 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd-Sourced NeRF: Collecting Data from Production Vehicles for 3D Street View Reconstruction
Jun 24, 2024



Recently, Neural Radiance Fields (NeRF) achieved impressive results in novel view synthesis. Block-NeRF showed the capability of leveraging NeRF to build large city-scale models. For large-scale modeling, a mass of image data is necessary. Collecting images from specially designed data-collection vehicles can not support large-scale applications. How to acquire massive high-quality data remains an opening problem. Noting that the automotive industry has a huge amount of image data, crowd-sourcing is a convenient way for large-scale data collection. In this paper, we present a crowd-sourced framework, which utilizes substantial data captured by production vehicles to reconstruct the scene with the NeRF model. This approach solves the key problem of large-scale reconstruction, that is where the data comes from and how to use them. Firstly, the crowd-sourced massive data is filtered to remove redundancy and keep a balanced distribution in terms of time and space. Then a structure-from-motion module is performed to refine camera poses. Finally, images, as well as poses, are used to train the NeRF model in a certain block. We highlight that we present a comprehensive framework that integrates multiple modules, including data selection, sparse 3D reconstruction, sequence appearance embedding, depth supervision of ground surface, and occlusion completion. The complete system is capable of effectively processing and reconstructing high-quality 3D scenes from crowd-sourced data. Extensive quantitative and qualitative experiments were conducted to validate the performance of our system. Moreover, we proposed an application, named first-view navigation, which leveraged the NeRF model to generate 3D street view and guide the driver with a synthesized video.
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
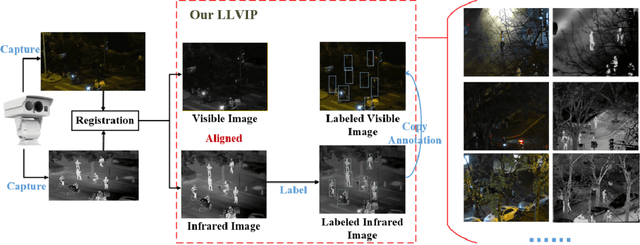
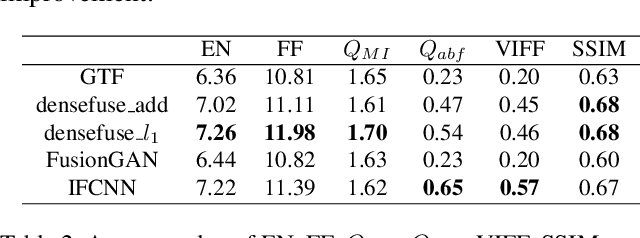

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.