 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
Learning better representations for crowded pedestrians in offboard LiDAR-camera 3D tracking-by-detection
May 21, 2025Perceiving pedestrians in highly crowded urban environments is a difficult long-tail problem for learning-based autonomous perception. Speeding up 3D ground truth generation for such challenging scenes is performance-critical yet very challenging. The difficulties include the sparsity of the captured pedestrian point cloud and a lack of suitable benchmarks for a specific system design study. To tackle the challenges, we first collect a new multi-view LiDAR-camera 3D multiple-object-tracking benchmark of highly crowded pedestrians for in-depth analysis. We then build an offboard auto-labeling system that reconstructs pedestrian trajectories from LiDAR point cloud and multi-view images. To improve the generalization power for crowded scenes and the performance for small objects, we propose to learn high-resolution representations that are density-aware and relationship-aware. Extensive experiments validate that our approach significantly improves the 3D pedestrian tracking performance towards higher auto-labeling efficiency. The code will be publicly available at this HTTP URL.
Generative Artificial Intelligence in Robotic Manipulation: A Survey
Mar 05, 2025



This survey provides a comprehensive review on recent advancements of generative learning models in robotic manipulation, addressing key challenges in the field. Robotic manipulation faces critical bottlenecks, including significant challenges in insufficient data and inefficient data acquisition, long-horizon and complex task planning, and the multi-modality reasoning ability for robust policy learning performance across diverse environments. To tackle these challenges, this survey introduces several generative model paradigms, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, probabilistic flow models, and autoregressive models, highlighting their strengths and limitations. The applications of these models are categorized into three hierarchical layers: the Foundation Layer, focusing on data generation and reward generation; the Intermediate Layer, covering language, code, visual, and state generation; and the Policy Layer, emphasizing grasp generation and trajectory generation. Each layer is explored in detail, along with notable works that have advanced the state of the art. Finally, the survey outlines future research directions and challenges, emphasizing the need for improved efficiency in data utilization, better handling of long-horizon tasks, and enhanced generalization across diverse robotic scenarios. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/GAI4Manipulation/AwesomeGAIManipulation
HAPNet: Toward Superior RGB-Thermal Scene Parsing via Hybrid, Asymmetric, and Progressive Heterogeneous Feature Fusion
Apr 06, 2024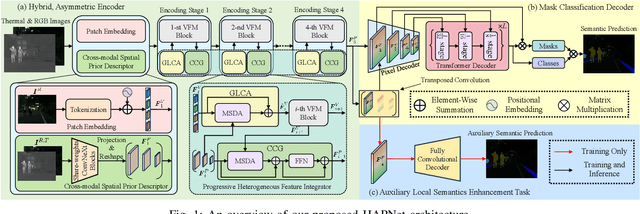



Data-fusion networks have shown significant promise for RGB-thermal scene parsing. However, the majority of existing studies have relied on symmetric duplex encoders for heterogeneous feature extraction and fusion, paying inadequate attention to the inherent differences between RGB and thermal modalities. Recent progress in vision foundation models (VFMs) trained through self-supervision on vast amounts of unlabeled data has proven their ability to extract informative, general-purpose features. However, this potential has yet to be fully leveraged in the domain. In this study, we take one step toward this new research area by exploring a feasible strategy to fully exploit VFM features for RGB-thermal scene parsing. Specifically, we delve deeper into the unique characteristics of RGB and thermal modalities, thereby designing a hybrid, asymmetric encoder that incorporates both a VFM and a convolutional neural network. This design allows for more effective extraction of complementary heterogeneous features, which are subsequently fused in a dual-path, progressive manner. Moreover, we introduce an auxiliary task to further enrich the local semantics of the fused features, thereby improving the overall performance of RGB-thermal scene parsing. Our proposed HAPNet, equipped with all these components, demonstrates superior performance compared to all other state-of-the-art RGB-thermal scene parsing networks, achieving top ranks across three widely used public RGB-thermal scene parsing datasets. We believe this new paradigm has opened up new opportunities for future developments in data-fusion scene parsing approaches.
RoadFormer: Duplex Transformer for RGB-Normal Semantic Road Scene Parsing
Sep 19, 2023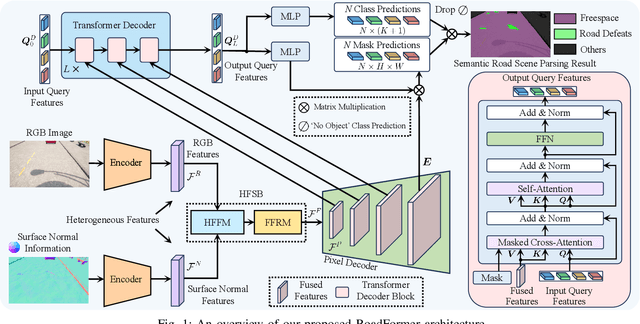
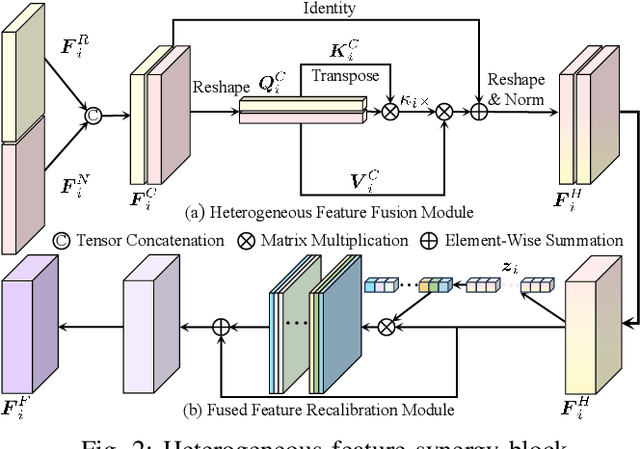
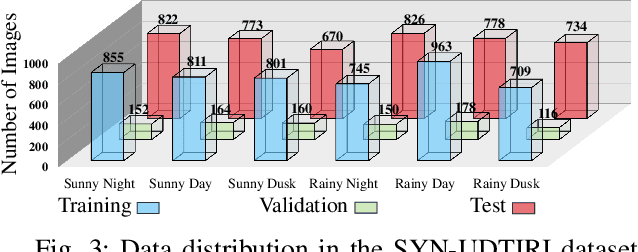

The recent advancements in deep convolutional neural networks have shown significant promise in the domain of road scene parsing. Nevertheless, the existing works focus primarily on freespace detection, with little attention given to hazardous road defects that could compromise both driving safety and comfort. In this paper, we introduce RoadFormer, a novel Transformer-based data-fusion network developed for road scene parsing. RoadFormer utilizes a duplex encoder architecture to extract heterogeneous features from both RGB images and surface normal information. The encoded features are subsequently fed into a novel heterogeneous feature synergy block for effective feature fusion and recalibration. The pixel decoder then learns multi-scale long-range dependencies from the fused and recalibrated heterogeneous features, which are subsequently processed by a Transformer decoder to produce the final semantic prediction. Additionally, we release SYN-UDTIRI, the first large-scale road scene parsing dataset that contains over 10,407 RGB images, dense depth images, and the corresponding pixel-level annotations for both freespace and road defects of different shapes and sizes. Extensive experimental evaluations conducted on our SYN-UDTIRI dataset, as well as on three public datasets, including KITTI road, CityScapes, and ORFD, demonstrate that RoadFormer outperforms all other state-of-the-art networks for road scene parsing. Specifically, RoadFormer ranks first on the KITTI road benchmark. Our source code, created dataset, and demo video are publicly available at mias.group/RoadFormer.
Open-world Semantic Segmentation for LIDAR Point Clouds
Jul 04, 2022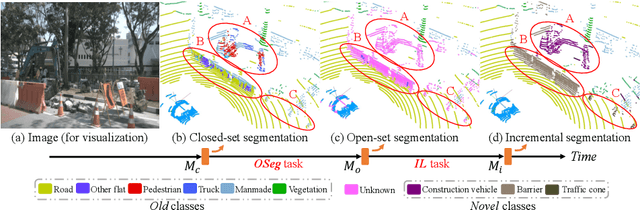
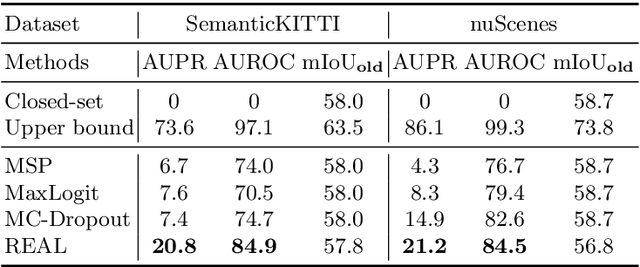
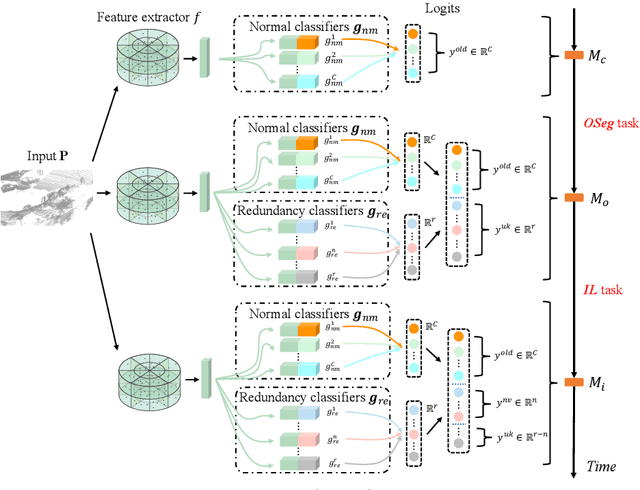

Current methods for LIDAR semantic segmentation are not robust enough for real-world applications, e.g., autonomous driving, since it is closed-set and static. The closed-set assumption makes the network only able to output labels of trained classes, even for objects never seen before, while a static network cannot update its knowledge base according to what it has seen. Therefore, in this work, we propose the open-world semantic segmentation task for LIDAR point clouds, which aims to 1) identify both old and novel classes using open-set semantic segmentation, and 2) gradually incorporate novel objects into the existing knowledge base using incremental learning without forgetting old classes. For this purpose, we propose a REdundAncy cLassifier (REAL) framework to provide a general architecture for both the open-set semantic segmentation and incremental learning problems. The experimental results show that REAL can simultaneously achieves state-of-the-art performance in the open-set semantic segmentation task on the SemanticKITTI and nuScenes datasets, and alleviate the catastrophic forgetting problem with a large margin during incremental learning.
Open-set 3D Object Detection
Dec 02, 2021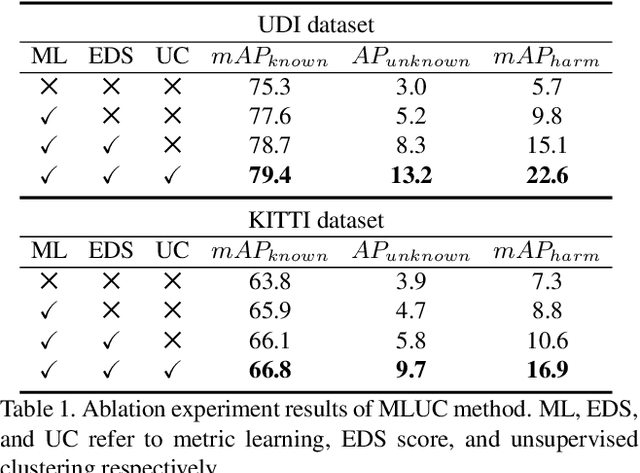
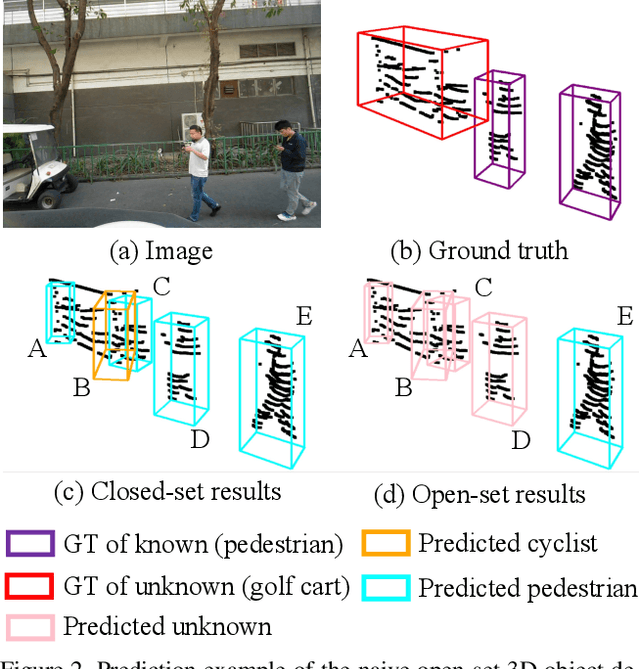
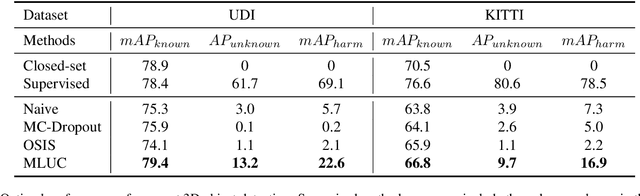
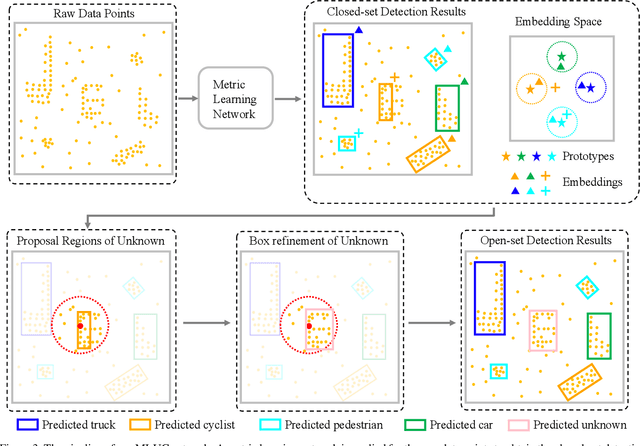
3D object detection has been wildly studied in recent years, especially for robot perception systems. However, existing 3D object detection is under a closed-set condition, meaning that the network can only output boxes of trained classes. Unfortunately, this closed-set condition is not robust enough for practical use, as it will identify unknown objects as known by mistake. Therefore, in this paper, we propose an open-set 3D object detector, which aims to (1) identify known objects, like the closed-set detection, and (2) identify unknown objects and give their accurate bounding boxes. Specifically, we divide the open-set 3D object detection problem into two steps: (1) finding out the regions containing the unknown objects with high probability and (2) enclosing the points of these regions with proper bounding boxes. The first step is solved by the finding that unknown objects are often classified as known objects with low confidence, and we show that the Euclidean distance sum based on metric learning is a better confidence score than the naive softmax probability to differentiate unknown objects from known objects. On this basis, unsupervised clustering is used to refine the bounding boxes of unknown objects. The proposed method combining metric learning and unsupervised clustering is called the MLUC network. Our experiments show that our MLUC network achieves state-of-the-art performance and can identify both known and unknown objects as expected.
Deep Metric Learning for Open World Semantic Segmentation
Aug 10, 2021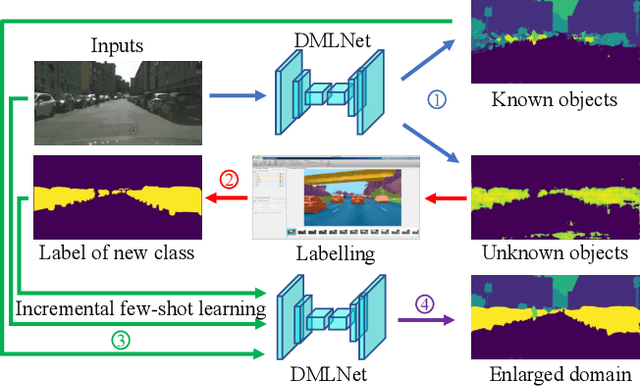
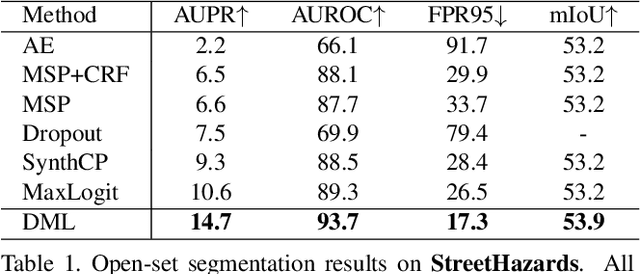
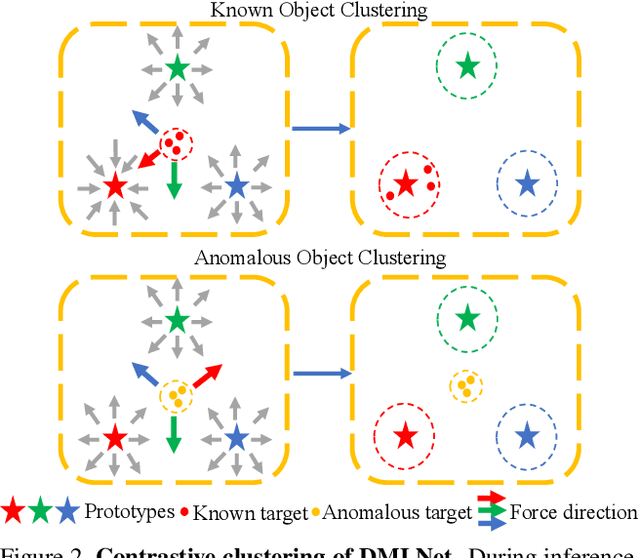
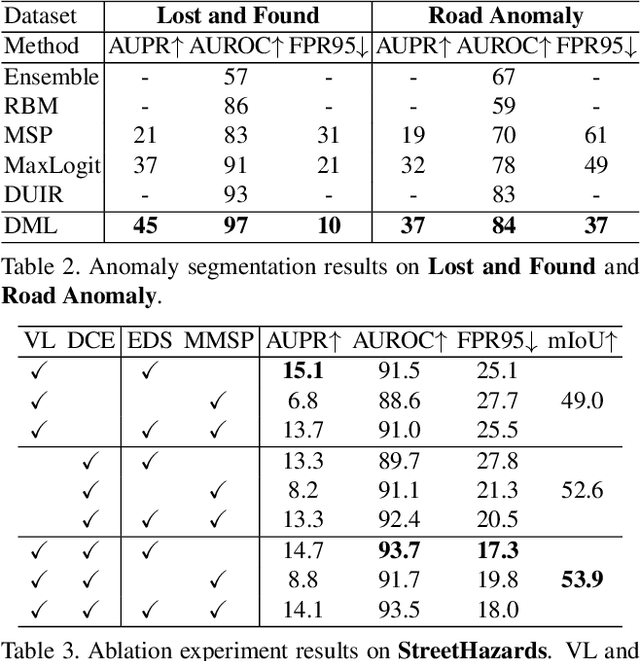
Classical close-set semantic segmentation networks have limited ability to detect out-of-distribution (OOD) objects, which is important for safety-critical applications such as autonomous driving. Incrementally learning these OOD objects with few annotations is an ideal way to enlarge the knowledge base of the deep learning models. In this paper, we propose an open world semantic segmentation system that includes two modules: (1) an open-set semantic segmentation module to detect both in-distribution and OOD objects. (2) an incremental few-shot learning module to gradually incorporate those OOD objects into its existing knowledge base. This open world semantic segmentation system behaves like a human being, which is able to identify OOD objects and gradually learn them with corresponding supervision. We adopt the Deep Metric Learning Network (DMLNet) with contrastive clustering to implement open-set semantic segmentation. Compared to other open-set semantic segmentation methods, our DMLNet achieves state-of-the-art performance on three challenging open-set semantic segmentation datasets without using additional data or generative models. On this basis, two incremental few-shot learning methods are further proposed to progressively improve the DMLNet with the annotations of OOD objects.
Greedy-Based Feature Selection for Efficient LiDAR SLAM
Mar 24, 2021
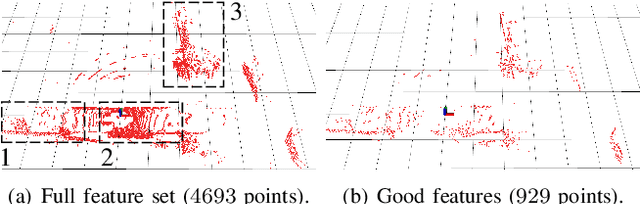
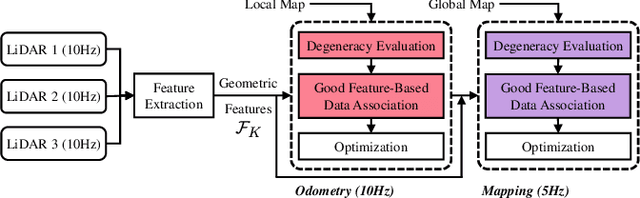
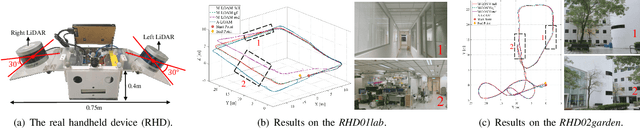
Modern LiDAR-SLAM (L-SLAM) systems have shown excellent results in large-scale, real-world scenarios. However, they commonly have a high latency due to the expensive data association and nonlinear optimization. This paper demonstrates that actively selecting a subset of features significantly improves both the accuracy and efficiency of an L-SLAM system. We formulate the feature selection as a combinatorial optimization problem under a cardinality constraint to preserve the information matrix's spectral attributes. The stochastic-greedy algorithm is applied to approximate the optimal results in real-time. To avoid ill-conditioned estimation, we also propose a general strategy to evaluate the environment's degeneracy and modify the feature number online. The proposed feature selector is integrated into a multi-LiDAR SLAM system. We validate this enhanced system with extensive experiments covering various scenarios on two sensor setups and computation platforms. We show that our approach exhibits low localization error and speedup compared to the state-of-the-art L-SLAM systems. To benefit the community, we have released the source code: https://ram-lab.com/file/site/m-loam.
Smart-Inspect: Micro Scale Localization and Classification of Smartphone Glass Defects for Industrial Automation
Oct 02, 2020
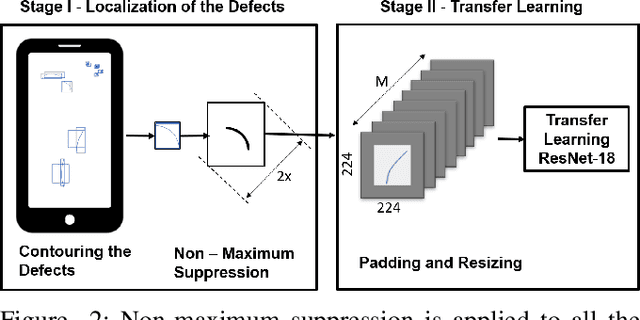
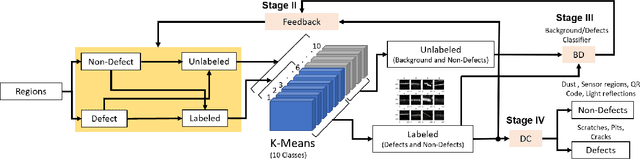

The presence of any type of defect on the glass screen of smart devices has a great impact on their quality. We present a robust semi-supervised learning framework for intelligent micro-scaled localization and classification of defects on a 16K pixel image of smartphone glass. Our model features the efficient recognition and labeling of three types of defects: scratches, light leakage due to cracks, and pits. Our method also differentiates between the defects and light reflections due to dust particles and sensor regions, which are classified as non-defect areas. We use a partially labeled dataset to achieve high robustness and excellent classification of defect and non-defect areas as compared to principal components analysis (PCA), multi-resolution and information-fusion-based algorithms. In addition, we incorporated two classifiers at different stages of our inspection framework for labeling and refining the unlabeled defects. We successfully enhanced the inspection depth-limit up to 5 microns. The experimental results show that our method outperforms manual inspection in testing the quality of glass screen samples by identifying defects on samples that have been marked as good by human inspection.