 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Streaming: Accelerating Low-Batch MoE Inference via Multi-chiplet Architecture and Dynamic Expert Trajectory Scheduling
Mar 29, 2026Mixture-of-Experts is a promising approach for edge AI with low-batch inference. Yet, on-device deployments often face limited on-chip memory and severe workload imbalance; the prevalent use of offloading further incurs off-chip memory access bottlenecks. Moreover, MoE sparsity and dynamic gating shift distributed strategies toward much finer granularity and introduce runtime scheduling considerations. Recently, high die-to-die bandwidth chiplet interconnects have created new opportunities for multi-chiplet systems to address workload imbalance and offloading bottlenecks with fine-grained scheduling. In this paper, we propose Fully Sharded Expert Data Parallelism, a parallelization paradigm specifically architected for low-batch MoE inference on multi-chiplet accelerators. FSE-DP attains adaptive computation-communication overlap and balanced load by orchestrating fine-grained, complementary expert streams along dynamic trajectories across high-bandwidth D2D links. The attendant dataflow complexity is tamed by a minimal, hardware-amenable set of virtualization rules and a lightweight scheduling algorithm. Our approach achieves 1.22 to 2.00 times speedup over state-of-the-art baselines and saves up to 78.8 percent on-chip memory.
Path-Decoupled Hyperbolic Flow Matching for Few-Shot Adaptation
Feb 24, 2026Recent advances in cross-modal few-shot adaptation treat visual-semantic alignment as a continuous feature transport problem via Flow Matching (FM). However, we argue that Euclidean-based FM overlooks fundamental limitations of flat geometry, where polynomial volume growth fails to accommodate diverse feature distributions, leading to severe path entanglement. To this end, we propose path-decoupled Hyperbolic Flow Matching (HFM), leveraging the Lorentz manifold's exponential expansion for trajectory decoupling. HFM structures the transport via two key designs: 1) Centripetal hyperbolic alignment: It constructs a centripetal hierarchy by anchoring textual roots, which pushes visual leaves to the boundary to initialize orderly flows. 2) Path-decoupled objective: It acts as a ``semantic guardrail'' rigidly confining trajectories within isolated class-specific geodesic corridors via step-wise supervision. Furthermore, we devise an adaptive diameter-based stopping to prevent over-transportation into the crowded origin based on the intrinsic semantic scale. Extensive ablations on 11 benchmarks have shown that HFM establishes a new state-of-the-art, consistently outperforming its Euclidean counterparts. Our codes and models will be released.
A Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Feb 15, 2026Pathology foundation models (PFMs) have enabled robust generalization in computational pathology through large-scale datasets and expansive architectures, but their substantial computational cost, particularly for gigapixel whole slide images, limits clinical accessibility and scalability. Here, we present LitePath, a deployment-friendly foundational framework designed to mitigate model over-parameterization and patch level redundancy. LitePath integrates LiteFM, a compact model distilled from three large PFMs (Virchow2, H-Optimus-1 and UNI2) using 190 million patches, and the Adaptive Patch Selector (APS), a lightweight component for task-specific patch selection. The framework reduces model parameters by 28x and lowers FLOPs by 403.5x relative to Virchow2, enabling deployment on low-power edge hardware such as the NVIDIA Jetson Orin Nano Super. On this device, LitePath processes 208 slides per hour, 104.5x faster than Virchow2, and consumes 0.36 kWh per 3,000 slides, 171x lower than Virchow2 on an RTX3090 GPU. We validated accuracy using 37 cohorts across four organs and 26 tasks (26 internal, 9 external, and 2 prospective), comprising 15,672 slides from 9,808 patients disjoint from the pretraining data. LitePath ranks second among 19 evaluated models and outperforms larger models including H-Optimus-1, mSTAR, UNI2 and GPFM, while retaining 99.71% of the AUC of Virchow2 on average. To quantify the balance between accuracy and efficiency, we propose the Deployability Score (D-Score), defined as the weighted geometric mean of normalized AUC and normalized FLOP, where LitePath achieves the highest value, surpassing Virchow2 by 10.64%. These results demonstrate that LitePath enables rapid, cost-effective and energy-efficient pathology image analysis on accessible hardware while maintaining accuracy comparable to state-of-the-art PFMs and reducing the carbon footprint of AI deployment.
A Study of Finetuning Video Transformers for Multi-view Geometry Tasks
Dec 21, 2025This paper presents an investigation of vision transformer learning for multi-view geometry tasks, such as optical flow estimation, by fine-tuning video foundation models. Unlike previous methods that involve custom architectural designs and task-specific pretraining, our research finds that general-purpose models pretrained on videos can be readily transferred to multi-view problems with minimal adaptation. The core insight is that general-purpose attention between patches learns temporal and spatial information for geometric reasoning. We demonstrate that appending a linear decoder to the Transformer backbone produces satisfactory results, and iterative refinement can further elevate performance to stateof-the-art levels. This conceptually simple approach achieves top cross-dataset generalization results for optical flow estimation with end-point error (EPE) of 0.69, 1.78, and 3.15 on the Sintel clean, Sintel final, and KITTI datasets, respectively. Our method additionally establishes a new record on the online test benchmark with EPE values of 0.79, 1.88, and F1 value of 3.79. Applications to 3D depth estimation and stereo matching also show strong performance, illustrating the versatility of video-pretrained models in addressing geometric vision tasks.
A 28nm 0.22 μJ/token memory-compute-intensity-aware CNN-Transformer accelerator with hybrid-attention-based layer-fusion and cascaded pruning for semanticsegmentation
Dec 19, 2025This work presents a 28nm 13.93mm2 CNN-Transformer accelerator for semantic segmentation, achieving 3.86-to-10.91x energy reduction over previous designs. It features a hybrid attention unit, layer-fusion scheduler, and cascaded feature-map pruner, with peak energy efficiency of 52.90TOPS/W (INT8).
* 3 pages,7 pages, 2025 IEEE International Solid-State Circuits Conference (ISSCC)
SR-LIO++: Efficient LiDAR-Inertial Odometry and Quantized Mapping with Sweep Reconstruction
Mar 29, 2025Addressing the inherent low acquisition frequency limitation of 3D LiDAR to achieve high-frequency output has become a critical research focus in the LiDAR-Inertial Odometry (LIO) domain. To ensure real-time performance, frequency-enhanced LIO systems must process each sweep within significantly reduced timeframe, which presents substantial challenges for deployment on low-computational-power platforms. To address these limitations, we introduce SR-LIO++, an innovative LIO system capable of achieving doubled output frequency relative to input frequency on resource-constrained hardware platforms, including the Raspberry Pi 4B. Our system employs a sweep reconstruction methodology to enhance LiDAR sweep frequency, generating high-frequency reconstructed sweeps. Building upon this foundation, we propose a caching mechanism for intermediate results (i.e., surface parameters) of the most recent segments, effectively minimizing redundant processing of common segments in adjacent reconstructed sweeps. This method decouples processing time from the traditionally linear dependence on reconstructed sweep frequency. Furthermore, we present a quantized map point management based on index table mapping, significantly reducing memory usage by converting global 3D point storage from 64-bit double precision to 8-bit char representation. This method also converts the computationally intensive Euclidean distance calculations in nearest neighbor searches from 64-bit double precision to 16-bit short and 32-bit integer formats, significantly reducing both memory and computational cost. Extensive experimental evaluations across three distinct computing platforms and four public datasets demonstrate that SR-LIO++ maintains state-of-the-art accuracy while substantially enhancing efficiency. Notably, our system successfully achieves 20Hz state output on Raspberry Pi 4B hardware.
Memory Efficient Transformer Adapter for Dense Predictions
Feb 04, 2025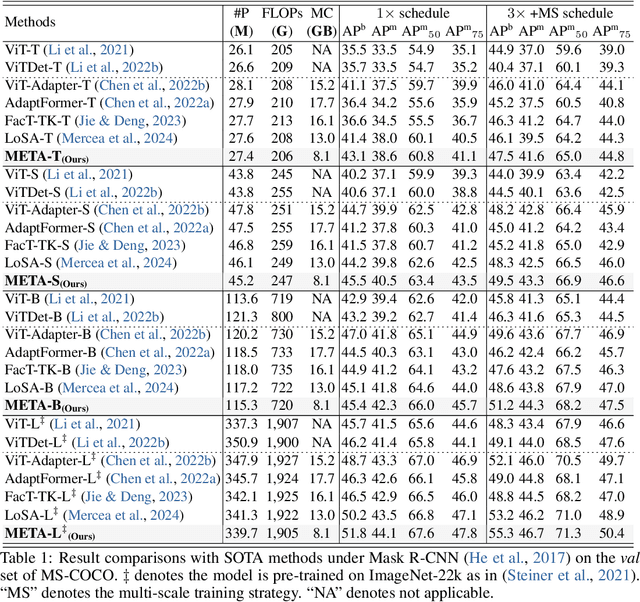
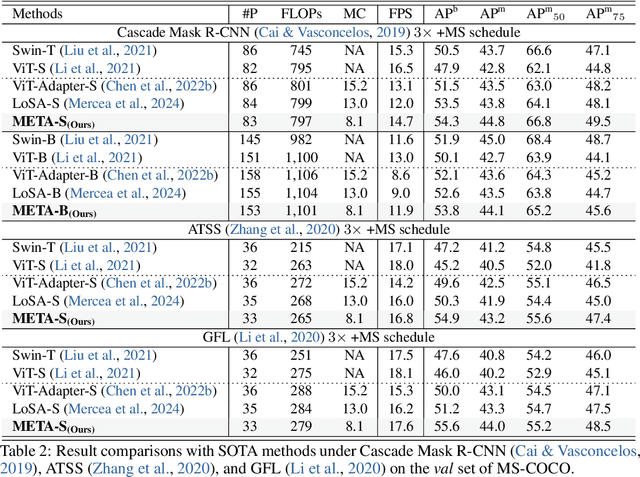
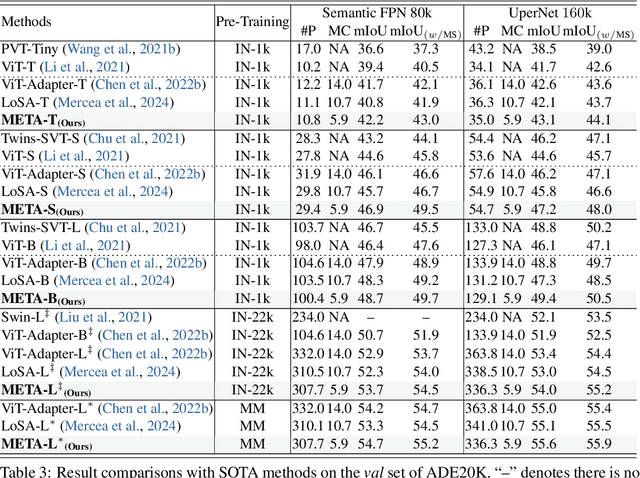
While current Vision Transformer (ViT) adapter methods have shown promising accuracy, their inference speed is implicitly hindered by inefficient memory access operations, e.g., standard normalization and frequent reshaping. In this work, we propose META, a simple and fast ViT adapter that can improve the model's memory efficiency and decrease memory time consumption by reducing the inefficient memory access operations. Our method features a memory-efficient adapter block that enables the common sharing of layer normalization between the self-attention and feed-forward network layers, thereby reducing the model's reliance on normalization operations. Within the proposed block, the cross-shaped self-attention is employed to reduce the model's frequent reshaping operations. Moreover, we augment the adapter block with a lightweight convolutional branch that can enhance local inductive biases, particularly beneficial for the dense prediction tasks, e.g., object detection, instance segmentation, and semantic segmentation. The adapter block is finally formulated in a cascaded manner to compute diverse head features, thereby enriching the variety of feature representations. Empirically, extensive evaluations on multiple representative datasets validate that META substantially enhances the predicted quality, while achieving a new state-of-the-art accuracy-efficiency trade-off. Theoretically, we demonstrate that META exhibits superior generalization capability and stronger adaptability.
Generalized Task-Driven Medical Image Quality Enhancement with Gradient Promotion
Jan 02, 2025



Thanks to the recent achievements in task-driven image quality enhancement (IQE) models like ESTR, the image enhancement model and the visual recognition model can mutually enhance each other's quantitation while producing high-quality processed images that are perceivable by our human vision systems. However, existing task-driven IQE models tend to overlook an underlying fact -- different levels of vision tasks have varying and sometimes conflicting requirements of image features. To address this problem, this paper proposes a generalized gradient promotion (GradProm) training strategy for task-driven IQE of medical images. Specifically, we partition a task-driven IQE system into two sub-models, i.e., a mainstream model for image enhancement and an auxiliary model for visual recognition. During training, GradProm updates only parameters of the image enhancement model using gradients of the visual recognition model and the image enhancement model, but only when gradients of these two sub-models are aligned in the same direction, which is measured by their cosine similarity. In case gradients of these two sub-models are not in the same direction, GradProm only uses the gradient of the image enhancement model to update its parameters. Theoretically, we have proved that the optimization direction of the image enhancement model will not be biased by the auxiliary visual recognition model under the implementation of GradProm. Empirically, extensive experimental results on four public yet challenging medical image datasets demonstrated the superior performance of GradProm over existing state-of-the-art methods.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
Oct 28, 2024In this work, we re-formulate the model compression problem into the customized compensation problem: Given a compressed model, we aim to introduce residual low-rank paths to compensate for compression errors under customized requirements from users (e.g., tasks, compression ratios), resulting in greater flexibility in adjusting overall capacity without being constrained by specific compression formats. However, naively applying SVD to derive residual paths causes suboptimal utilization of the low-rank representation capacity. Instead, we propose Training-free Eigenspace Low-Rank Approximation (EoRA), a method that directly minimizes compression-induced errors without requiring gradient-based training, achieving fast optimization in minutes using a small amount of calibration data. EoRA projects compression errors into the eigenspace of input activations, leveraging eigenvalues to effectively prioritize the reconstruction of high-importance error components. Moreover, EoRA can be seamlessly integrated with fine-tuning and quantization to further improve effectiveness and efficiency. EoRA consistently outperforms previous methods in compensating errors for compressed LLaMA2/3 models on various tasks, such as language generation, commonsense reasoning, and math reasoning tasks (e.g., 31.31%/12.88% and 9.69% improvements on ARC-Easy/ARC-Challenge and MathQA when compensating LLaMA3-8B that is quantized to 4-bit and pruned to 2:4 sparsity). EoRA offers a scalable, training-free solution to compensate for compression errors, making it a powerful tool to deploy LLMs in various capacity and efficiency requirements.