 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniForce: A Unified Latent Force Model for Robot Manipulation with Diverse Tactile Sensors
Feb 01, 2026Force sensing is essential for dexterous robot manipulation, but scaling force-aware policy learning is hindered by the heterogeneity of tactile sensors. Differences in sensing principles (e.g., optical vs. magnetic), form factors, and materials typically require sensor-specific data collection, calibration, and model training, thereby limiting generalisability. We propose UniForce, a novel unified tactile representation learning framework that learns a shared latent force space across diverse tactile sensors. UniForce reduces cross-sensor domain shift by jointly modeling inverse dynamics (image-to-force) and forward dynamics (force-to-image), constrained by force equilibrium and image reconstruction losses to produce force-grounded representations. To avoid reliance on expensive external force/torque (F/T) sensors, we exploit static equilibrium and collect force-paired data via direct sensor--object--sensor interactions, enabling cross-sensor alignment with contact force. The resulting universal tactile encoder can be plugged into downstream force-aware robot manipulation tasks with zero-shot transfer, without retraining or finetuning. Extensive experiments on heterogeneous tactile sensors including GelSight, TacTip, and uSkin, demonstrate consistent improvements in force estimation over prior methods, and enable effective cross-sensor coordination in Vision-Tactile-Language-Action (VTLA) models for a robotic wiping task. Code and datasets will be released.
UniMorphGrasp: Diffusion Model with Morphology-Awareness for Cross-Embodiment Dexterous Grasp Generation
Jan 31, 2026Cross-embodiment dexterous grasping aims to generate stable and diverse grasps for robotic hands with heterogeneous kinematic structures. Existing methods are often tailored to specific hand designs and fail to generalize to unseen hand morphologies outside the training distribution. To address these limitations, we propose \textbf{UniMorphGrasp}, a diffusion-based framework that incorporates hand morphological information into the grasp generation process for unified cross-embodiment grasp synthesis. The proposed approach maps grasps from diverse robotic hands into a unified human-like canonical hand pose representation, providing a common space for learning. Grasp generation is then conditioned on structured representations of hand kinematics, encoded as graphs derived from hand configurations, together with object geometry. In addition, a loss function is introduced that exploits the hierarchical organization of hand kinematics to guide joint-level supervision. Extensive experiments demonstrate that UniMorphGrasp achieves state-of-the-art performance on existing dexterous grasp benchmarks and exhibits strong zero-shot generalization to previously unseen hand structures, enabling scalable and practical cross-embodiment grasp deployment.
ViTacGen: Robotic Pushing with Vision-to-Touch Generation
Oct 15, 2025Robotic pushing is a fundamental manipulation task that requires tactile feedback to capture subtle contact forces and dynamics between the end-effector and the object. However, real tactile sensors often face hardware limitations such as high costs and fragility, and deployment challenges involving calibration and variations between different sensors, while vision-only policies struggle with satisfactory performance. Inspired by humans' ability to infer tactile states from vision, we propose ViTacGen, a novel robot manipulation framework designed for visual robotic pushing with vision-to-touch generation in reinforcement learning to eliminate the reliance on high-resolution real tactile sensors, enabling effective zero-shot deployment on visual-only robotic systems. Specifically, ViTacGen consists of an encoder-decoder vision-to-touch generation network that generates contact depth images, a standardized tactile representation, directly from visual image sequence, followed by a reinforcement learning policy that fuses visual-tactile data with contrastive learning based on visual and generated tactile observations. We validate the effectiveness of our approach in both simulation and real world experiments, demonstrating its superior performance and achieving a success rate of up to 86\%.
ConViTac: Aligning Visual-Tactile Fusion with Contrastive Representations
Jun 25, 2025Vision and touch are two fundamental sensory modalities for robots, offering complementary information that enhances perception and manipulation tasks. Previous research has attempted to jointly learn visual-tactile representations to extract more meaningful information. However, these approaches often rely on direct combination, such as feature addition and concatenation, for modality fusion, which tend to result in poor feature integration. In this paper, we propose ConViTac, a visual-tactile representation learning network designed to enhance the alignment of features during fusion using contrastive representations. Our key contribution is a Contrastive Embedding Conditioning (CEC) mechanism that leverages a contrastive encoder pretrained through self-supervised contrastive learning to project visual and tactile inputs into unified latent embeddings. These embeddings are used to couple visual-tactile feature fusion through cross-modal attention, aiming at aligning the unified representations and enhancing performance on downstream tasks. We conduct extensive experiments to demonstrate the superiority of ConViTac in real world over current state-of-the-art methods and the effectiveness of our proposed CEC mechanism, which improves accuracy by up to 12.0% in material classification and grasping prediction tasks.
FNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025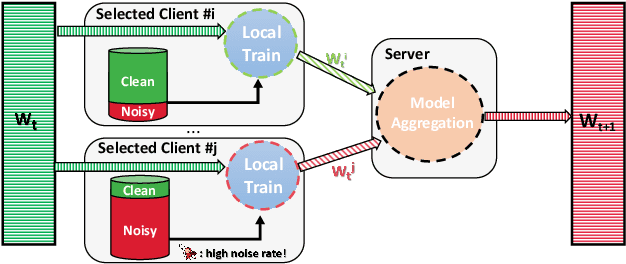
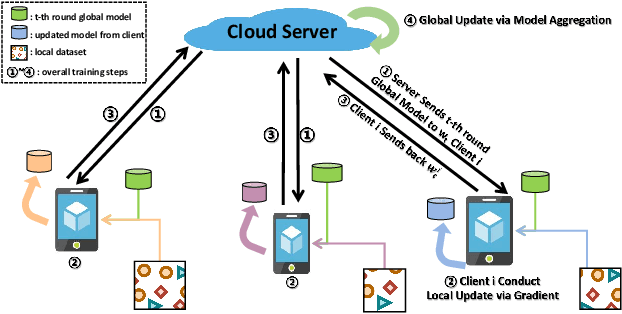
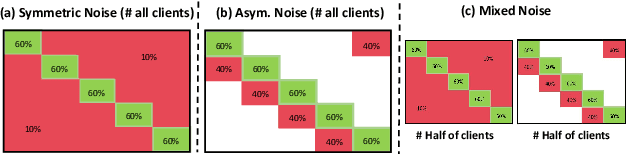
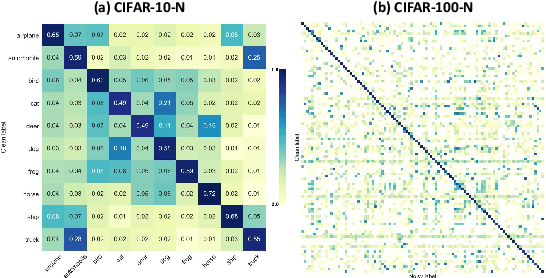
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
General Force Sensation for Tactile Robot
Mar 02, 2025



Robotic tactile sensors, including vision-based and taxel-based sensors, enable agile manipulation and safe human-robot interaction through force sensation. However, variations in structural configurations, measured signals, and material properties create domain gaps that limit the transferability of learned force sensation across different tactile sensors. Here, we introduce GenForce, a general framework for achieving transferable force sensation across both homogeneous and heterogeneous tactile sensors in robotic systems. By unifying tactile signals into marker-based binary tactile images, GenForce enables the transfer of existing force labels to arbitrary target sensors using a marker-to-marker translation technique with a few paired data. This process equips uncalibrated tactile sensors with force prediction capabilities through spatiotemporal force prediction models trained on the transferred data. Extensive experimental results validate GenForce's generalizability, accuracy, and robustness across sensors with diverse marker patterns, structural designs, material properties, and sensing principles. The framework significantly reduces the need for costly and labor-intensive labeled data collection, enabling the rapid deployment of multiple tactile sensors on robotic hands requiring force sensing capabilities.
Addressing Label Shift in Distributed Learning via Entropy Regularization
Feb 04, 2025We address the challenge of minimizing true risk in multi-node distributed learning. These systems are frequently exposed to both inter-node and intra-node label shifts, which present a critical obstacle to effectively optimizing model performance while ensuring that data remains confined to each node. To tackle this, we propose the Versatile Robust Label Shift (VRLS) method, which enhances the maximum likelihood estimation of the test-to-train label density ratio. VRLS incorporates Shannon entropy-based regularization and adjusts the density ratio during training to better handle label shifts at the test time. In multi-node learning environments, VRLS further extends its capabilities by learning and adapting density ratios across nodes, effectively mitigating label shifts and improving overall model performance. Experiments conducted on MNIST, Fashion MNIST, and CIFAR-10 demonstrate the effectiveness of VRLS, outperforming baselines by up to 20% in imbalanced settings. These results highlight the significant improvements VRLS offers in addressing label shifts. Our theoretical analysis further supports this by establishing high-probability bounds on estimation errors.
Beyond Model Scale Limits: End-Edge-Cloud Federated Learning with Self-Rectified Knowledge Agglomeration
Jan 01, 2025



The rise of End-Edge-Cloud Collaboration (EECC) offers a promising paradigm for Artificial Intelligence (AI) model training across end devices, edge servers, and cloud data centers, providing enhanced reliability and reduced latency. Hierarchical Federated Learning (HFL) can benefit from this paradigm by enabling multi-tier model aggregation across distributed computing nodes. However, the potential of HFL is significantly constrained by the inherent heterogeneity and dynamic characteristics of EECC environments. Specifically, the uniform model structure bounded by the least powerful end device across all computing nodes imposes a performance bottleneck. Meanwhile, coupled heterogeneity in data distributions and resource capabilities across tiers disrupts hierarchical knowledge transfer, leading to biased updates and degraded performance. Furthermore, the mobility and fluctuating connectivity of computing nodes in EECC environments introduce complexities in dynamic node migration, further compromising the robustness of the training process. To address multiple challenges within a unified framework, we propose End-Edge-Cloud Federated Learning with Self-Rectified Knowledge Agglomeration (FedEEC), which is a novel EECC-empowered FL framework that allows the trained models from end, edge, to cloud to grow larger in size and stronger in generalization ability. FedEEC introduces two key innovations: (1) Bridge Sample Based Online Distillation Protocol (BSBODP), which enables knowledge transfer between neighboring nodes through generated bridge samples, and (2) Self-Knowledge Rectification (SKR), which refines the transferred knowledge to prevent suboptimal cloud model optimization. The proposed framework effectively handles both cross-tier resource heterogeneity and effective knowledge transfer between neighboring nodes, while satisfying the migration-resilient requirements of EECC.
ManiSkill-ViTac 2025: Challenge on Manipulation Skill Learning With Vision and Tactile Sensing
Nov 19, 2024This article introduces the ManiSkill-ViTac Challenge 2025, which focuses on learning contact-rich manipulation skills using both tactile and visual sensing. Expanding upon the 2024 challenge, ManiSkill-ViTac 2025 includes 3 independent tracks: tactile manipulation, tactile-vision fusion manipulation, and tactile sensor structure design. The challenge aims to push the boundaries of robotic manipulation skills, emphasizing the integration of tactile and visual data to enhance performance in complex, real-world tasks. Participants will be evaluated using standardized metrics across both simulated and real-world environments, spurring innovations in sensor design and significantly advancing the field of vision-tactile fusion in robotics.