 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedIA: Federated Medical Image Segmentation with Heterogeneous Annotation Completeness
Jul 02, 2024


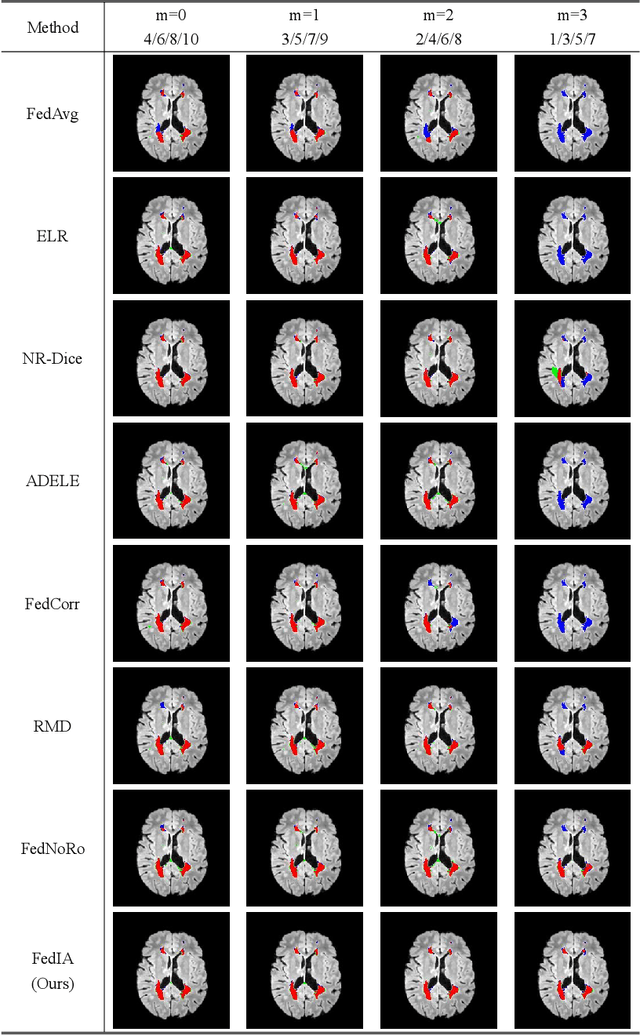
Federated learning has emerged as a compelling paradigm for medical image segmentation, particularly in light of increasing privacy concerns. However, most of the existing research relies on relatively stringent assumptions regarding the uniformity and completeness of annotations across clients. Contrary to this, this paper highlights a prevalent challenge in medical practice: incomplete annotations. Such annotations can introduce incorrectly labeled pixels, potentially undermining the performance of neural networks in supervised learning. To tackle this issue, we introduce a novel solution, named FedIA. Our insight is to conceptualize incomplete annotations as noisy data (\textit{i.e.}, low-quality data), with a focus on mitigating their adverse effects. We begin by evaluating the completeness of annotations at the client level using a designed indicator. Subsequently, we enhance the influence of clients with more comprehensive annotations and implement corrections for incomplete ones, thereby ensuring that models are trained on accurate data. Our method's effectiveness is validated through its superior performance on two extensively used medical image segmentation datasets, outperforming existing solutions. The code is available at https://github.com/HUSTxyy/FedIA.
SAMCT: Segment Any CT Allowing Labor-Free Task-Indicator Prompts
Mar 20, 2024



Segment anything model (SAM), a foundation model with superior versatility and generalization across diverse segmentation tasks, has attracted widespread attention in medical imaging. However, it has been proved that SAM would encounter severe performance degradation due to the lack of medical knowledge in training and local feature encoding. Though several SAM-based models have been proposed for tuning SAM in medical imaging, they still suffer from insufficient feature extraction and highly rely on high-quality prompts. In this paper, we construct a large CT dataset consisting of 1.1M CT images and 5M masks from public datasets and propose a powerful foundation model SAMCT allowing labor-free prompts. Specifically, based on SAM, SAMCT is further equipped with a U-shaped CNN image encoder, a cross-branch interaction module, and a task-indicator prompt encoder. The U-shaped CNN image encoder works in parallel with the ViT image encoder in SAM to supplement local features. Cross-branch interaction enhances the feature expression capability of the CNN image encoder and the ViT image encoder by exchanging global perception and local features from one to the other. The task-indicator prompt encoder is a plug-and-play component to effortlessly encode task-related indicators into prompt embeddings. In this way, SAMCT can work in an automatic manner in addition to the semi-automatic interactive strategy in SAM. Extensive experiments demonstrate the superiority of SAMCT against the state-of-the-art task-specific and SAM-based medical foundation models on various tasks. The code, data, and models are released at https://github.com/xianlin7/SAMCT.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.