 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Cross-Device Localization via Neural Metric Learning and Feature Fusion
Jan 30, 2026We present a hybrid cross-device localization pipeline developed for the CroCoDL 2025 Challenge. Our approach integrates a shared retrieval encoder and two complementary localization branches: a classical geometric branch using feature fusion and PnP, and a neural feed-forward branch (MapAnything) for metric localization conditioned on geometric inputs. A neural-guided candidate pruning strategy further filters unreliable map frames based on translation consistency, while depth-conditioned localization refines metric scale and translation precision on Spot scenes. These components jointly lead to significant improvements in recall and accuracy across both HYDRO and SUCCU benchmarks. Our method achieved a final score of 92.62 (R@0.5m, 5°) during the challenge.
Crowd-Sourced NeRF: Collecting Data from Production Vehicles for 3D Street View Reconstruction
Jun 24, 2024



Recently, Neural Radiance Fields (NeRF) achieved impressive results in novel view synthesis. Block-NeRF showed the capability of leveraging NeRF to build large city-scale models. For large-scale modeling, a mass of image data is necessary. Collecting images from specially designed data-collection vehicles can not support large-scale applications. How to acquire massive high-quality data remains an opening problem. Noting that the automotive industry has a huge amount of image data, crowd-sourcing is a convenient way for large-scale data collection. In this paper, we present a crowd-sourced framework, which utilizes substantial data captured by production vehicles to reconstruct the scene with the NeRF model. This approach solves the key problem of large-scale reconstruction, that is where the data comes from and how to use them. Firstly, the crowd-sourced massive data is filtered to remove redundancy and keep a balanced distribution in terms of time and space. Then a structure-from-motion module is performed to refine camera poses. Finally, images, as well as poses, are used to train the NeRF model in a certain block. We highlight that we present a comprehensive framework that integrates multiple modules, including data selection, sparse 3D reconstruction, sequence appearance embedding, depth supervision of ground surface, and occlusion completion. The complete system is capable of effectively processing and reconstructing high-quality 3D scenes from crowd-sourced data. Extensive quantitative and qualitative experiments were conducted to validate the performance of our system. Moreover, we proposed an application, named first-view navigation, which leveraged the NeRF model to generate 3D street view and guide the driver with a synthesized video.
Incentive Compatibility for AI Alignment in Sociotechnical Systems: Positions and Prospects
Mar 01, 2024

The burgeoning integration of artificial intelligence (AI) into human society brings forth significant implications for societal governance and safety. While considerable strides have been made in addressing AI alignment challenges, existing methodologies primarily focus on technical facets, often neglecting the intricate sociotechnical nature of AI systems, which can lead to a misalignment between the development and deployment contexts. To this end, we posit a new problem worth exploring: Incentive Compatibility Sociotechnical Alignment Problem (ICSAP). We hope this can call for more researchers to explore how to leverage the principles of Incentive Compatibility (IC) from game theory to bridge the gap between technical and societal components to maintain AI consensus with human societies in different contexts. We further discuss three classical game problems for achieving IC: mechanism design, contract theory, and Bayesian persuasion, in addressing the perspectives, potentials, and challenges of solving ICSAP, and provide preliminary implementation conceptions.
Incorporating Learnt Local and Global Embeddings into Monocular Visual SLAM
Aug 04, 2021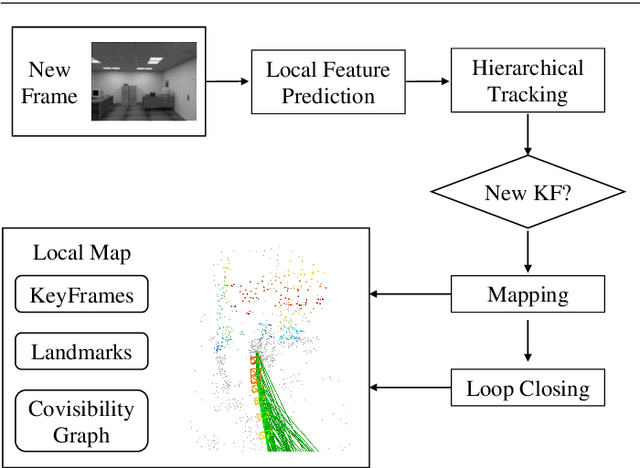

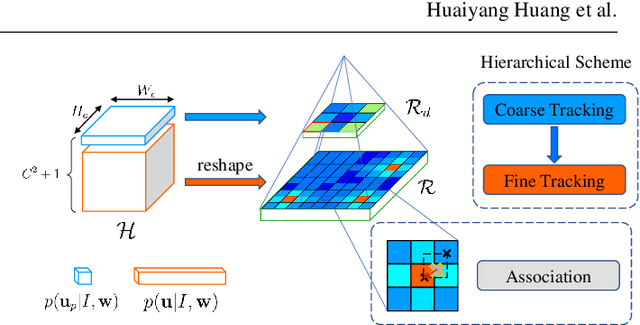
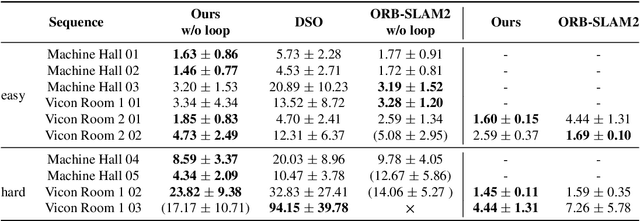
Traditional approaches for Visual Simultaneous Localization and Mapping (VSLAM) rely on low-level vision information for state estimation, such as handcrafted local features or the image gradient. While significant progress has been made through this track, under more challenging configuration for monocular VSLAM, e.g., varying illumination, the performance of state-of-the-art systems generally degrades. As a consequence, robustness and accuracy for monocular VSLAM are still widely concerned. This paper presents a monocular VSLAM system that fully exploits learnt features for better state estimation. The proposed system leverages both learnt local features and global embeddings at different modules of the system: direct camera pose estimation, inter-frame feature association, and loop closure detection. With a probabilistic explanation of keypoint prediction, we formulate the camera pose tracking in a direct manner and parameterize local features with uncertainty taken into account. To alleviate the quantization effect, we adapt the mapping module to generate 3D landmarks better to guarantee the system's robustness. Detecting temporal loop closure via deep global embeddings further improves the robustness and accuracy of the proposed system. The proposed system is extensively evaluated on public datasets (Tsukuba, EuRoC, and KITTI), and compared against the state-of-the-art methods. The competitive performance of camera pose estimation confirms the effectiveness of our method.
3D Surfel Map-Aided Visual Relocalization with Learned Descriptors
Apr 08, 2021
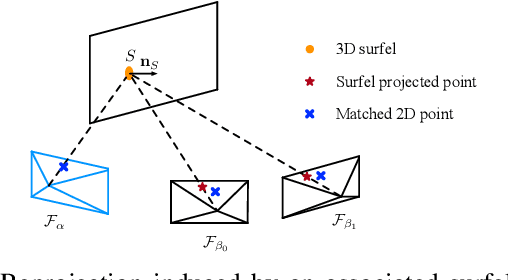


In this paper, we introduce a method for visual relocalization using the geometric information from a 3D surfel map. A visual database is first built by global indices from the 3D surfel map rendering, which provides associations between image points and 3D surfels. Surfel reprojection constraints are utilized to optimize the keyframe poses and map points in the visual database. A hierarchical camera relocalization algorithm then utilizes the visual database to estimate 6-DoF camera poses. Learned descriptors are further used to improve the performance in challenging cases. We present evaluation under real-world conditions and simulation to show the effectiveness and efficiency of our method, and make the final camera poses consistently well aligned with the 3D environment.
Greedy-Based Feature Selection for Efficient LiDAR SLAM
Mar 24, 2021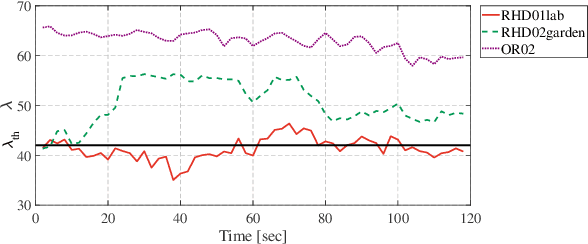
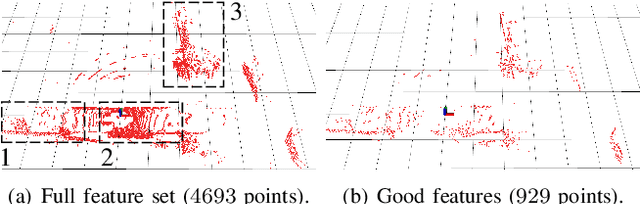
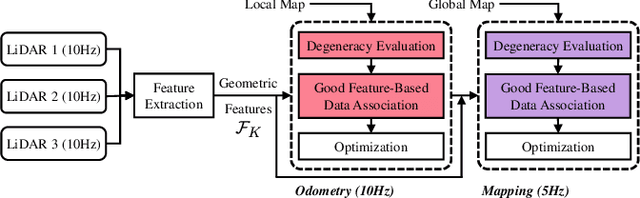
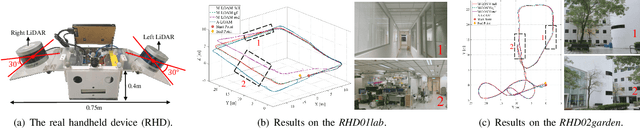
Modern LiDAR-SLAM (L-SLAM) systems have shown excellent results in large-scale, real-world scenarios. However, they commonly have a high latency due to the expensive data association and nonlinear optimization. This paper demonstrates that actively selecting a subset of features significantly improves both the accuracy and efficiency of an L-SLAM system. We formulate the feature selection as a combinatorial optimization problem under a cardinality constraint to preserve the information matrix's spectral attributes. The stochastic-greedy algorithm is applied to approximate the optimal results in real-time. To avoid ill-conditioned estimation, we also propose a general strategy to evaluate the environment's degeneracy and modify the feature number online. The proposed feature selector is integrated into a multi-LiDAR SLAM system. We validate this enhanced system with extensive experiments covering various scenarios on two sensor setups and computation platforms. We show that our approach exhibits low localization error and speedup compared to the state-of-the-art L-SLAM systems. To benefit the community, we have released the source code: https://ram-lab.com/file/site/m-loam.
Geometric Structure Aided Visual Inertial Localization
Nov 09, 2020

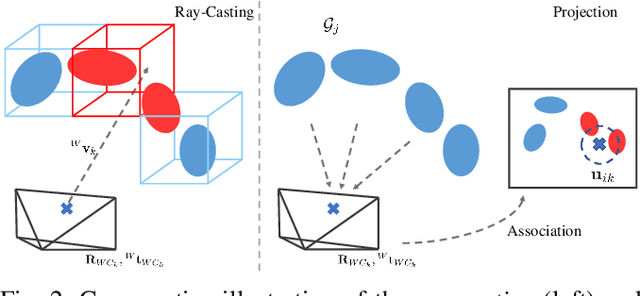

Visual Localization is an essential component in autonomous navigation. Existing approaches are either based on the visual structure from SLAM/SfM or the geometric structure from dense mapping. To take the advantages of both, in this work, we present a complete visual inertial localization system based on a hybrid map representation to reduce the computational cost and increase the positioning accuracy. Specially, we propose two modules for data association and batch optimization, respectively. To this end, we develop an efficient data association module to associate map components with local features, which takes only $2$ms to generate temporal landmarks. For batch optimization, instead of using visual factors, we develop a module to estimate a pose prior from the instant localization results to constrain poses. The experimental results on the EuRoC MAV dataset demonstrate a competitive performance compared to the state of the arts. Specially, our system achieves an average position error in 1.7 cm with 100% recall. The timings show that the proposed modules reduce the computational cost by 20-30%. We will make our implementation open source at http://github.com/hyhuang1995/gmmloc.
Robust Odometry and Mapping for Multi-LiDAR Systems with Online Extrinsic Calibration
Oct 27, 2020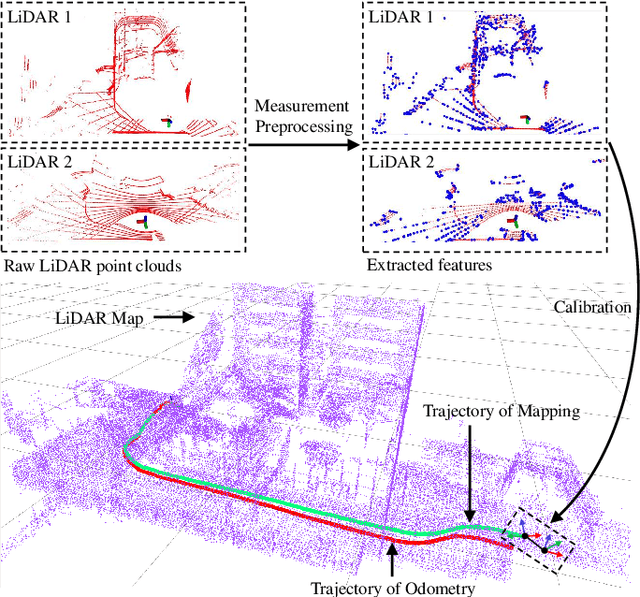
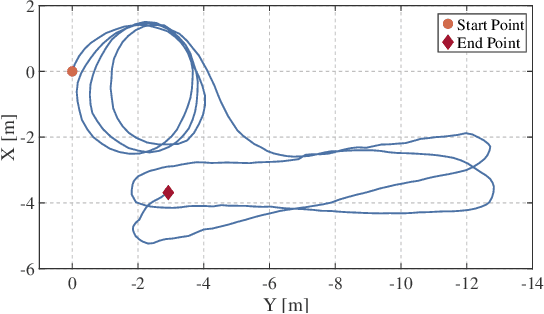
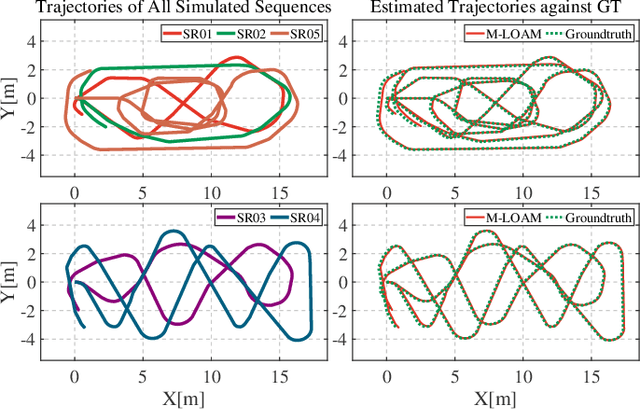
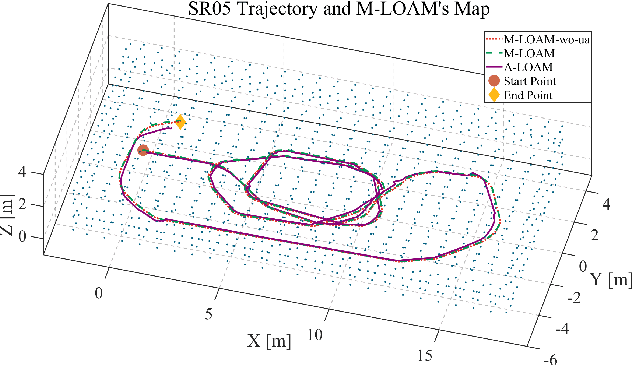
Combining multiple LiDARs enables a robot to maximize its perceptual awareness of environments and obtain sufficient measurements, which is promising for simultaneous localization and mapping (SLAM). This paper proposes a system to achieve robust and simultaneous extrinsic calibration, odometry, and mapping for multiple LiDARs. Our approach starts with measurement preprocessing to extract edge and planar features from raw measurements. After a motion and extrinsic initialization procedure, a sliding window-based multi-LiDAR odometry runs onboard to estimate poses with online calibration refinement and convergence identification. We further develop a mapping algorithm to construct a global map and optimize poses with sufficient features together with a method to model and reduce data uncertainty. We validate our approach's performance with extensive experiments on ten sequences (4.60km total length) for the calibration and SLAM and compare them against the state-of-the-art. We demonstrate that the proposed work is a complete, robust, and extensible system for various multi-LiDAR setups. The source code, datasets, and demonstrations are available at https://ram-lab.com/file/site/m-loam.
GMMLoc: Structure Consistent Visual Localization with Gaussian Mixture Models
Jun 24, 2020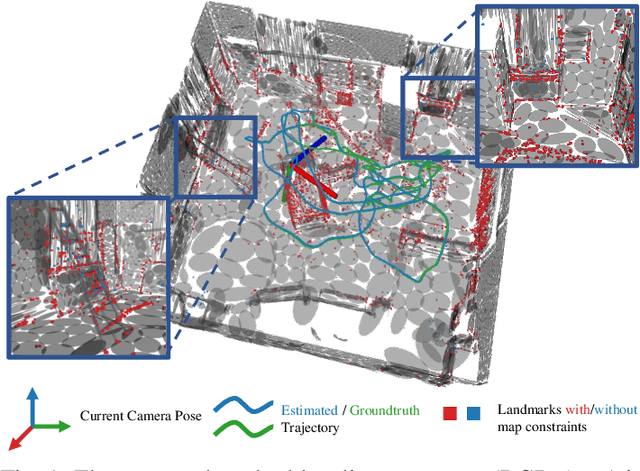



Incorporating prior structure information into the visual state estimation could generally improve the localization performance. In this letter, we aim to address the paradox between accuracy and efficiency in coupling visual factors with structure constraints. To this end, we present a cross-modality method that tracks a camera in a prior map modelled by the Gaussian Mixture Model (GMM). With the pose estimated by the front-end initially, the local visual observations and map components are associated efficiently, and the visual structure from the triangulation is refined simultaneously. By introducing the hybrid structure factors into the joint optimization, the camera poses are bundle-adjusted with the local visual structure. By evaluating our complete system, namely GMMLoc, on the public dataset, we show how our system can provide a centimeter-level localization accuracy with only trivial computational overhead. In addition, the comparative studies with the state-of-the-art vision-dominant state estimators demonstrate the competitive performance of our method.
Hercules: An Autonomous Logistic Vehicle for Contact-less Goods Transportation During the COVID-19 Outbreak
Apr 16, 2020
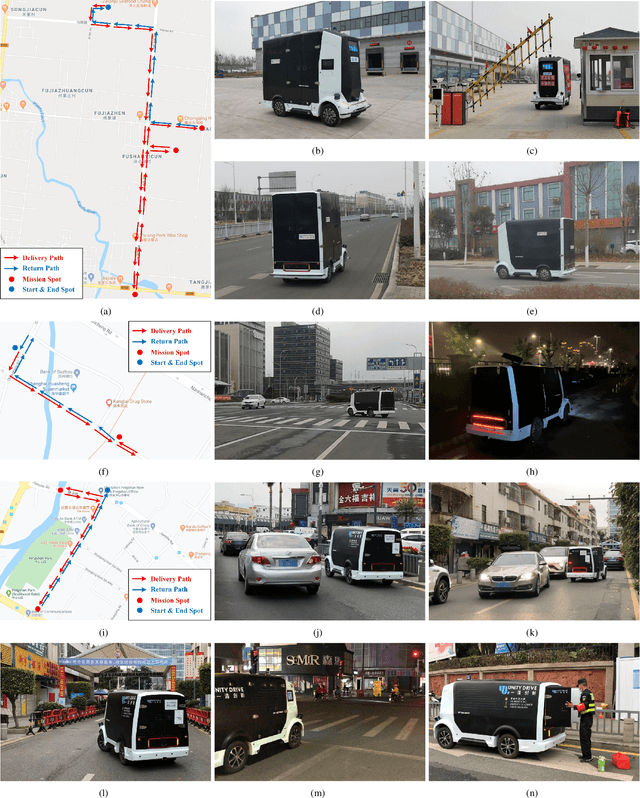
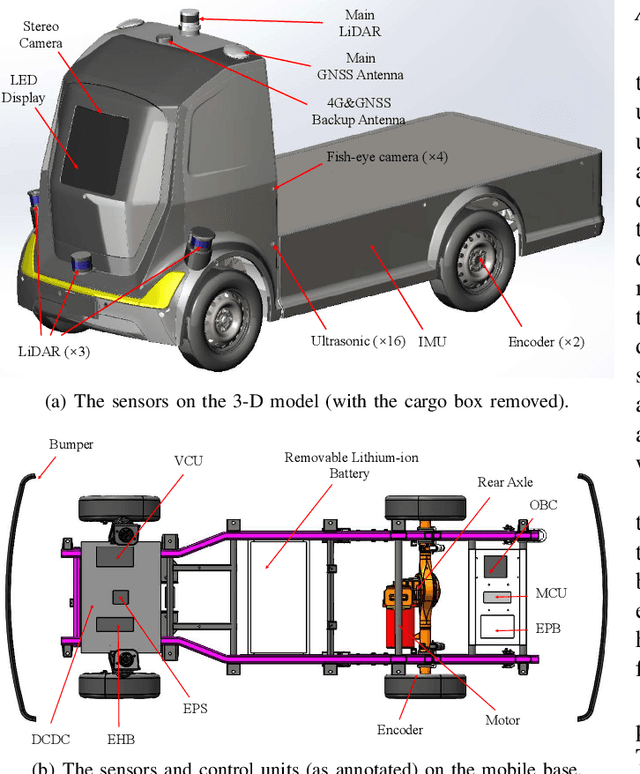
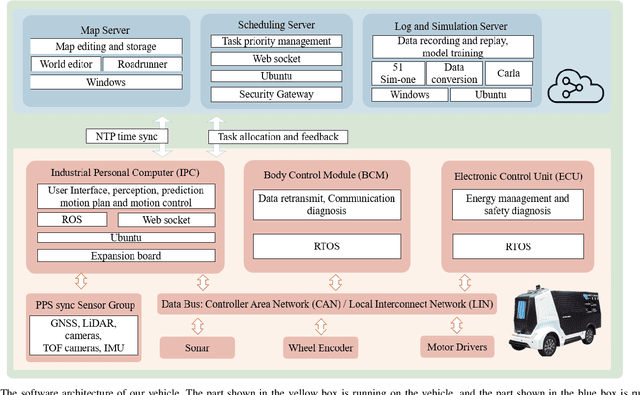
Since December 2019, the coronavirus disease 2019 (COVID-19) has spread rapidly across China. As at the date of writing this article, the disease has been globally reported in 100 countries, infected over 100,000 people and caused over 3,000 deaths. Avoiding person-to-person transmission is an effective approach to control and prevent the epidemic. However, many daily activities, such as logistics transporting goods in our daily life, inevitably involve person-to-person contact. To achieve contact-less goods transportation, using an autonomous logistic vehicle has become the preferred choice. This article presents Hercules, an autonomous logistic vehicle used for contact-less goods transportation during the outbreak of COVID-19. The vehicle is designed with autonomous navigation capability. We provide details on the hardware and software, as well as the algorithms to achieve autonomous navigation including perception, planning and control. This paper is accompanied by a demonstration video and a dataset, which are available here: https://sites.google.com/view/contact-less-transportation.