 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025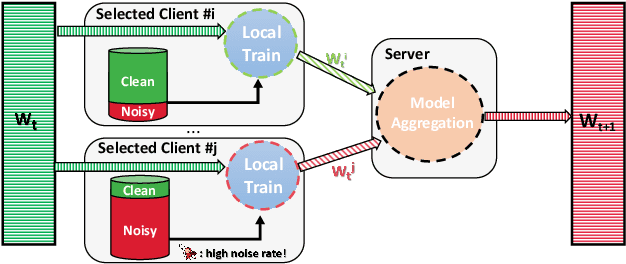
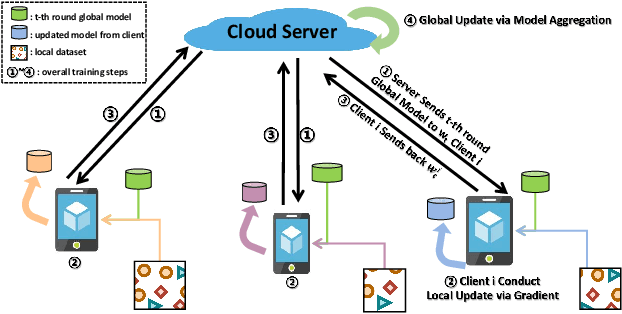
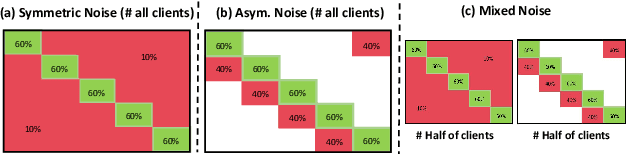
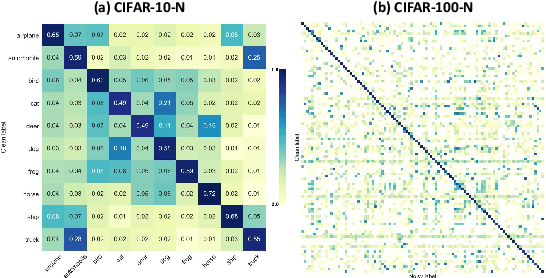
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
FedPCA: Noise-Robust Fair Federated Learning via Performance-Capacity Analysis
Mar 13, 2025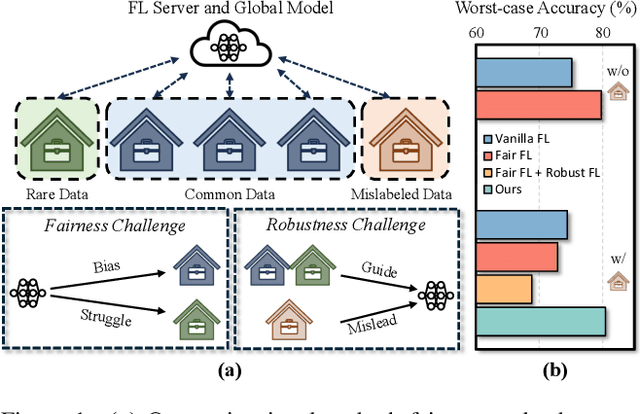

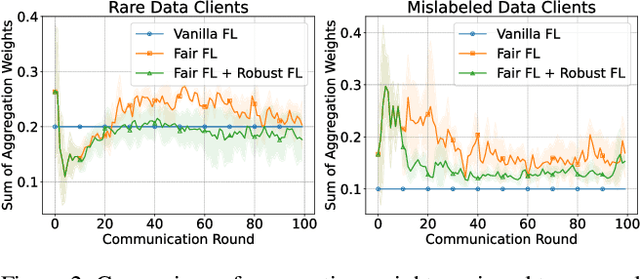
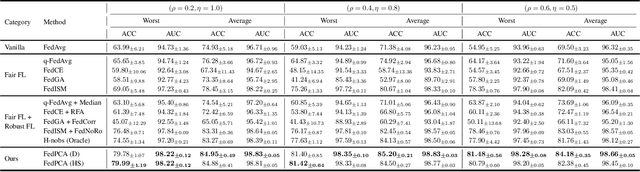
Training a model that effectively handles both common and rare data-i.e., achieving performance fairness-is crucial in federated learning (FL). While existing fair FL methods have shown effectiveness, they remain vulnerable to mislabeled data. Ensuring robustness in fair FL is therefore essential. However, fairness and robustness inherently compete, which causes robust strategies to hinder fairness. In this paper, we attribute this competition to the homogeneity in loss patterns exhibited by rare and mislabeled data clients, preventing existing loss-based fair and robust FL methods from effectively distinguishing and handling these two distinct client types. To address this, we propose performance-capacity analysis, which jointly considers model performance on each client and its capacity to handle the dataset, measured by loss and a newly introduced feature dispersion score. This allows mislabeled clients to be identified by their significantly deviated performance relative to capacity while preserving rare data clients. Building on this, we introduce FedPCA, an FL method that robustly achieves fairness. FedPCA first identifies mislabeled clients via a Gaussian Mixture Model on loss-dispersion pairs, then applies fairness and robustness strategies in global aggregation and local training by adjusting client weights and selectively using reliable data. Extensive experiments on three datasets demonstrate FedPCA's effectiveness in tackling this complex challenge. Code will be publicly available upon acceptance.
Fair Federated Medical Image Classification Against Quality Shift via Inter-Client Progressive State Matching
Mar 12, 2025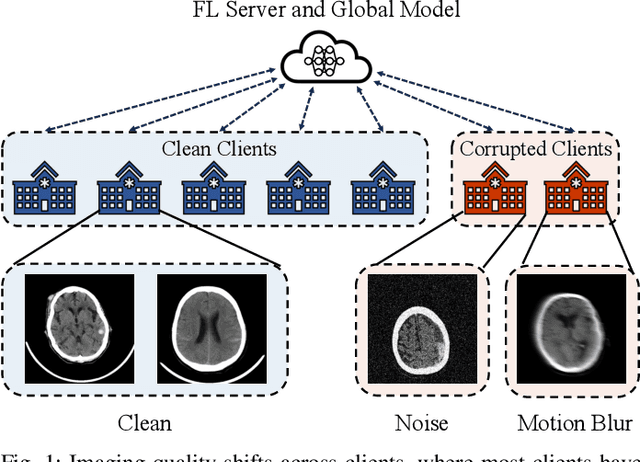
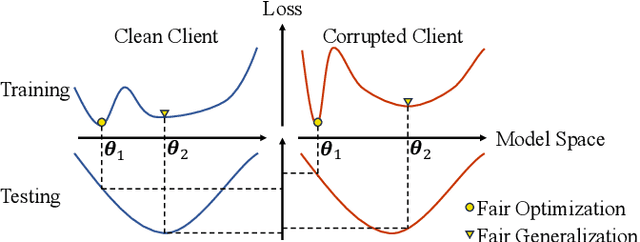
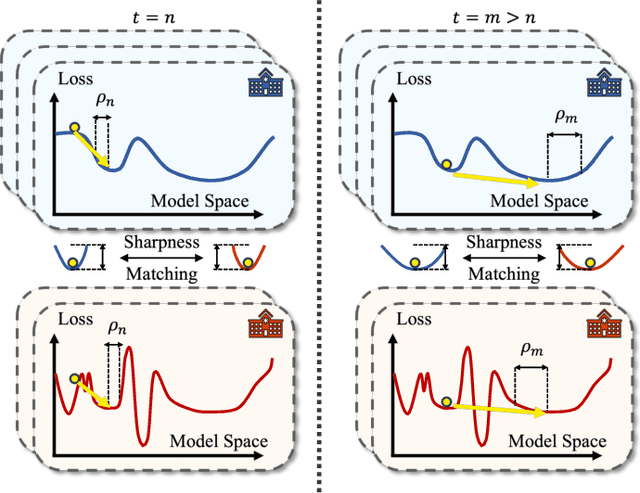
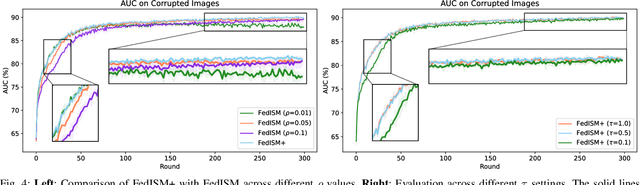
Despite the potential of federated learning in medical applications, inconsistent imaging quality across institutions-stemming from lower-quality data from a minority of clients-biases federated models toward more common high-quality images. This raises significant fairness concerns. Existing fair federated learning methods have demonstrated some effectiveness in solving this problem by aligning a single 0th- or 1st-order state of convergence (e.g., training loss or sharpness). However, we argue in this work that fairness based on such a single state is still not an adequate surrogate for fairness during testing, as these single metrics fail to fully capture the convergence characteristics, making them suboptimal for guiding fair learning. To address this limitation, we develop a generalized framework. Specifically, we propose assessing convergence using multiple states, defined as sharpness or perturbed loss computed at varying search distances. Building on this comprehensive assessment, we propose promoting fairness for these states across clients to achieve our ultimate fairness objective. This is accomplished through the proposed method, FedISM+. In FedISM+, the search distance evolves over time, progressively focusing on different states. We then incorporate two components in local training and global aggregation to ensure cross-client fairness for each state. This gradually makes convergence equitable for all states, thereby improving fairness during testing. Our empirical evaluations, performed on the well-known RSNA ICH and ISIC 2019 datasets, demonstrate the superiority of FedISM+ over existing state-of-the-art methods for fair federated learning. The code is available at https://github.com/wnn2000/FFL4MIA.
FedIA: Federated Medical Image Segmentation with Heterogeneous Annotation Completeness
Jul 02, 2024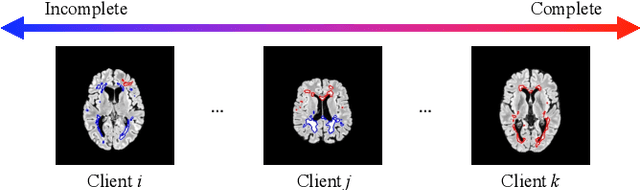


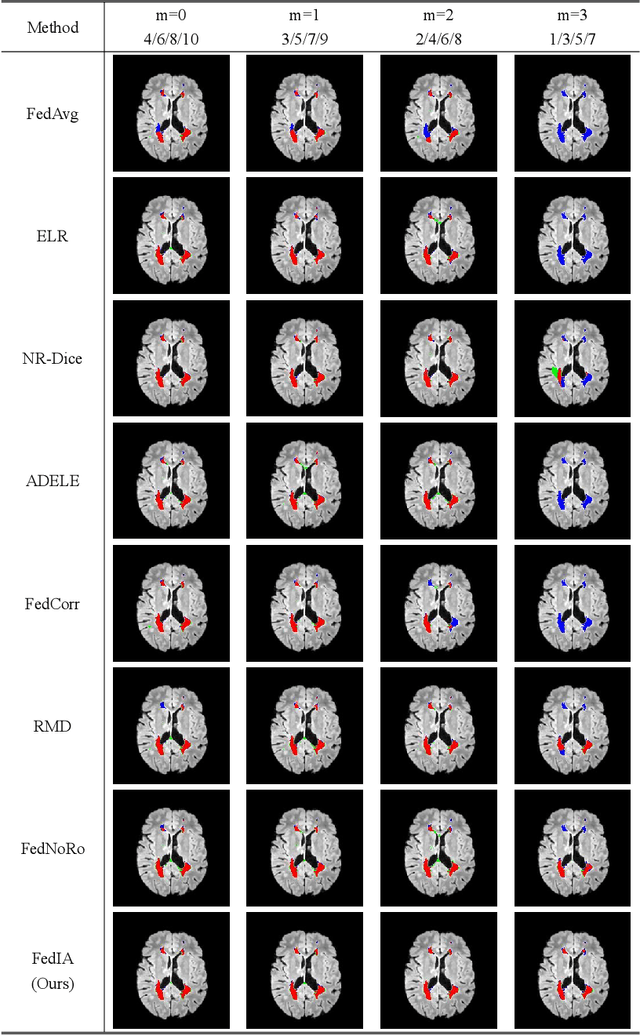
Federated learning has emerged as a compelling paradigm for medical image segmentation, particularly in light of increasing privacy concerns. However, most of the existing research relies on relatively stringent assumptions regarding the uniformity and completeness of annotations across clients. Contrary to this, this paper highlights a prevalent challenge in medical practice: incomplete annotations. Such annotations can introduce incorrectly labeled pixels, potentially undermining the performance of neural networks in supervised learning. To tackle this issue, we introduce a novel solution, named FedIA. Our insight is to conceptualize incomplete annotations as noisy data (\textit{i.e.}, low-quality data), with a focus on mitigating their adverse effects. We begin by evaluating the completeness of annotations at the client level using a designed indicator. Subsequently, we enhance the influence of clients with more comprehensive annotations and implement corrections for incomplete ones, thereby ensuring that models are trained on accurate data. Our method's effectiveness is validated through its superior performance on two extensively used medical image segmentation datasets, outperforming existing solutions. The code is available at https://github.com/HUSTxyy/FedIA.
FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity
Jun 27, 2024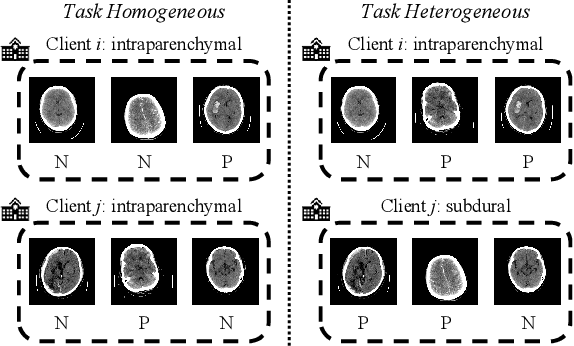
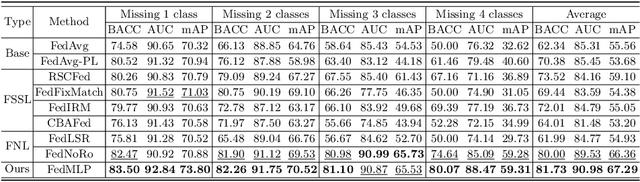
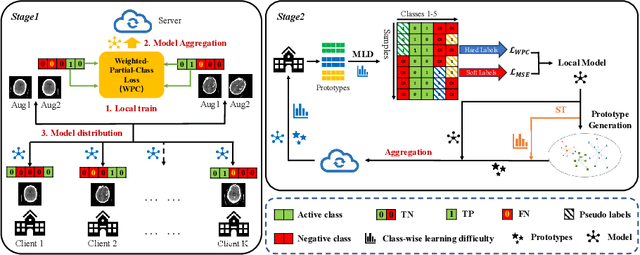
Cross-silo federated learning (FL) enables decentralized organizations to collaboratively train models while preserving data privacy and has made significant progress in medical image classification. One common assumption is task homogeneity where each client has access to all classes during training. However, in clinical practice, given a multi-label classification task, constrained by the level of medical knowledge and the prevalence of diseases, each institution may diagnose only partial categories, resulting in task heterogeneity. How to pursue effective multi-label medical image classification under task heterogeneity is under-explored. In this paper, we first formulate such a realistic label missing setting in the multi-label FL domain and propose a two-stage method FedMLP to combat class missing from two aspects: pseudo label tagging and global knowledge learning. The former utilizes a warmed-up model to generate class prototypes and select samples with high confidence to supplement missing labels, while the latter uses a global model as a teacher for consistency regularization to prevent forgetting missing class knowledge. Experiments on two publicly-available medical datasets validate the superiority of FedMLP against the state-of-the-art both federated semi-supervised and noisy label learning approaches under task heterogeneity. Code is available at https://github.com/szbonaldo/FedMLP.
From Optimization to Generalization: Fair Federated Learning against Quality Shift via Inter-Client Sharpness Matching
Apr 27, 2024
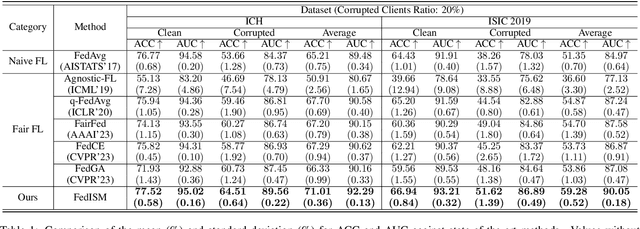


Due to escalating privacy concerns, federated learning has been recognized as a vital approach for training deep neural networks with decentralized medical data. In practice, it is challenging to ensure consistent imaging quality across various institutions, often attributed to equipment malfunctions affecting a minority of clients. This imbalance in image quality can cause the federated model to develop an inherent bias towards higher-quality images, thus posing a severe fairness issue. In this study, we pioneer the identification and formulation of this new fairness challenge within the context of the imaging quality shift. Traditional methods for promoting fairness in federated learning predominantly focus on balancing empirical risks across diverse client distributions. This strategy primarily facilitates fair optimization across different training data distributions, yet neglects the crucial aspect of generalization. To address this, we introduce a solution termed Federated learning with Inter-client Sharpness Matching (FedISM). FedISM enhances both local training and global aggregation by incorporating sharpness-awareness, aiming to harmonize the sharpness levels across clients for fair generalization. Our empirical evaluations, conducted using the widely-used ICH and ISIC 2019 datasets, establish FedISM's superiority over current state-of-the-art federated learning methods in promoting fairness. Code is available at https://github.com/wnn2000/FFL4MIA.
FedA3I: Annotation Quality-Aware Aggregation for Federated Medical Image Segmentation Against Heterogeneous Annotation Noise
Dec 20, 2023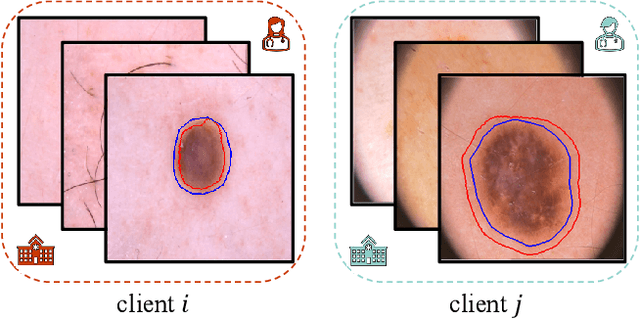

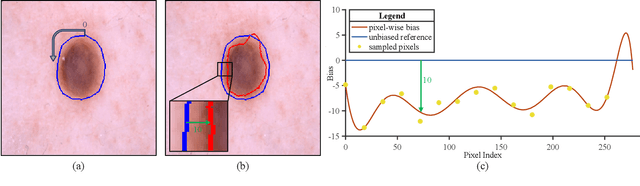
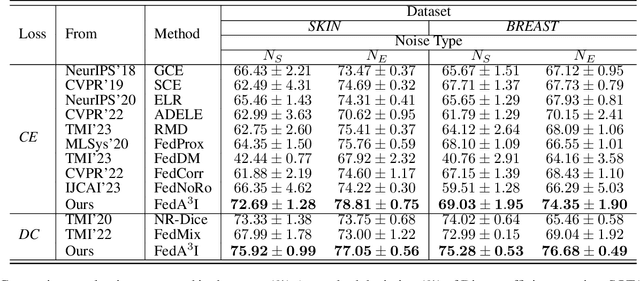
Federated learning (FL) has emerged as a promising paradigm for training segmentation models on decentralized medical data, owing to its privacy-preserving property. However, existing research overlooks the prevalent annotation noise encountered in real-world medical datasets, which limits the performance ceilings of FL. In this paper, we, for the first time, identify and tackle this problem. For problem formulation, we propose a contour evolution for modeling non-independent and identically distributed (Non-IID) noise across pixels within each client and then extend it to the case of multi-source data to form a heterogeneous noise model (\textit{i.e.}, Non-IID annotation noise across clients). For robust learning from annotations with such two-level Non-IID noise, we emphasize the importance of data quality in model aggregation, allowing high-quality clients to have a greater impact on FL. To achieve this, we propose \textbf{Fed}erated learning with \textbf{A}nnotation qu\textbf{A}lity-aware \textbf{A}ggregat\textbf{I}on, named \textbf{FedA$^3$I}, by introducing a quality factor based on client-wise noise estimation. Specifically, noise estimation at each client is accomplished through the Gaussian mixture model and then incorporated into model aggregation in a layer-wise manner to up-weight high-quality clients. Extensive experiments on two real-world medical image segmentation datasets demonstrate the superior performance of FedA$^3$I against the state-of-the-art approaches in dealing with cross-client annotation noise. The code is available at \color{blue}{https://github.com/wnn2000/FedAAAI}.
FedNoRo: Towards Noise-Robust Federated Learning by Addressing Class Imbalance and Label Noise Heterogeneity
May 09, 2023

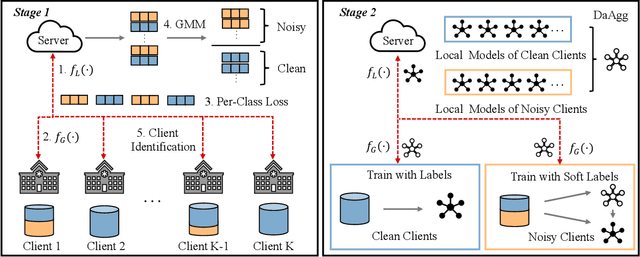

Federated noisy label learning (FNLL) is emerging as a promising tool for privacy-preserving multi-source decentralized learning. Existing research, relying on the assumption of class-balanced global data, might be incapable to model complicated label noise, especially in medical scenarios. In this paper, we first formulate a new and more realistic federated label noise problem where global data is class-imbalanced and label noise is heterogeneous, and then propose a two-stage framework named FedNoRo for noise-robust federated learning. Specifically, in the first stage of FedNoRo, per-class loss indicators followed by Gaussian Mixture Model are deployed for noisy client identification. In the second stage, knowledge distillation and a distance-aware aggregation function are jointly adopted for noise-robust federated model updating. Experimental results on the widely-used ICH and ISIC2019 datasets demonstrate the superiority of FedNoRo against the state-of-the-art FNLL methods for addressing class imbalance and label noise heterogeneity in real-world FL scenarios.
FedRare: Federated Learning with Intra- and Inter-Client Contrast for Effective Rare Disease Classification
Jun 28, 2022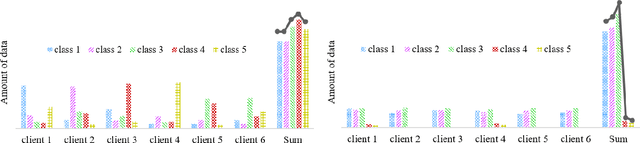

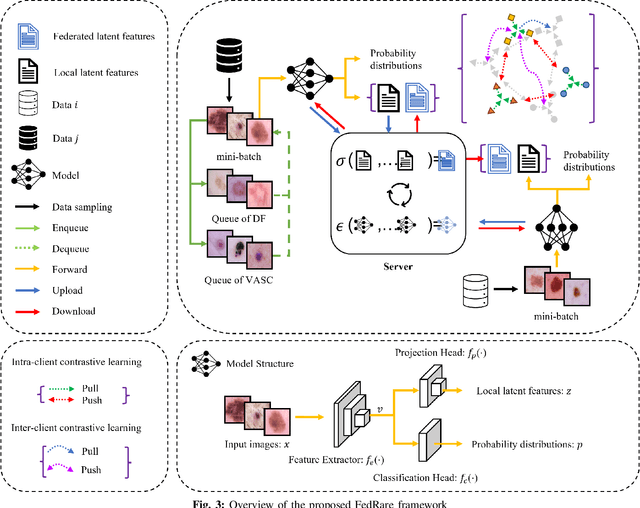

Federated learning (FL), enabling different medical institutions or clients to train a model collaboratively without data privacy leakage, has drawn great attention in medical imaging communities recently. Though inter-client data heterogeneity has been thoroughly studied, the class imbalance problem due to the existence of rare diseases still is under-explored. In this paper, we propose a novel FL framework FedRare for medical image classification especially on dealing with data heterogeneity with the existence of rare diseases. In FedRare, each client trains a model locally to extract highly-separable latent features for classification via intra-client supervised contrastive learning. Considering the limited data on rare diseases, we build positive sample queues for augmentation (i.e. data re-sampling). The server in FedRare would collect the latent features from clients and automatically select the most reliable latent features as guidance sent back to clients. Then, each client is jointly trained by an inter-client contrastive loss to align its latent features to the federated latent features of full classes. In this way, the parameter/feature variances across clients are effectively minimized, leading to better convergence and performance improvements. Experimental results on the publicly-available dataset for skin lesion diagnosis demonstrate FedRare's superior performance. Under the 10-client federated setting where four clients have no rare disease samples, FedRare achieves an average increase of 9.60% and 5.90% in balanced accuracy compared to the baseline framework FedAvg and the state-of-the-art approach FedIRM respectively. Considering the board existence of rare diseases in clinical scenarios, we believe FedRare would benefit future FL framework design for medical image classification. The source code of this paper is publicly available at https://github.com/wnn2000/FedRare.
FadMan: Federated Anomaly Detection across Multiple Attributed Networks
May 27, 2022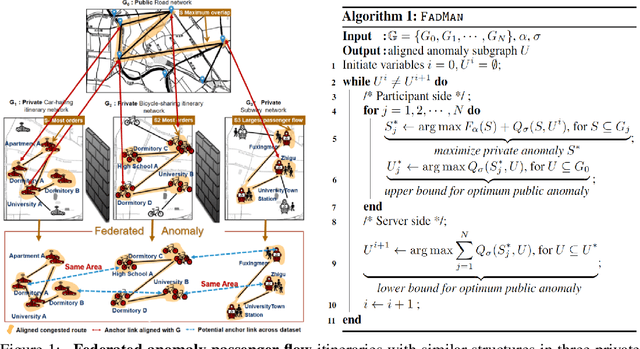
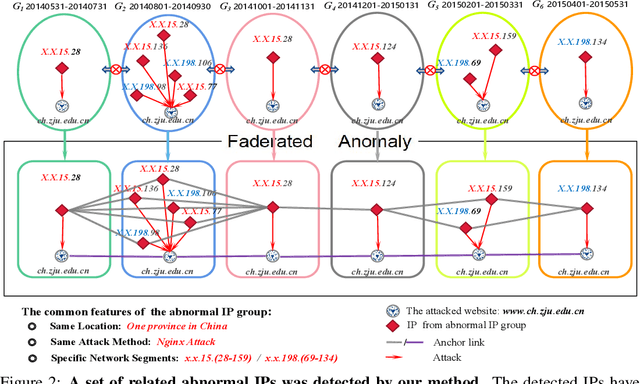
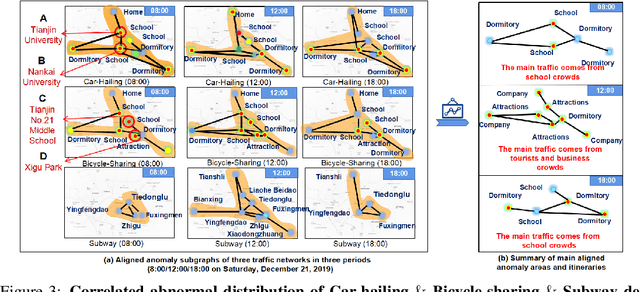
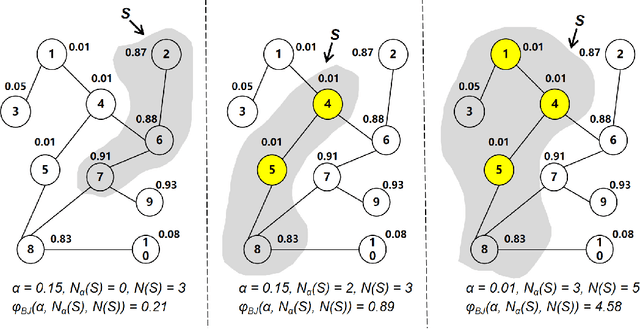
Anomaly subgraph detection has been widely used in various applications, ranging from cyber attack in computer networks to malicious activities in social networks. Despite an increasing need for federated anomaly detection across multiple attributed networks, only a limited number of approaches are available for this problem. Federated anomaly detection faces two major challenges. One is that isolated data in most industries are restricted share with others for data privacy and security. The other is most of the centralized approaches training based on data integration. The main idea of federated anomaly detection is aligning private anomalies from local data owners on the public anomalies from the attributed network in the server through public anomalies to federate local anomalies. In each private attributed network, the detected anomaly subgraph is aligned with an anomaly subgraph in the public attributed network. The significant public anomaly subgraphs are selected for federated private anomalies while preventing local private data leakage. The proposed algorithm FadMan is a vertical federated learning framework for public node aligned with many private nodes of different features, and is validated on two tasks correlated anomaly detection on multiple attributed networks and anomaly detection on an attributeless network using five real-world datasets. In the first scenario, FadMan outperforms competitive methods by at least 12% accuracy at 10% noise level. In the second scenario, by analyzing the distribution of abnormal nodes, we find that the nodes of traffic anomalies are associated with the event of postgraduate entrance examination on the same day.