 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Exploiting Vision Foundation Model's Profound Prior Knowledge for Generalizable RGB-Depth Driving Scene Parsing
Feb 10, 2025



Recent vision foundation models (VFMs), typically based on Vision Transformer (ViT), have significantly advanced numerous computer vision tasks. Despite their success in tasks focused solely on RGB images, the potential of VFMs in RGB-depth driving scene parsing remains largely under-explored. In this article, we take one step toward this emerging research area by investigating a feasible technique to fully exploit VFMs for generalizable RGB-depth driving scene parsing. Specifically, we explore the inherent characteristics of RGB and depth data, thereby presenting a Heterogeneous Feature Integration Transformer (HFIT). This network enables the efficient extraction and integration of comprehensive heterogeneous features without re-training ViTs. Relative depth prediction results from VFMs, used as inputs to the HFIT side adapter, overcome the limitations of the dependence on depth maps. Our proposed HFIT demonstrates superior performance compared to all other traditional single-modal and data-fusion scene parsing networks, pre-trained VFMs, and ViT adapters on the Cityscapes and KITTI Semantics datasets. We believe this novel strategy paves the way for future innovations in VFM-based data-fusion techniques for driving scene parsing. Our source code is publicly available at https://mias.group/HFIT.
Establishing Reality-Virtuality Interconnections in Urban Digital Twins for Superior Intelligent Road Inspection
Dec 23, 2024



Road inspection is essential for ensuring road maintenance and traffic safety, as road defects gradually emerge and compromise road functionality. Traditional methods, which rely on manual evaluations, are labor-intensive, costly, and time-consuming. Although data-driven approaches are gaining traction, the scarcity and spatial sparsity of road defects in the real world pose significant challenges in acquiring high-quality datasets. Existing simulators designed to generate detailed synthetic driving scenes, however, lack models for road defects. Furthermore, advanced driving tasks involving interactions with road surfaces, such as planning and control in defective areas, remain underexplored. To address these limitations, we propose a system based on Urban Digital Twin (UDT) technology for intelligent road inspection. First, hierarchical road models are constructed from real-world driving data, creating highly detailed representations of road defect structures and surface elevations. Next, digital road twins are generated to create simulation environments for comprehensive analysis and evaluation. These scenarios are subsequently imported into a simulator to enable both data acquisition and physical simulation. Experimental results demonstrate that driving tasks, including perception and decision-making, can be significantly improved using the high-fidelity road defect scenes generated by our system.
These Maps Are Made by Propagation: Adapting Deep Stereo Networks to Road Scenarios with Decisive Disparity Diffusion
Nov 06, 2024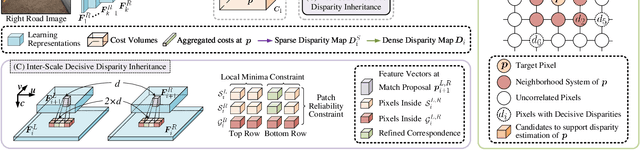
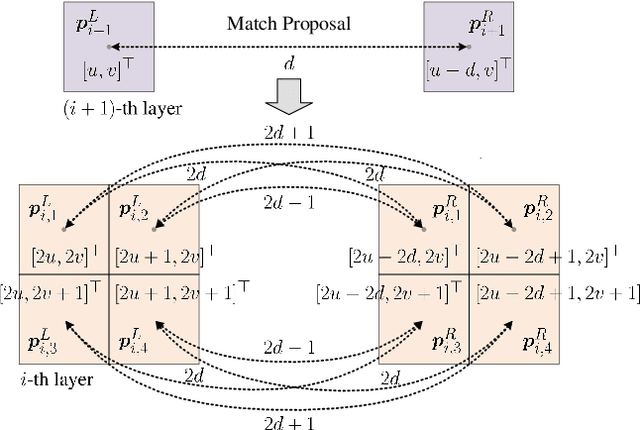
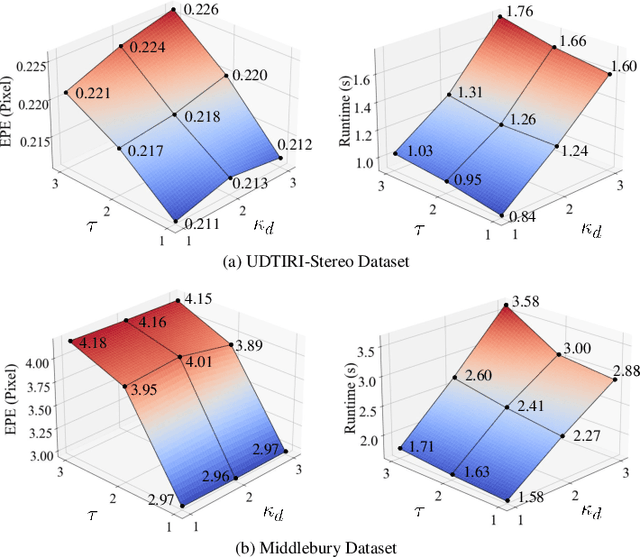
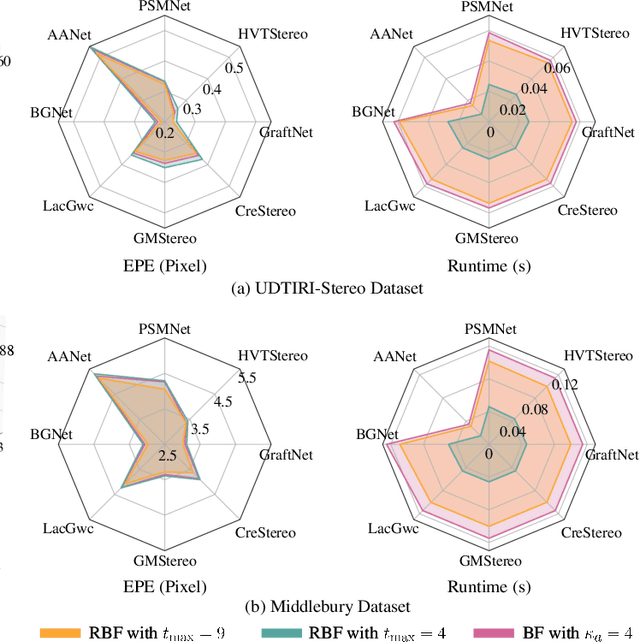
Stereo matching has emerged as a cost-effective solution for road surface 3D reconstruction, garnering significant attention towards improving both computational efficiency and accuracy. This article introduces decisive disparity diffusion (D3Stereo), marking the first exploration of dense deep feature matching that adapts pre-trained deep convolutional neural networks (DCNNs) to previously unseen road scenarios. A pyramid of cost volumes is initially created using various levels of learned representations. Subsequently, a novel recursive bilateral filtering algorithm is employed to aggregate these costs. A key innovation of D3Stereo lies in its alternating decisive disparity diffusion strategy, wherein intra-scale diffusion is employed to complete sparse disparity images, while inter-scale inheritance provides valuable prior information for higher resolutions. Extensive experiments conducted on our created UDTIRI-Stereo and Stereo-Road datasets underscore the effectiveness of D3Stereo strategy in adapting pre-trained DCNNs and its superior performance compared to all other explicit programming-based algorithms designed specifically for road surface 3D reconstruction. Additional experiments conducted on the Middlebury dataset with backbone DCNNs pre-trained on the ImageNet database further validate the versatility of D3Stereo strategy in tackling general stereo matching problems.
Playing to Vision Foundation Model's Strengths in Stereo Matching
Apr 09, 2024



Stereo matching has become a key technique for 3D environment perception in intelligent vehicles. For a considerable time, convolutional neural networks (CNNs) have remained the mainstream choice for feature extraction in this domain. Nonetheless, there is a growing consensus that the existing paradigm should evolve towards vision foundation models (VFM), particularly those developed based on vision Transformers (ViTs) and pre-trained through self-supervision on extensive, unlabeled datasets. While VFMs are adept at extracting informative, general-purpose visual features, specifically for dense prediction tasks, their performance often lacks in geometric vision tasks. This study serves as the first exploration of a viable approach for adapting VFMs to stereo matching. Our ViT adapter, referred to as ViTAS, is constructed upon three types of modules: spatial differentiation, patch attention fusion, and cross-attention. The first module initializes feature pyramids, while the latter two aggregate stereo and multi-scale contextual information into fine-grained features, respectively. ViTAStereo, which combines ViTAS with cost volume-based stereo matching back-end processes, achieves the top rank on the KITTI Stereo 2012 dataset and outperforms the second-best network StereoBase by approximately 7.9% in terms of the percentage of error pixels, with a tolerance of 3 pixels. Additional experiments across diverse scenarios further demonstrate its superior generalizability compared to all other state-of-the-art approaches. We believe this new paradigm will pave the way for the next generation of stereo matching networks.
S$^3$M-Net: Joint Learning of Semantic Segmentation and Stereo Matching for Autonomous Driving
Jan 29, 2024Semantic segmentation and stereo matching are two essential components of 3D environmental perception systems for autonomous driving. Nevertheless, conventional approaches often address these two problems independently, employing separate models for each task. This approach poses practical limitations in real-world scenarios, particularly when computational resources are scarce or real-time performance is imperative. Hence, in this article, we introduce S$^3$M-Net, a novel joint learning framework developed to perform semantic segmentation and stereo matching simultaneously. Specifically, S$^3$M-Net shares the features extracted from RGB images between both tasks, resulting in an improved overall scene understanding capability. This feature sharing process is realized using a feature fusion adaption (FFA) module, which effectively transforms the shared features into semantic space and subsequently fuses them with the encoded disparity features. The entire joint learning framework is trained by minimizing a novel semantic consistency-guided (SCG) loss, which places emphasis on the structural consistency in both tasks. Extensive experimental results conducted on the vKITTI2 and KITTI datasets demonstrate the effectiveness of our proposed joint learning framework and its superior performance compared to other state-of-the-art single-task networks. Our project webpage is accessible at mias.group/S3M-Net.