 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: A Dataset for Multi-Granularity Human Procedural Action Understanding in Industrial Assembly
Apr 12, 2026We introduce IMPACT, a synchronized five-view RGB-D dataset for deployment-oriented industrial procedural understanding, built around real assembly and disassembly of a commercial angle grinder with professional-grade tools. To our knowledge, IMPACT is the first real industrial assembly benchmark that jointly provides synchronized ego-exo RGB-D capture, decoupled bimanual annotation, compliance-aware state tracking, and explicit anomaly--recovery supervision within a single real industrial workflow. It comprises 112 trials from 13 participants totaling 39.5 hours, with multi-route execution governed by a partial-order prerequisite graph, a six-category anomaly taxonomy, and operator cognitive load measured via NASA-TLX. The annotation hierarchy links hand-specific atomic actions to coarse procedural steps, component assembly states, and per-hand compliance phases, with synchronized null spans across views to decouple perceptual limitations from algorithmic failure. Systematic baselines reveal fundamental limitations that remain invisible to single-task benchmarks, particularly under realistic deployment conditions that involve incomplete observations, flexible execution paths, and corrective behavior. The full dataset, annotations, and evaluation code are available at https://github.com/Kratos-Wen/IMPACT.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
A data-driven approach to linking design features with manufacturing process data for sustainable product development
Dec 10, 2025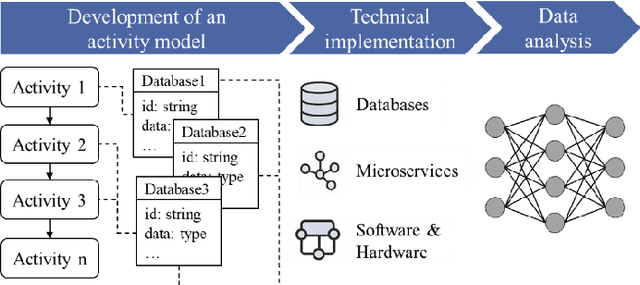
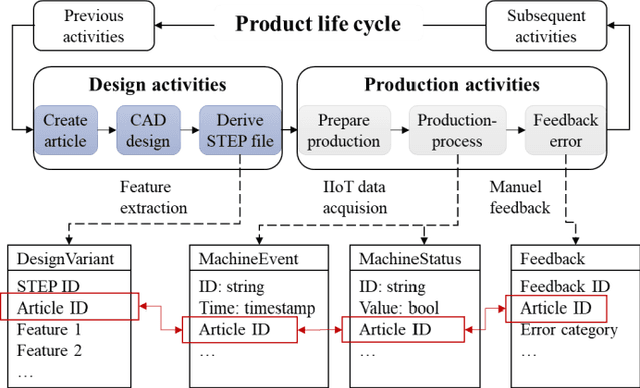
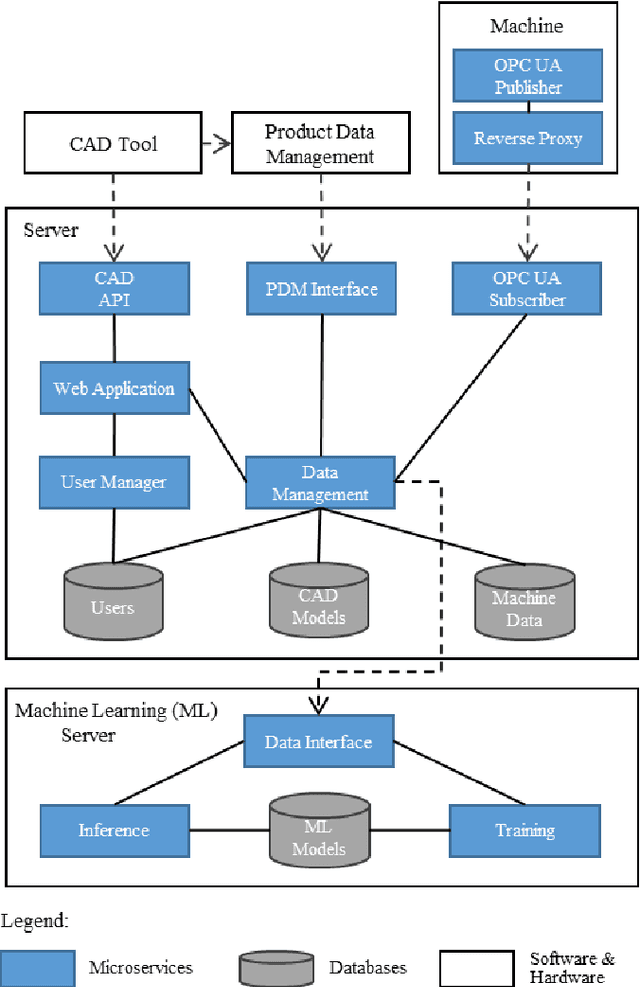
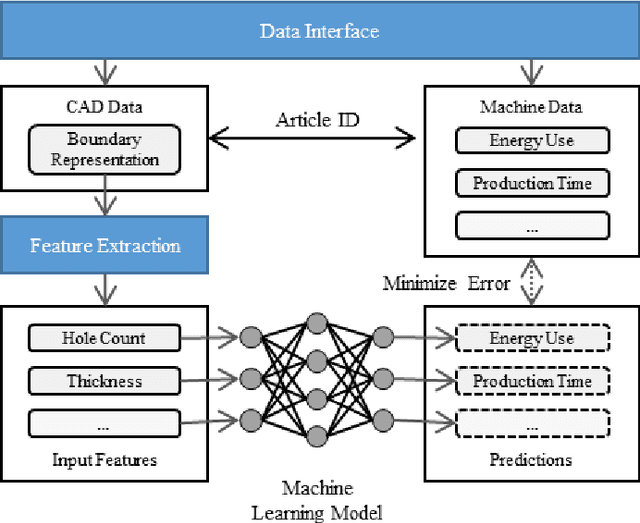
The growing adoption of Industrial Internet of Things (IIoT) technologies enables automated, real-time collection of manufacturing process data, unlocking new opportunities for data-driven product development. Current data-driven methods are generally applied within specific domains, such as design or manufacturing, with limited exploration of integrating design features and manufacturing process data. Since design decisions significantly affect manufacturing outcomes, such as error rates, energy consumption, and processing times, the lack of such integration restricts the potential for data-driven product design improvements. This paper presents a data-driven approach to mapping and analyzing the relationship between design features and manufacturing process data. A comprehensive system architecture is developed to ensure continuous data collection and integration. The linkage between design features and manufacturing process data serves as the basis for developing a machine learning model that enables automated design improvement suggestions. By integrating manufacturing process data with sustainability metrics, this approach opens new possibilities for sustainable product development.
DepthMatch: Semi-Supervised RGB-D Scene Parsing through Depth-Guided Regularization
May 26, 2025RGB-D scene parsing methods effectively capture both semantic and geometric features of the environment, demonstrating great potential under challenging conditions such as extreme weather and low lighting. However, existing RGB-D scene parsing methods predominantly rely on supervised training strategies, which require a large amount of manually annotated pixel-level labels that are both time-consuming and costly. To overcome these limitations, we introduce DepthMatch, a semi-supervised learning framework that is specifically designed for RGB-D scene parsing. To make full use of unlabeled data, we propose complementary patch mix-up augmentation to explore the latent relationships between texture and spatial features in RGB-D image pairs. We also design a lightweight spatial prior injector to replace traditional complex fusion modules, improving the efficiency of heterogeneous feature fusion. Furthermore, we introduce depth-guided boundary loss to enhance the model's boundary prediction capabilities. Experimental results demonstrate that DepthMatch exhibits high applicability in both indoor and outdoor scenes, achieving state-of-the-art results on the NYUv2 dataset and ranking first on the KITTI Semantics benchmark.
Gaze-Guided Learning: Avoiding Shortcut Bias in Visual Classification
Apr 08, 2025



Inspired by human visual attention, deep neural networks have widely adopted attention mechanisms to learn locally discriminative attributes for challenging visual classification tasks. However, existing approaches primarily emphasize the representation of such features while neglecting their precise localization, which often leads to misclassification caused by shortcut biases. This limitation becomes even more pronounced when models are evaluated on transfer or out-of-distribution datasets. In contrast, humans are capable of leveraging prior object knowledge to quickly localize and compare fine-grained attributes, a capability that is especially crucial in complex and high-variance classification scenarios. Motivated by this, we introduce Gaze-CIFAR-10, a human gaze time-series dataset, along with a dual-sequence gaze encoder that models the precise sequential localization of human attention on distinct local attributes. In parallel, a Vision Transformer (ViT) is employed to learn the sequential representation of image content. Through cross-modal fusion, our framework integrates human gaze priors with machine-derived visual sequences, effectively correcting inaccurate localization in image feature representations. Extensive qualitative and quantitative experiments demonstrate that gaze-guided cognitive cues significantly enhance classification accuracy.
Establishing Reality-Virtuality Interconnections in Urban Digital Twins for Superior Intelligent Road Inspection
Dec 23, 2024



Road inspection is essential for ensuring road maintenance and traffic safety, as road defects gradually emerge and compromise road functionality. Traditional methods, which rely on manual evaluations, are labor-intensive, costly, and time-consuming. Although data-driven approaches are gaining traction, the scarcity and spatial sparsity of road defects in the real world pose significant challenges in acquiring high-quality datasets. Existing simulators designed to generate detailed synthetic driving scenes, however, lack models for road defects. Furthermore, advanced driving tasks involving interactions with road surfaces, such as planning and control in defective areas, remain underexplored. To address these limitations, we propose a system based on Urban Digital Twin (UDT) technology for intelligent road inspection. First, hierarchical road models are constructed from real-world driving data, creating highly detailed representations of road defect structures and surface elevations. Next, digital road twins are generated to create simulation environments for comprehensive analysis and evaluation. These scenarios are subsequently imported into a simulator to enable both data acquisition and physical simulation. Experimental results demonstrate that driving tasks, including perception and decision-making, can be significantly improved using the high-fidelity road defect scenes generated by our system.
@Bench: Benchmarking Vision-Language Models for Human-centered Assistive Technology
Sep 21, 2024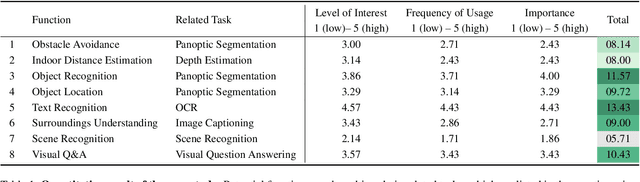
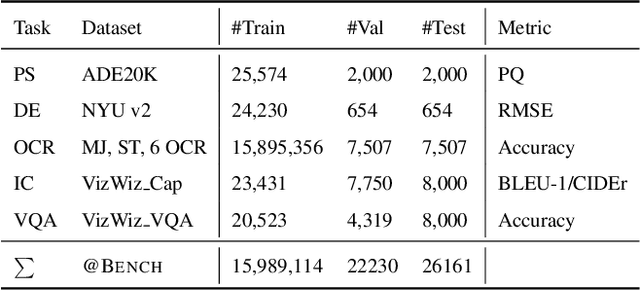
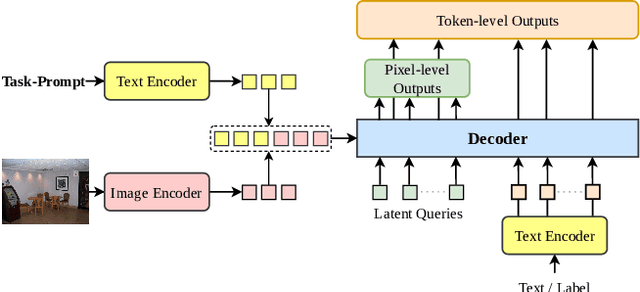
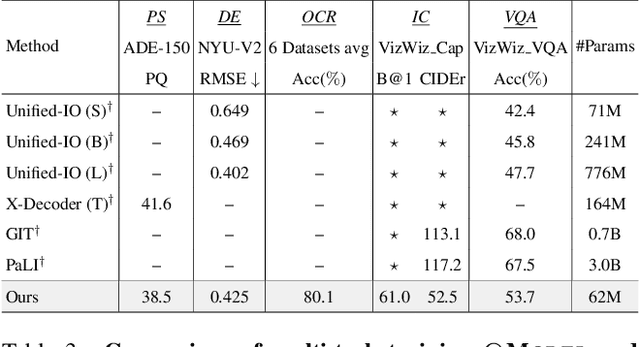
As Vision-Language Models (VLMs) advance, human-centered Assistive Technologies (ATs) for helping People with Visual Impairments (PVIs) are evolving into generalists, capable of performing multiple tasks simultaneously. However, benchmarking VLMs for ATs remains under-explored. To bridge this gap, we first create a novel AT benchmark (@Bench). Guided by a pre-design user study with PVIs, our benchmark includes the five most crucial vision-language tasks: Panoptic Segmentation, Depth Estimation, Optical Character Recognition (OCR), Image Captioning, and Visual Question Answering (VQA). Besides, we propose a novel AT model (@Model) that addresses all tasks simultaneously and can be expanded to more assistive functions for helping PVIs. Our framework exhibits outstanding performance across tasks by integrating multi-modal information, and it offers PVIs a more comprehensive assistance. Extensive experiments prove the effectiveness and generalizability of our framework.
RoadFormer+: Delivering RGB-X Scene Parsing through Scale-Aware Information Decoupling and Advanced Heterogeneous Feature Fusion
Jul 31, 2024



Task-specific data-fusion networks have marked considerable achievements in urban scene parsing. Among these networks, our recently proposed RoadFormer successfully extracts heterogeneous features from RGB images and surface normal maps and fuses these features through attention mechanisms, demonstrating compelling efficacy in RGB-Normal road scene parsing. However, its performance significantly deteriorates when handling other types/sources of data or performing more universal, all-category scene parsing tasks. To overcome these limitations, this study introduces RoadFormer+, an efficient, robust, and adaptable model capable of effectively fusing RGB-X data, where ``X'', represents additional types/modalities of data such as depth, thermal, surface normal, and polarization. Specifically, we propose a novel hybrid feature decoupling encoder to extract heterogeneous features and decouple them into global and local components. These decoupled features are then fused through a dual-branch multi-scale heterogeneous feature fusion block, which employs parallel Transformer attentions and convolutional neural network modules to merge multi-scale features across different scales and receptive fields. The fused features are subsequently fed into a decoder to generate the final semantic predictions. Notably, our proposed RoadFormer+ ranks first on the KITTI Road benchmark and achieves state-of-the-art performance in mean intersection over union on the Cityscapes, MFNet, FMB, and ZJU datasets. Moreover, it reduces the number of learnable parameters by 65\% compared to RoadFormer. Our source code will be publicly available at mias.group/RoadFormerPlus.
Enhanced Geological Prediction for Tunnel Excavation Using Full Waveform Inversion Integrating Sobolev Space Regularization with a Quadratic Penalty Method
May 27, 2024



In the process of tunnel excavation, advanced geological prediction technology has become indispensable for safe, economical, and efficient tunnel construction. Although traditional methods such as drilling and geological analysis are effective, they typically involve destructive processes, carry high risks, and incur significant costs. In contrast, non-destructive geophysical exploration offers a more convenient and economical alternative. However, the accuracy and precision of these non-destructive methods can be severely compromised by complex geological structures and environmental noise. To address these challenges effectively, a novel approach using frequency domain full waveform inversion (FWI), based on a penalty method and Sobolev space regularization, has been proposed to enhance the performance of non-destructive predictions. The proposed method constructs a soft-constrained optimization problem by restructuring the misfit function into a combination of data misfit and wave equation drive terms to enhance convexity. Additionally, it semi-extends the search space to both the wavefield and the model parameters to mitigate the strong nonlinearity of the optimization, facilitating high-resolution inversion. Furthermore, a Sobolev space regularization algorithm is introduced to flexibly adjust the regularization path, addressing issues related to noise and artefacts to improve the robustness of the inversion. We evaluated the proposed FWI with a tunnel fault model by comparing the results of the proposed method with those of traditional Tikhonov regularization and total variation regularization FWI methods. The results confirm the superior performance of the proposed algorithm as expected.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024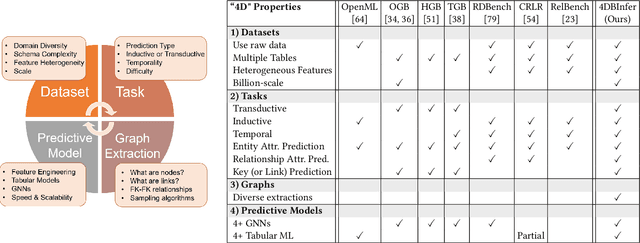
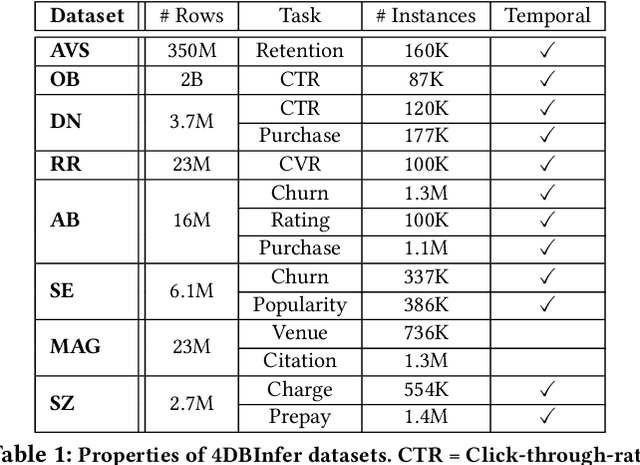
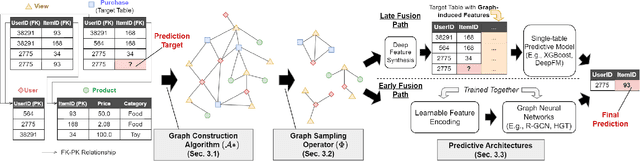
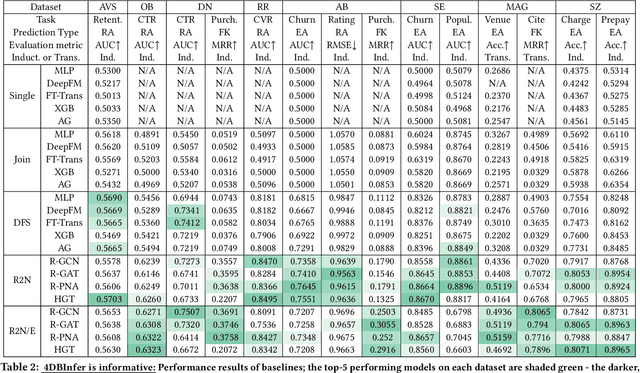
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .