 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Calibration and Spatial-Frequency Interactive Network for STEM Image Enhancement
Apr 03, 2025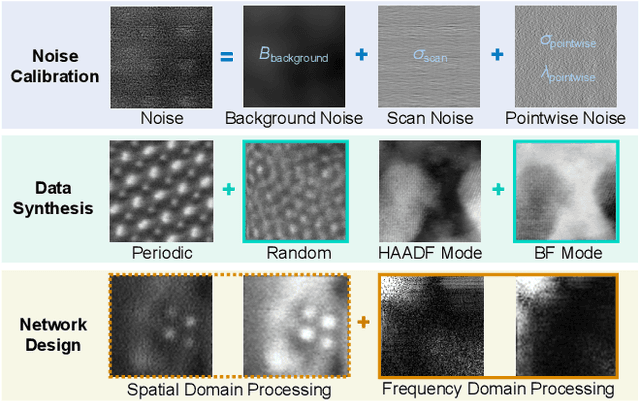



Scanning Transmission Electron Microscopy (STEM) enables the observation of atomic arrangements at sub-angstrom resolution, allowing for atomically resolved analysis of the physical and chemical properties of materials. However, due to the effects of noise, electron beam damage, sample thickness, etc, obtaining satisfactory atomic-level images is often challenging. Enhancing STEM images can reveal clearer structural details of materials. Nonetheless, existing STEM image enhancement methods usually overlook unique features in the frequency domain, and existing datasets lack realism and generality. To resolve these issues, in this paper, we develop noise calibration, data synthesis, and enhancement methods for STEM images. We first present a STEM noise calibration method, which is used to synthesize more realistic STEM images. The parameters of background noise, scan noise, and pointwise noise are obtained by statistical analysis and fitting of real STEM images containing atoms. Then we use these parameters to develop a more general dataset that considers both regular and random atomic arrangements and includes both HAADF and BF mode images. Finally, we design a spatial-frequency interactive network for STEM image enhancement, which can explore the information in the frequency domain formed by the periodicity of atomic arrangement. Experimental results show that our data is closer to real STEM images and achieves better enhancement performances together with our network. Code will be available at https://github.com/HeasonLee/SFIN}{https://github.com/HeasonLee/SFIN.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022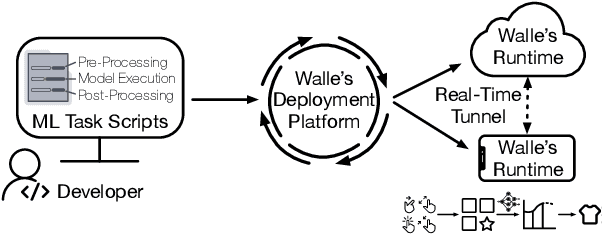
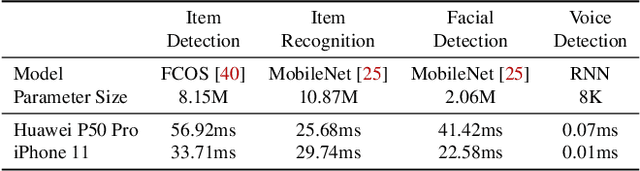
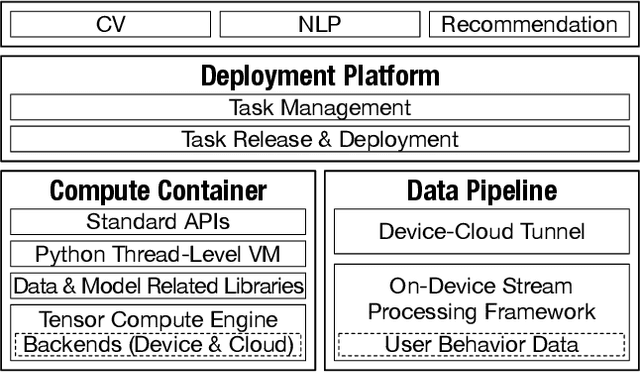

To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.
MNN: A Universal and Efficient Inference Engine
Feb 27, 2020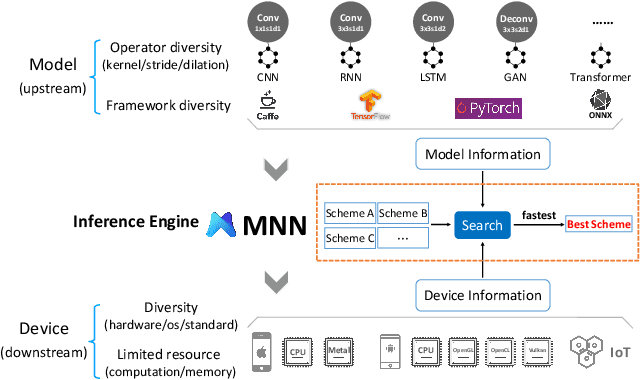
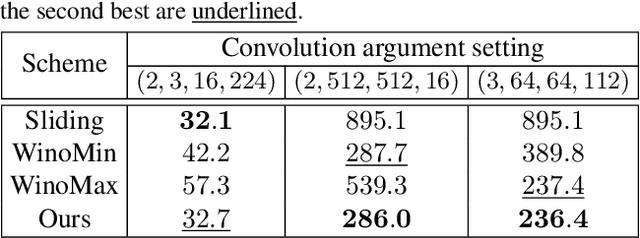
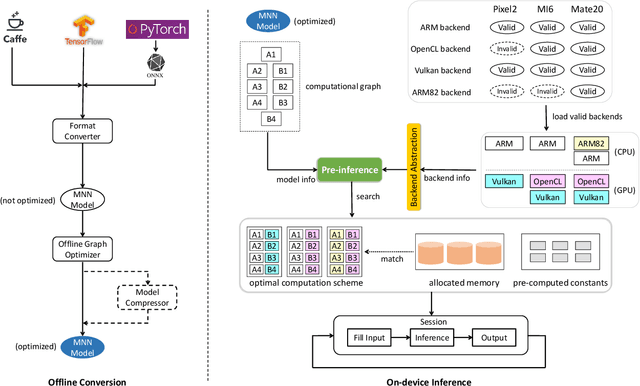
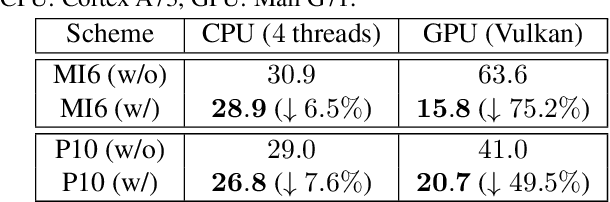
Deploying deep learning models on mobile devices draws more and more attention recently. However, designing an efficient inference engine on devices is under the great challenges of model compatibility, device diversity, and resource limitation. To deal with these challenges, we propose Mobile Neural Network (MNN), a universal and efficient inference engine tailored to mobile applications. In this paper, the contributions of MNN include: (1) presenting a mechanism called pre-inference that manages to conduct runtime optimization; (2)deliveringthorough kernel optimization on operators to achieve optimal computation performance; (3) introducing backend abstraction module which enables hybrid scheduling and keeps the engine lightweight. Extensive benchmark experiments demonstrate that MNN performs favorably against other popular lightweight deep learning frameworks. MNN is available to public at: https://github.com/alibaba/MNN.