 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjection-Free Evolution Strategies for Continuous Prompt Search
Mar 14, 2026Continuous prompt search offers a computationally efficient alternative to conventional parameter tuning in natural language processing tasks. Nevertheless, its practical effectiveness can be significantly hindered by the black-box nature and the inherent high-dimensionality of the objective landscapes. Existing methods typically mitigate these challenges by restricting the search to a randomly projected low-dimensional subspace. However, the effectiveness and underlying motivation of the projection mechanism remain ambiguous. In this paper, we first empirically demonstrate that despite the prompt space possessing a low-dimensional structure, random projections fail to adequately capture this essential structure. Motivated by this finding, we propose a projection-free prompt search method based on evolutionary strategies. By directly optimizing in the full prompt space with an adaptation mechanism calibrated to the intrinsic dimension, our method achieves competitive search capabilities without additional computational overhead. Furthermore, to bridge the generalization gap in few-shot scenarios, we introduce a confidence-based regularization mechanism that systematically enhances the model's confidence in the target verbalizers. Experimental results on seven natural language understanding tasks from the GLUE benchmark demonstrate that our proposed approach significantly outperforms existing baselines.
A Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Feb 15, 2026Pathology foundation models (PFMs) have enabled robust generalization in computational pathology through large-scale datasets and expansive architectures, but their substantial computational cost, particularly for gigapixel whole slide images, limits clinical accessibility and scalability. Here, we present LitePath, a deployment-friendly foundational framework designed to mitigate model over-parameterization and patch level redundancy. LitePath integrates LiteFM, a compact model distilled from three large PFMs (Virchow2, H-Optimus-1 and UNI2) using 190 million patches, and the Adaptive Patch Selector (APS), a lightweight component for task-specific patch selection. The framework reduces model parameters by 28x and lowers FLOPs by 403.5x relative to Virchow2, enabling deployment on low-power edge hardware such as the NVIDIA Jetson Orin Nano Super. On this device, LitePath processes 208 slides per hour, 104.5x faster than Virchow2, and consumes 0.36 kWh per 3,000 slides, 171x lower than Virchow2 on an RTX3090 GPU. We validated accuracy using 37 cohorts across four organs and 26 tasks (26 internal, 9 external, and 2 prospective), comprising 15,672 slides from 9,808 patients disjoint from the pretraining data. LitePath ranks second among 19 evaluated models and outperforms larger models including H-Optimus-1, mSTAR, UNI2 and GPFM, while retaining 99.71% of the AUC of Virchow2 on average. To quantify the balance between accuracy and efficiency, we propose the Deployability Score (D-Score), defined as the weighted geometric mean of normalized AUC and normalized FLOP, where LitePath achieves the highest value, surpassing Virchow2 by 10.64%. These results demonstrate that LitePath enables rapid, cost-effective and energy-efficient pathology image analysis on accessible hardware while maintaining accuracy comparable to state-of-the-art PFMs and reducing the carbon footprint of AI deployment.
Alada: Alternating Adaptation of Momentum Method for Memory-Efficient Matrix Optimization
Dec 15, 2025This work proposes Alada, an adaptive momentum method for stochastic optimization over large-scale matrices. Alada employs a rank-one factorization approach to estimate the second moment of gradients, where factors are updated alternatively to minimize the estimation error. Alada achieves sublinear memory overheads and can be readily extended to optimizing tensor-shaped variables.We also equip Alada with a first moment estimation rule, which enhances the algorithm's robustness without incurring additional memory overheads. The theoretical performance of Alada aligns with that of traditional methods such as Adam. Numerical studies conducted on several natural language processing tasks demonstrate the reduction in memory overheads and the robustness in training large models relative to Adam and its variants.
Symmetric observations without symmetric causal explanations
Feb 20, 2025



Inferring causal models from observed correlations is a challenging task, crucial to many areas of science. In order to alleviate the effort, it is important to know whether symmetries in the observations correspond to symmetries in the underlying realization. Via an explicit example, we answer this question in the negative. We use a tripartite probability distribution over binary events that is realized by using three (different) independent sources of classical randomness. We prove that even removing the condition that the sources distribute systems described by classical physics, the requirements that i) the sources distribute the same physical systems, ii) these physical systems respect relativistic causality, and iii) the correlations are the observed ones, are incompatible.
PRTGS: Precomputed Radiance Transfer of Gaussian Splats for Real-Time High-Quality Relighting
Aug 07, 2024We proposed Precomputed RadianceTransfer of GaussianSplats (PRTGS), a real-time high-quality relighting method for Gaussian splats in low-frequency lighting environments that captures soft shadows and interreflections by precomputing 3D Gaussian splats' radiance transfer. Existing studies have demonstrated that 3D Gaussian splatting (3DGS) outperforms neural fields' efficiency for dynamic lighting scenarios. However, the current relighting method based on 3DGS still struggles to compute high-quality shadow and indirect illumination in real time for dynamic light, leading to unrealistic rendering results. We solve this problem by precomputing the expensive transport simulations required for complex transfer functions like shadowing, the resulting transfer functions are represented as dense sets of vectors or matrices for every Gaussian splat. We introduce distinct precomputing methods tailored for training and rendering stages, along with unique ray tracing and indirect lighting precomputation techniques for 3D Gaussian splats to accelerate training speed and compute accurate indirect lighting related to environment light. Experimental analyses demonstrate that our approach achieves state-of-the-art visual quality while maintaining competitive training times and allows high-quality real-time (30+ fps) relighting for dynamic light and relatively complex scenes at 1080p resolution.
Towards A Generalizable Pathology Foundation Model via Unified Knowledge Distillation
Jul 26, 2024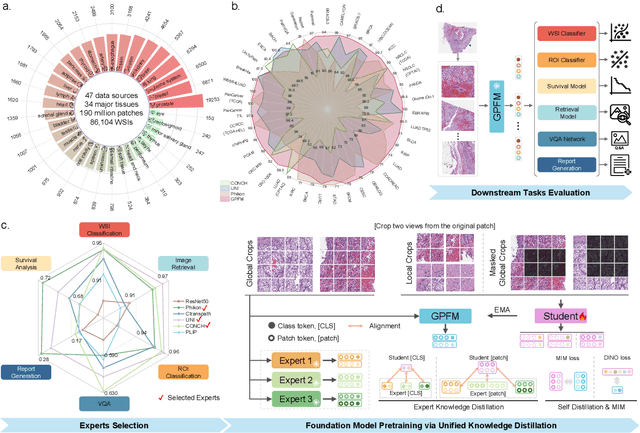

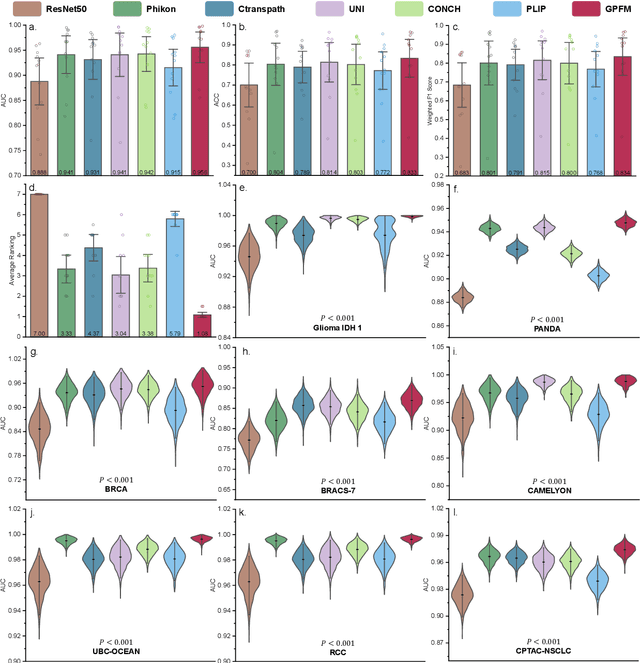
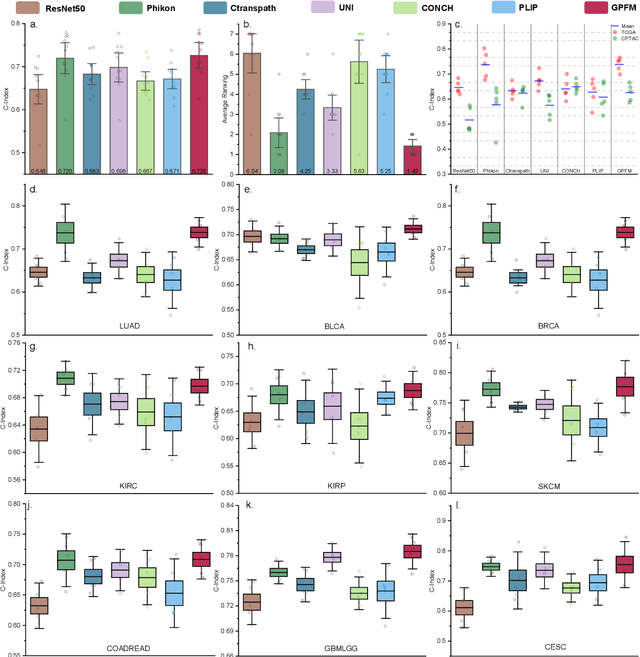
Foundation models pretrained on large-scale datasets are revolutionizing the field of computational pathology (CPath). The generalization ability of foundation models is crucial for the success in various downstream clinical tasks. However, current foundation models have only been evaluated on a limited type and number of tasks, leaving their generalization ability and overall performance unclear. To address this gap, we established a most comprehensive benchmark to evaluate the performance of off-the-shelf foundation models across six distinct clinical task types, encompassing a total of 39 specific tasks. Our findings reveal that existing foundation models excel at certain task types but struggle to effectively handle the full breadth of clinical tasks. To improve the generalization of pathology foundation models, we propose a unified knowledge distillation framework consisting of both expert and self knowledge distillation, where the former allows the model to learn from the knowledge of multiple expert models, while the latter leverages self-distillation to enable image representation learning via local-global alignment. Based on this framework, a Generalizable Pathology Foundation Model (GPFM) is pretrained on a large-scale dataset consisting of 190 million images from around 86,000 public H\&E whole slides across 34 major tissue types. Evaluated on the established benchmark, GPFM achieves an impressive average rank of 1.36, with 29 tasks ranked 1st, while the the second-best model, UNI, attains an average rank of 2.96, with only 4 tasks ranked 1st. The superior generalization of GPFM demonstrates its exceptional modeling capabilities across a wide range of clinical tasks, positioning it as a new cornerstone for feature representation in CPath.
MedIAnomaly: A comparative study of anomaly detection in medical images
Apr 06, 2024


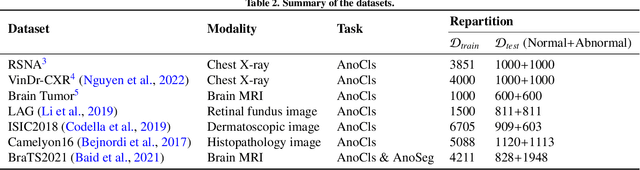
Anomaly detection (AD) aims at detecting abnormal samples that deviate from the expected normal patterns. Generally, it can be trained on merely normal data without the requirement for abnormal samples, and thereby plays an important role in the recognition of rare diseases and health screening in the medical domain. Despite numerous related studies, we observe a lack of a fair and comprehensive evaluation, which causes some ambiguous conclusions and hinders the development of this field. This paper focuses on building a benchmark with unified implementation and comparison to address this problem. In particular, seven medical datasets with five image modalities, including chest X-rays, brain MRIs, retinal fundus images, dermatoscopic images, and histopathology whole slide images are organized for extensive evaluation. Twenty-seven typical AD methods, including reconstruction and self-supervised learning-based methods, are involved in comparison of image-level anomaly classification and pixel-level anomaly segmentation. Furthermore, we for the first time formally explore the effect of key components in existing methods, clearly revealing unresolved challenges and potential future directions. The datasets and code are available at \url{https://github.com/caiyu6666/MedIAnomaly}.
Rethinking Autoencoders for Medical Anomaly Detection from A Theoretical Perspective
Mar 15, 2024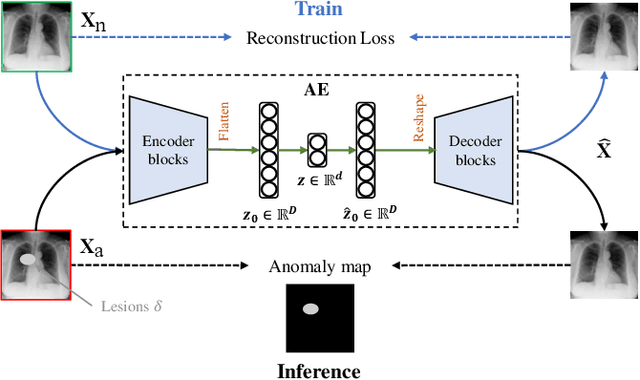
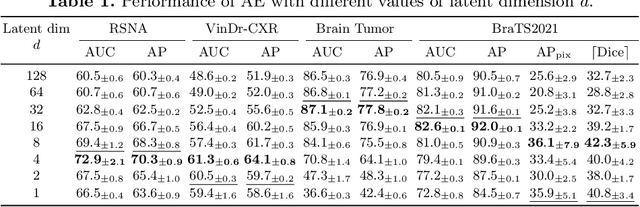
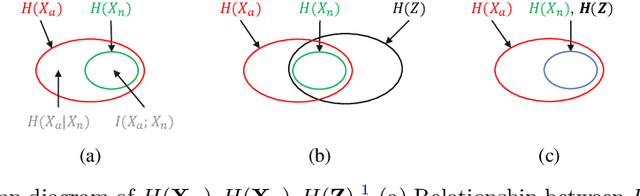
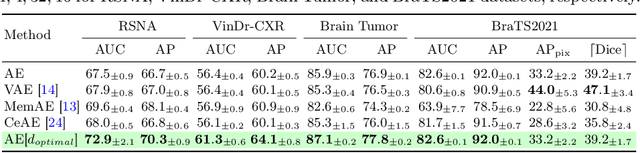
Medical anomaly detection aims to identify abnormal findings using only normal training data, playing a crucial role in health screening and recognizing rare diseases. Reconstruction-based methods, particularly those utilizing autoencoders (AEs), are dominant in this field. They work under the assumption that AEs trained on only normal data cannot reconstruct unseen abnormal regions well, thereby enabling the anomaly detection based on reconstruction errors. However, this assumption does not always hold due to the mismatch between the reconstruction training objective and the anomaly detection task objective, rendering these methods theoretically unsound. This study focuses on providing a theoretical foundation for AE-based reconstruction methods in anomaly detection. By leveraging information theory, we elucidate the principles of these methods and reveal that the key to improving AE in anomaly detection lies in minimizing the information entropy of latent vectors. Experiments on four datasets with two image modalities validate the effectiveness of our theory. To the best of our knowledge, this is the first effort to theoretically clarify the principles and design philosophy of AE for anomaly detection. Code will be available upon acceptance.
Self-Supervised Depth Completion Guided by 3D Perception and Geometry Consistency
Dec 23, 2023
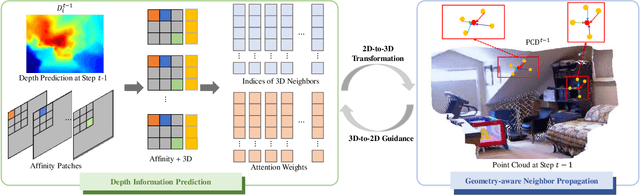


Depth completion, aiming to predict dense depth maps from sparse depth measurements, plays a crucial role in many computer vision related applications. Deep learning approaches have demonstrated overwhelming success in this task. However, high-precision depth completion without relying on the ground-truth data, which are usually costly, still remains challenging. The reason lies on the ignorance of 3D structural information in most previous unsupervised solutions, causing inaccurate spatial propagation and mixed-depth problems. To alleviate the above challenges, this paper explores the utilization of 3D perceptual features and multi-view geometry consistency to devise a high-precision self-supervised depth completion method. Firstly, a 3D perceptual spatial propagation algorithm is constructed with a point cloud representation and an attention weighting mechanism to capture more reasonable and favorable neighboring features during the iterative depth propagation process. Secondly, the multi-view geometric constraints between adjacent views are explicitly incorporated to guide the optimization of the whole depth completion model in a self-supervised manner. Extensive experiments on benchmark datasets of NYU-Depthv2 and VOID demonstrate that the proposed model achieves the state-of-the-art depth completion performance compared with other unsupervised methods, and competitive performance compared with previous supervised methods.
Dual-distribution discrepancy with self-supervised refinement for anomaly detection in medical images
Oct 09, 2022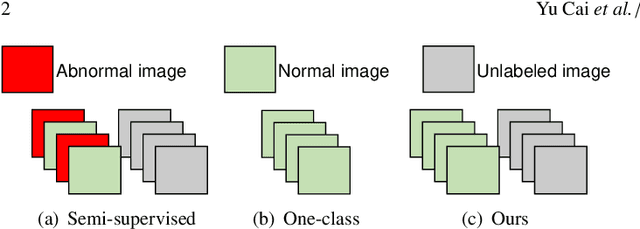

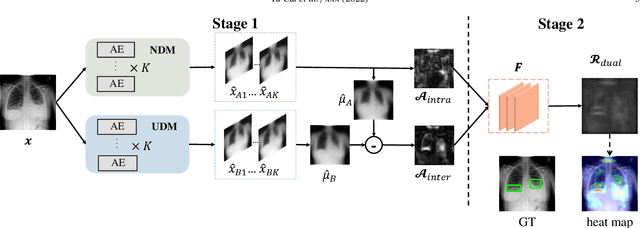
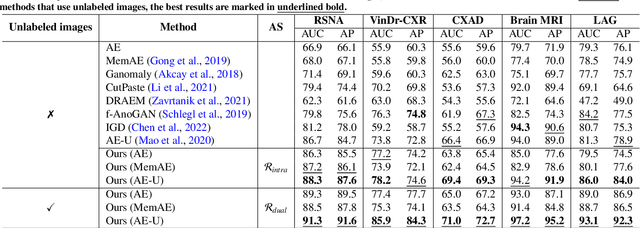
Medical anomaly detection is a crucial yet challenging task aiming at recognizing abnormal images to assist diagnosis. Due to the high-cost annotations of abnormal images, most methods utilize only known normal images during training and identify samples not conforming to the normal profile as anomalies in the testing phase. A large number of readily available unlabeled images containing anomalies are thus ignored in the training phase, restricting their performance. To solve this problem, we propose the Dual-distribution Discrepancy for Anomaly Detection (DDAD), utilizing both known normal images and unlabeled images. Two modules are designed to model the normative distribution of normal images and the unknown distribution of both normal and unlabeled images, respectively, using ensembles of reconstruction networks. Subsequently, intra-discrepancy of the normative distribution module, and inter-discrepancy between the two modules are designed as anomaly scores. Furthermore, an Anormal Score Refinement Net (ASR-Net) trained via self-supervised learning is proposed to refine the two anomaly scores. For evaluation, five medical datasets including chest X-rays, brain MRIs and retinal fundus images are organized as benchmarks. Experiments on these benchmarks demonstrate our method achieves significant gains and outperforms state-of-the-art methods. Code and organized benchmarks will be available at https://github.com/caiyu6666/DDAD-ASR