WUDA: Unsupervised Domain Adaptation Based on Weak Source Domain Labels
Oct 05, 2022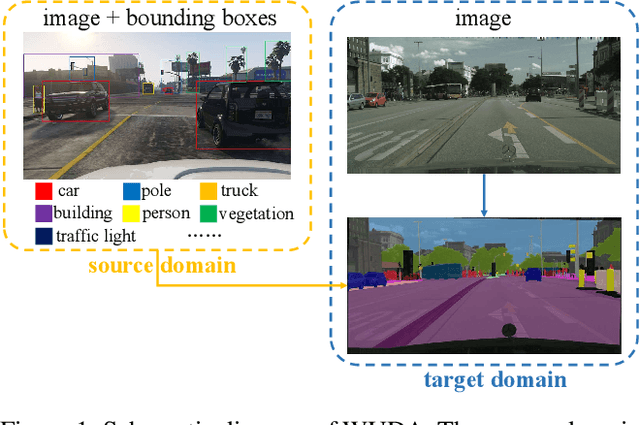

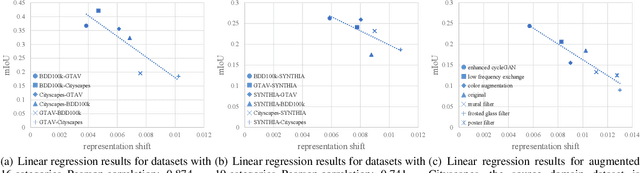
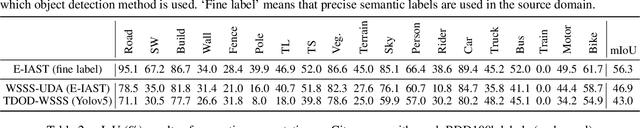
Unsupervised domain adaptation (UDA) for semantic segmentation addresses the cross-domain problem with fine source domain labels. However, the acquisition of semantic labels has always been a difficult step, many scenarios only have weak labels (e.g. bounding boxes). For scenarios where weak supervision and cross-domain problems coexist, this paper defines a new task: unsupervised domain adaptation based on weak source domain labels (WUDA). To explore solutions for this task, this paper proposes two intuitive frameworks: 1) Perform weakly supervised semantic segmentation in the source domain, and then implement unsupervised domain adaptation; 2) Train an object detection model using source domain data, then detect objects in the target domain and implement weakly supervised semantic segmentation. We observe that the two frameworks behave differently when the datasets change. Therefore, we construct dataset pairs with a wide range of domain shifts and conduct extended experiments to analyze the impact of different domain shifts on the two frameworks. In addition, to measure domain shift, we apply the metric representation shift to urban landscape image segmentation for the first time. The source code and constructed datasets are available at \url{https://github.com/bupt-ai-cz/WUDA}.
Predicting Axillary Lymph Node Metastasis in Early Breast Cancer Using Deep Learning on Primary Tumor Biopsy Slides
Dec 12, 2021

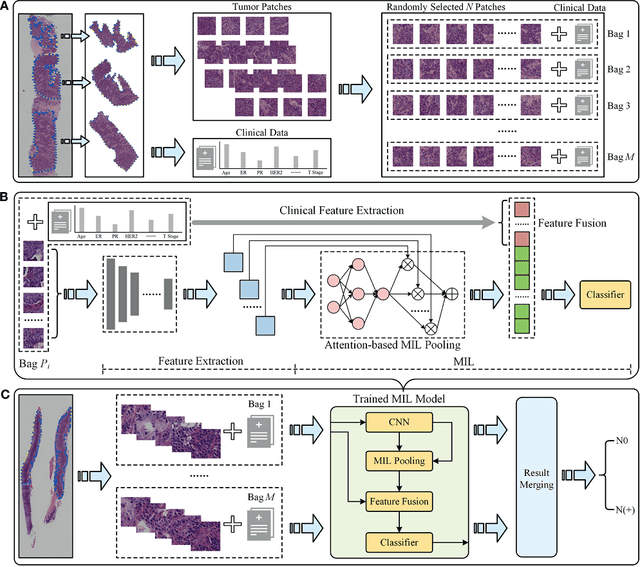
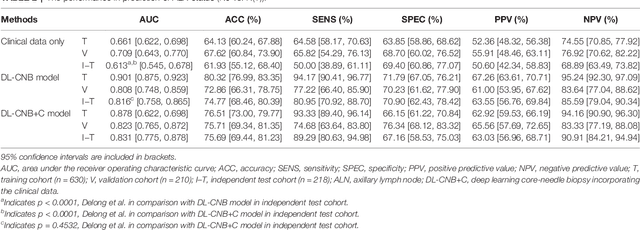
Objectives: To develop and validate a deep learning (DL)-based primary tumor biopsy signature for predicting axillary lymph node (ALN) metastasis preoperatively in early breast cancer (EBC) patients with clinically negative ALN. Methods: A total of 1,058 EBC patients with pathologically confirmed ALN status were enrolled from May 2010 to August 2020. A DL core-needle biopsy (DL-CNB) model was built on the attention-based multiple instance-learning (AMIL) framework to predict ALN status utilizing the DL features, which were extracted from the cancer areas of digitized whole-slide images (WSIs) of breast CNB specimens annotated by two pathologists. Accuracy, sensitivity, specificity, receiver operating characteristic (ROC) curves, and areas under the ROC curve (AUCs) were analyzed to evaluate our model. Results: The best-performing DL-CNB model with VGG16_BN as the feature extractor achieved an AUC of 0.816 (95% confidence interval (CI): 0.758, 0.865) in predicting positive ALN metastasis in the independent test cohort. Furthermore, our model incorporating the clinical data, which was called DL-CNB+C, yielded the best accuracy of 0.831 (95%CI: 0.775, 0.878), especially for patients younger than 50 years (AUC: 0.918, 95%CI: 0.825, 0.971). The interpretation of DL-CNB model showed that the top signatures most predictive of ALN metastasis were characterized by the nucleus features including density ($p$ = 0.015), circumference ($p$ = 0.009), circularity ($p$ = 0.010), and orientation ($p$ = 0.012). Conclusion: Our study provides a novel DL-based biomarker on primary tumor CNB slides to predict the metastatic status of ALN preoperatively for patients with EBC. The codes and dataset are available at https://github.com/bupt-ai-cz/BALNMP
* Accepted by Frontiers in Oncology, for more details, please see https://github.com/bupt-ai-cz/BALNMP
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
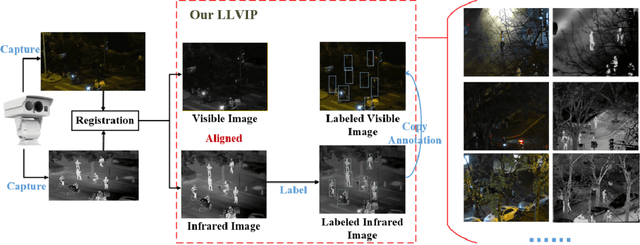
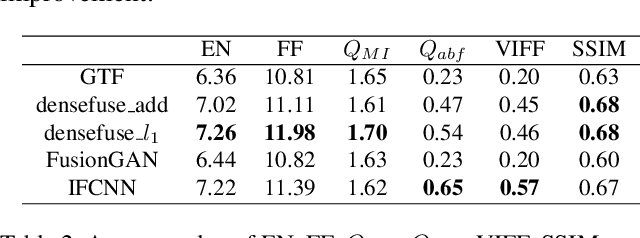

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.